今天总结一下正则表达式,它用来解决模糊匹配的问题,几乎在所有编程语言中都可以用,尤其在python爬虫中,它是一门必修知识;
所谓模糊匹配,就是在匹配字符串中,有一部分是确定的,另一部分是不确定的值但有范围或者任意值;
这样我们就可以用一些具有特殊含义的符号,对字符串进行另一种描述,而这些特殊含义的符号就组成一个正则表达式。
正则表达式与re模块
正则表达式也内嵌在Python中,通过re模块来实现,常用方法是findall(),会将匹配到的字符串用一个列表返回
例如: 要匹配一大串字符串中的所有数字,不用for循环和If语句,用re模块一行就能实现
import re
print(re.findall('\d+',"sadfjk11ksk22iuir33bndb44uidu55sgsfir66o77"))
运行结果:

字符匹配
普通字符匹配
import re
print(re.findall('bigbig',"Iwannaabigbigjuicecanyougiveme?"))
#findall第一个参数是需要匹配的子串或子串规则,第二个参数为母串
运行结果:

利用元字符进行模糊匹配
元字符: . ^ $ + ? {} [] | () \
- .任意字符:
import re
#匹配b开头g结尾的子串,..表示任意的两个字符,如果不是两个,那就匹配不出来
print(re.findall('b..g',"abcdefgabcdghijklmn"))
运行结果:

- ^只能为开头:
import re
#匹配b开头g结尾的子串
#^表示子串的第一个字符只能在母串的开头,..表示任意的两个字符
print(re.findall('^b..g',"bbcgefgabcdghijblmg"))
运行结果:

- $只能以结尾:
import re
#匹配b开头g结尾的子串
#$表示子串的最后一个字符只能在母串的结尾,..表示任意的两个字符
print(re.findall('b..g$',"abcdefgabcdghijblmg"))
运行结果:

重复的字符匹配
-
贪婪匹配: 即尽量多地匹配,与之相反的是惰性匹配
-
*是0到无穷个:
import re
#*表示子串的某个字符可以0到无穷次出现
print(re.findall('Wo23*Le',"sjfkufiWo233333333333333333333Le"))
运行结果:

- +是1到无穷个:
import re
#+表示子串的某个字符可以1到无穷次出现(该元素至少出现一次),..表示任意的两个字符
print(re.findall('Wo23+Le',"sjfkufiWo233333333333333333333Le"))
#与*的区别匹配
print(re.findall('Wo23*',"dsjfkjfiWo2")) #能匹配到内容
print(re.findall('Wo23+',"dsjfkjfiWo2")) #不能匹配到内容,因为3要至少要出现一次
运行结果:

- ?匹配0次到1次:
import re
#匹配b开头g结尾的子串
#?表示子串的某个字符可以出现0到1次
print(re.findall('beii?',"abcdefghibeigggjklmn")) #母串bei后面是g,不是i,所以不匹配bei后的i
print(re.findall('beig?',"abcdefghibeigggjklmn")) #母串bei后有g,就匹配1次g
运行结果:

- {}任意规定次数:
import re
#{a,b}表示子串的某个字符可以出现a到b次,同时可表现*,+,?
#{0,}==* {1,}==+ {0,1}==?
#匹配b开头g结尾的子串
print(re.findall('beig{6}',"abcdefghibeiggggggjklmn"))
#{n}没有规定范围,而只有一个参数时,表示严格执行重复n次,多了和少了都匹配不出来
运行结果:

- 在后加?变成惰性匹配
以上四个都是贪婪匹配,在 + ? {}后面加一个?就可以变成惰性*匹配(尽可能少地匹配)
import re
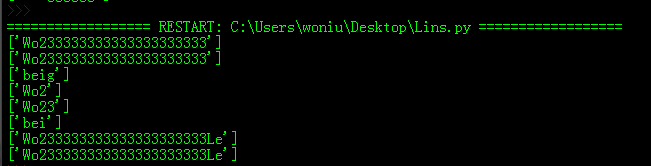
print(re.findall('Wo23*',"sjfkufiWo233333333333333333333"))
print(re.findall('Wo23+',"sjfkufiWo233333333333333333333"))
print(re.findall('beig?',"abcdefghibeigggjklmn"))
#加?变惰性匹配,最终子串中的某个字都尽量少地匹配,匹配0次即不算进子串里面
print(re.findall('Wo23*?',"sjfkufiWo233333333333333333333")) #匹配0次
print(re.findall('Wo23+?',"sjfkufiWo233333333333333333333")) #匹配1次
print(re.findall('beig??',"abcdefghibeigggjklmn")) #匹配0次
#但这样匹配加?后就没有效果了,因为末尾还有需要匹配的字符,所以不会变成懒惰
print(re.findall('Wo23*?Le',"sjfkufiWo233333333333333333333Le"))
print(re.findall('Wo23+?Le',"sjfkufiWo233333333333333333333Le"))
运行结果:
- []选择匹配:
import re
#[]表示选择[]中的一个字符进行匹配,可以当做‘或’来理解,只要母串有就可以匹配出来
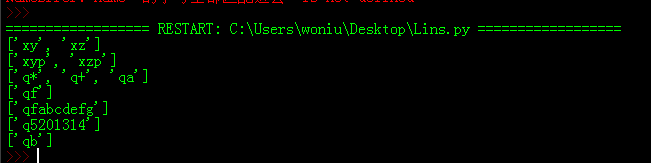
print(re.findall('x[yz]',"iiooxyjiushixzxxoo")) #匹配出xy或xz
print(re.findall('x[yz]p',"iiooxypjiushixzpxxoo")) #匹配出xyp或xzp
#[]内的*,+等元字符都当做普通字符来匹配
print(re.findall('q[a*+?]',"iioojq*iusq+hiqaxxoo"))
#但是有3个特殊符号(-范围 ^非 \跟元字符去除特殊功能,\跟普通字符实现特殊功能),如匹配字符串中的字母
print(re.findall('q[a-z]','234988436qfsabcdefg386')) #a-z表示a到z任意字母,但是[]内终究只会匹配一个字符
print(re.findall('q[a-z]*','234988436qfabcdefg386')) #[a-z]*表示任意字母重复任意次,因为贪婪,所以会把后面的字母全部匹配进去
print(re.findall('q[0-9]*','ddsljq5201314skdjfinfkd')) #匹配任意数字
print(re.findall('q[^0-9]',"jkddafkjq123jiuqb")) #匹配非数字
运行结果:
- \转义字符:
\跟元字符去除特殊功能,\跟普通字符实现特殊功能
import re
#\d匹配数字字符,\D匹配非数字字符
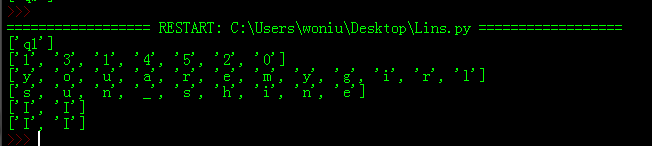
print(re.findall('q\d',"jkddafkjq123jiuqb")) #匹配一个数字字符
print(re.findall('\d',"jkjk1jkj3kji1hgh4o52knngygy0pp")) #匹配所有数字字符,包括不连续的不连接
#\s匹配任何空白字符(\t\n\r\f\v),\S匹配任何非空吧字符
print(re.findall('\S',"you are my girl"))
#\w匹配_、字母、数字字符,\W匹配非_、字母、数字字符
print(re.findall('\w',"s&u#n——_shine"))
#\\b匹配一个特殊字符边界,你需要的字符旁边有特殊字符
print(re.findall('I\\b',"may @I# am I from CHINA"))
#一个@I#中的I,一个单独的I和CHINA中的I,CHINA中的I周围没有特殊字符,所以不会匹配出来
print(re.findall(r'I\b',"may @I# am I from CHINA")) #r和\b结合也有同样的效果
#其中r的意思是不让python做翻译,\b在python中和在正则中的意思不同,不翻译python这一层,
#就可以达到正则的效果。第一次执行的\\b也是利用\将\b变成在python中无意义,但在正则中有效
运行结果:
- |或,()分组:
import re
#|左右两边都匹配
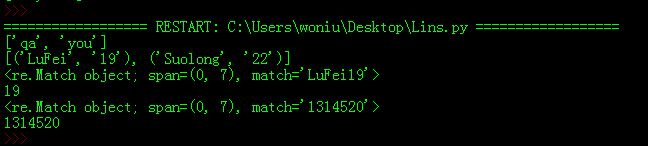
print(re.findall('qa|you',"jiushiqa|youiushi"))
#()将字符分组(特殊格式)
print(re.findall('(?P<name>[A-z]+)(?P<age>\d+)',"LuFei19Suolong22")) #匹配一串字母+一串数字
#用search()来匹配,只会匹配遇到的第一个组
print(re.search('(?P<name>[A-z]+)(?P<age>\d+)',"LuFei19Suolong22"))
#用group()将分组好的元素取出来
print(re.search('(?P<name>[A-z]+)(?P<age>\d+)',"LuFei19Suolong22").group('age'))
#match方法与search几乎相同,也是只会匹配遇到的第一个子串
print(re.match('\d+',"1314520jiushi2333333"))
print(re.match('\d+',"1314520jiushi2333333").group())
运行结果:
re模块下的其他方法
re模块下的方法,除了findall(),search()、match()还有以下几个常用的
- split()方法:分割字符串
import re
print(re.split('[ |]',"hello python|ok?")) #将母串用空格和|分开
print(re.split('[mv]',"mtakemvab"))
#先匹配到m,将m前的空字符和后面的一串分开,得到''和'takemvab'
#又匹配到m,将m前的take分开,得到'take'和'vab'
#又匹配到v,将v前的''分开,得到''和'ab'
运行结果:

- sub()方法、subn()方法:替换字符串内容
import re
print(re.sub('\d+','Q',"take123away4567it")) #将所有连续的数字替换成一个Q
print(re.sub('\d','Q',"take123away4567it")) #将所有数字替换成Q
print(re.sub('\d','Q',"take123away4567it",4)) #将前四个数字替换成Q
print(re.subn('\d','Q',"take123away4567it")) #替换后会返回替换的个数
运行结果:

- compile():自定义匹配规则
import re
dig = re.compile('\d+') #设计一个匹配连续数字的规则,并将规则命名为dig
print(dig.findall("love18874her15157")) #匹配时就可直接调用规则
运行结果:

- finditer():匹配后转换成迭代器
import re
ret = re.finditer('\d+',"love18874her15157Ok88") #匹配结果是一个迭代器组成的组
print(next(ret).group()) #用next来遍历,用分组取出
print(next(ret).group())
print(next(ret).group())
运行结果:

- ()内的?:表示去优先级:
import re
print(re.findall('www\.(?:baidu|sina)\.com',"www.sina.com")) #()分组会默认将分组拿出
print(re.findall('(abc)+',"xyzabcabcabcxyzxy")) #()内默认只会匹配一个组的内容
print(re.findall('(?:abc)+',"xyzabcabcabcxyzxy")) #其中?:去除优先级,则会匹配多个组的内容
print(re.findall('(abc)',"xyzabcabcabcxyzxy")) #但可以匹配多个组(有严格分组),不管是否有优先级
print(re.findall('(?:abc)',"xyzabcabcabcxyzxy"))
运行结果:

到此为止,本篇文章已经总结完了正则表达式与Pythonre模块中的大部分用法。很多细节部分也都有所举例,所以内容比较多,希望读者能慢慢消化。或许你会觉得正则表达式有些太繁琐,但是,当你学到爬虫那个阶段的时候,就知道正则表达式是多么好用。而且,作为一个程序员,正则应该是一项基本技能。
