一、黑盒测试的基本概念
黑盒测试又称
数据驱动测试,完全不考虑程序内部结构和内部特性,注重于测试软件的功能需求。
由于黑盒测试不需要了解程序内部结构,所以许多
高层测试,如确认测试、系统测试、验收测试都采用黑盒测试。
黑盒测试能发现以下几类错误:
-
功能不对或功能遺漏。
-
界面错误。
-
数据结构或数据库访问错误。
-
性能问题。
-
初始化和终止错误。
二、黑盒测试的优缺点
黑盒测试的优点
-
有针对性地找问题,并且定位问题更准确;
-
黑盒测试可以证明产品是否达到用户要求的功能,是否符合用户的工作要求;
-
能重复执行相同的操作,测试中最枯燥的部分可由自动化完成;
黑盒测试的缺点
-
需要充分了解产品用到的技术,测试人员需要具有较多的经验;
-
在测试过程中很多是手工操作;
-
测试人员需要负责大量的文档;
三、黑盒用例设计方法
1.等价类划分
例:计算两个1~100之间整数的和
如果要进行完全测试,一共要设计多少个测试用例呢?加数1有1~100共计100个取值,加数2也有1~ 100共计100个取值,所以他们之间的组合就有100*100=10000种组合可能,但这只是测试了正常范围内的取值。如果用户输入的数据不在1~ 100之间呢,穷举测试肯定不可能的。
由此引入了等价类划分思想。
等价类:是指某个输入域的子集合。
等价类划分为:
有效等价类:指符合《需求规格说明书》,输入合理的数据集合。
无效等价类:指不符合《需求规格说明书》,输入不合理的数据集合。
针对从上面的例子进行等价类划分
———————(<1)—————————|———————(1~100)—————————|——————(>100)—————
无效等价类 有效等价类 无效等价类
我们将输入域分成了一个有效等价类(1~100) 和两个无效等价类(<1,>100) ,并为每一个等价类进行编号,然后我们就可以从每一个等价类中选取一个代表性的数据来测试,设计如下表所示的测试用例:
|
编号
|
所属等价类
|
加数1
|
加数2
|
和
|
|
1
|
2(有效等价类)
|
3
|
40
|
43
|
|
2
|
1(无效等价类)
|
0
|
-1
|
提示“请输入1~100之间的整数”
|
|
3
|
3(无效等价类)
|
110
|
101
|
提示“请输入1~100之间的整数”
|
到这里我们的工作似乎结束了,还需要设计其他测试用例吗?
刚刚输入的数据都是整数,如果输入小数,甚至字母怎么办?
这说明刚才的等价类还不完善,我们只考虑了输入数据的范围,没有考虑输入数据的类型(我们认为只输入数据,可是最终用户输入什么都有可能)。综合考虑输入数据的类型和范围划分等价类,如下图所示:

等价类划分的测试用例(扩展)
|
编号
|
所属等价类
|
加数1
|
加数2
|
和
|
|
1
|
2(有效等价类)
|
3
|
40
|
43
|
|
2
|
1(无效等价类)
|
0
|
-1
|
提示“请输入1~100之间的整数”
|
|
3
|
3(无效等价类)
|
110
|
101
|
提示“请输入1~100之间的整数”
|
|
4
|
4(无效等价类)
|
1.2
|
1.2
|
提示“请输入1~100之间的整数”
|
|
5
|
5(无效等价类)
|
A
|
B
|
提示“请输入1~100之间的整数”
|
|
6
|
6(无效等价类)
|
@
|
%
|
提示“请输入1~100之间的整数”
|
|
7
|
7(无效等价类)
|
空格
|
空格
|
提示“请输入1~100之间的整数”
|
|
8
|
8(无效等价类)
|
|
|
提示“请输入1~100之间的整数”
|
等价类划分的步骤:
①先考虑输入数据的数据类型( 合法和非法的)
②再考虑数据范围(合法类型中的合法区间和非法区间)
③画出示意图,区分等价类
④为每一个等价类编号
例:有一个档案管理系统,要求用户输入以年月表示的日期。
条件:日期限定在1990年1月~2049年12月,并规定日期由6位数字字符组成,前4位表示年,后2位表示月。
测试用例:
1)划分等价类并编号,下表为等价类划分的结果
|
输入等价类
|
有效等价类
|
无效等价类
|
|
日期的类型及长度
|
①6位数字字符
|
②有非数字字符
③少于6位数字字符
④多于6位数字字符
|
|
年份范围
|
⑤在1990~2049之间
|
⑥小于1990
⑦大于2049
|
|
月份范围
|
⑧少于6位数字字符
|
⑨等于00
⑩大于12
|
2)设计测试用例,以便覆盖所有的有效等价类在表中列出了3个有效等价类,编号分别为①、⑤、⑧,设计的测试用例如下:
|
测试数据
|
期望结果
|
覆盖的 有效等价类
|
|
200211
|
输入有效
|
①⑤⑧
|
3)为每一个无效等价类设计一个测试用例,设计结果如下:
|
测试数据
|
期望结果
|
覆盖的 有效等价类
|
|
95June
|
无效输入
|
②
|
|
20036
|
无效输入
|
③
|
|
2001006
|
无效输入
|
④
|
|
198912
|
无效输入
|
⑥
|
|
205001
|
无效输入
|
⑦
|
|
200100
|
无效输入
|
⑨
|
|
200113
|
无效输入
|
⑩
|
2.边界值划分
程序的很多错误发生在输入或输出范围的边界上,因此针对各种边界情况设置测试用例,可以发现不少程序缺陷。
设计方法:
-
确定边界情况(输入或输出等价类的边界)
-
选取正好等于、刚刚大于或刚刚小于边界值作为测试数据
例:计算两个1~100之间整数的和
我们在设计测试用例的时。要重点考虑这两个边界问题。
根据边界值方法,测试用例修改如下:
|
编号
|
所属等价类
|
加数1
|
加数2
|
和
|
|
1
|
2(有效等价类)
|
1
|
1
|
2
|
|
2
|
100
|
100
|
200
|
|
|
3
|
1(无效等价类)
|
0
|
-1
|
提示“请输入1~100之间的整数”
|
|
4
|
3(无效等价类)
|
110
|
101
|
提示“请输入1~100之间的整数”
|
|
5
|
4(无效等价类)
|
1.2
|
1.2
|
提示“请输入1~100之间的整数”
|
|
6
|
5(无效等价类)
|
A
|
B
|
提示“请输入1~100之间的整数”
|
|
7
|
6(无效等价类)
|
@
|
%
|
提示“请输入1~100之间的整数”
|
|
8
|
7(无效等价类)
|
空格
|
空格
|
提示“请输入1~100之间的整数”
|
|
9
|
8(无效等价类)
|
|
|
提示“请输入1~100之间的整数”
|
边界值与等价划分的区别:
-
边界值分析不是从某等价类中随便挑一个作为代表,而是这个等价类的每个边界都要作为测试条件。
-
边界值分析不仅考虑输入条件,还要考虑输出空间产生的测试情况。
常见的边界值:
-
文本框接受字符个数,比如用户名长度,密码长度等。
-
报表的第一行和最后一行。
-
数组元素的第一个和最后一个,
-
循环的第1次、第2次和倒数第2次、最后一次。
等价类和边界值的综合示例
举例:某保险公司保费计算方式为投保额*保险率,保险率又依点数不同而有差别,10点以上费率为0.6%,10点以下费率为0.1%。保险率和以下参数有关:
-
年龄:数字0-150
-
性别:字符组合,区分大小写
-
婚姻:字符组合
-
抚养人:数字1-9人
注:其中前三个为必填项,最后一个为选填项
|
选项
|
参数 |
点数
|
|
年龄
|
20~39岁
|
6点
|
|
40~59岁
|
4点
|
|
|
60岁以上,20岁以下
|
2点
|
|
|
性别
|
MALE
|
5点
|
|
FEMALE
|
3点
|
|
|
婚姻
|
已婚
|
3点
|
|
未婚
|
5点
|
|
|
抚养人数
|
一人扣0.5点最多扣3点(四舍五入取整数)
|
|
考虑等价类
-
确定输入
输入:年龄、性别、婚姻、抚养人数
-
确定每个输入的输入条件
年龄:非负整数、0-150、
必填
性别:字符组合、区分大小写、MALE或者FEMALE、
必填
婚姻:字符组合、已婚或者未婚、
必填
抚养人数:正整数、1-9、
选填
-
对每个输入的输入条件进行等价划分
|
输入
|
输入条件 | 有效等价类 |
无效等价类
|
|
年龄
|
非负整数
|
非负整数 (1)
|
负整数 (7)
小数 (8)
字母 (9)
特殊字符 (10)
|
|
0~150
|
00~19 (2)
20~39 (3)
40~59 (4)
60~150 (5)
|
<0 (11)
>150 (12)
|
|
|
必填
|
填 (6)
|
不填 (13)
|
|
|
性别
|
字符组合
|
字符组合 (1)
|
非字符组合 (6)
|
|
区分大小写
|
大写 (2)
|
大写 (7)
大小写混合 (8)
|
|
|
MALE或FEMALE
|
MALE (3)
FEMALE (4)
|
非MALE、FEMALE(9)
|
|
|
必填
|
填 (5)
|
不填 (10)
|
|
|
婚姻
|
字符组合
|
字符组合 (1)
|
非字符组合 (5)
|
|
已婚或未婚
|
已婚 (2)
未婚 (3)
|
非已婚、未婚 (6)
|
|
|
必填
|
填 (4)
|
不填 (7)
|
|
|
抚养人数
|
正整数
|
正整数 (1)
|
非正整数 (6)
小数 (7)
字母 (8)
特殊字符 (9)
|
|
1~9
|
1~6 (2)
7~9 (3)
|
<1 (10)
>9 (11)
|
|
|
选填
|
填 (4)
不填 (5)
|
|
针对每个输入设计数据覆盖等价类
|
输入
|
有效值
|
无效值
|
|
年龄
|
15 (覆盖1、2、6)
25 (覆盖1、3、6)
50 (覆盖1、4、6)
80 (覆盖1、5、6)
边界值: 0、19. 20、39、40、59、60、150
|
-20 (覆盖7)
15.5 (覆盖8)
a (覆盖9)
& (覆盖10)
-999.5 (覆盖11)
180 (覆盖12)
不填 (覆盖13)
边界值:-1、151
|
|
性别
|
MALE (覆盖1、2、3、5)
FEMALE (覆盖1、2、4)
|
6553 (覆盖6)
male (覆盖7)
fEMALE (覆盖8)
男 (覆盖9)
不填 (覆盖10)
|
|
婚姻
|
已婚 (覆盖1、2、4)
未婚 (覆盖1、3、4)
|
1234 (覆盖5)
离婚 (覆盖6)
不填 (覆盖7)
|
|
抚养人数
|
5 (覆盖1、2、4)
8 (覆盖1、3、4)
不填 (覆盖3)
边界值:1、6、7、9
|
-6 (覆盖6)
5.1 (覆盖7)
A (覆盖8)
& (覆盖9)
-100 (覆盖10)
100 (覆盖11)
边界值:0、10
|
测试用例:
|
用例编号
|
年龄
|
性别
|
婚姻
|
抚养人数
|
点数
|
|
1
|
15
|
MALE
|
未婚
|
不填
|
12
|
|
2
|
25
|
FEMALE
|
已婚
|
8
|
9
|
|
3
|
50
|
MALE
|
未婚
|
5
|
11
|
|
4
|
80
|
FEMALE
|
已婚
|
1
|
7
|
|
5
|
0
|
MALE
|
未婚
|
不填
|
12
|
|
6
|
19
|
FEMALE
|
未婚
|
不填
|
10
|
|
7
|
20
|
MALE
|
未婚
|
不填
|
16
|
|
8
|
39
|
FEMALE
|
已婚
|
6
|
9
|
|
9
|
40
|
MALE
|
已婚
|
7
|
9
|
|
10
|
59
|
FEMALE
|
已婚
|
9
|
7
|
|
11
|
60
|
MALE
|
未婚
|
不填
|
12
|
|
12
|
150
|
FEMALE
|
已婚
|
9
|
无
|
|
13
|
-20
|
FEMALE
|
已婚
|
9
|
|
|
14
|
15.5
|
FEMALE
|
已婚
|
9
|
|
|
15
|
a
|
FEMALE
|
已婚
|
9
|
|
|
16
|
&
|
FEMALE
|
已婚
|
9
|
|
|
17
|
-999.5
|
FEMALE
|
已婚
|
9
|
|
|
18
|
180
|
FEMALE
|
已婚
|
9
|
|
|
19
|
不填
|
FEMALE
|
已婚
|
9
|
|
|
20
|
-1
|
FEMALE
|
已婚
|
9
|
|
|
21
|
151
|
FEMALE
|
已婚
|
9
|
|
|
22
|
39
|
6553
|
已婚
|
9
|
|
|
23
|
39
|
male |
已婚
|
9
|
|
|
24
|
39
|
fEMALE
|
已婚
|
9
|
|
|
25
|
39
|
男
|
已婚
|
9
|
|
|
26
|
39
|
不填
|
已婚
|
9
|
|
|
27
|
39
|
MALE |
1234
|
9
|
|
|
28
|
39
|
MALE
|
离婚
|
9
|
|
|
29
|
39
|
MALE
|
不填
|
9
|
|
|
30
|
39
|
FEMALE
|
已婚
|
-6
|
|
|
31
|
39
|
FEMALE
|
已婚
|
5.1
|
|
|
32
|
39
|
FEMALE
|
已婚
|
a
|
|
|
33
|
39
|
FEMALE
|
已婚
|
$
|
|
|
34
|
39
|
FEMALE
|
已婚
|
-100
|
|
|
35
|
39
|
FEMALE
|
已婚
|
100
|
|
|
36
|
39
|
FEMALE
|
已婚 |
0
|
|
|
37
|
39
|
FEMALE
|
已婚
|
10
|
3.错误推测法
基本思想:利用直觉和经验猜测出出错的可能类型,列举出程度中所有可能的错误和容易发生错误的情况,基本思想是列举出可能犯的错误或错误易发生的清单,然后根据清单编写测试用例;
这种方法很大程度上是凭经验进行的,即凭人们对过去所作测试结果的分析,对所揭示缺陷的规律性作直觉的推测来发现缺陷。
4.因果图法
因果图法比较适合输入条件比较多的情况,测试所有的输入条件的排列组合。所谓的原因就是输入,所谓的结果就是输出。
利用因果图导出测试用例需要经过以下几个步骤:
①分析程度规格说明的描述中,哪些是原因,哪些是结果原因;常常是输入条件或输入条件的等价类,而结果是输出条件。
②分析程度规格说明的描述中语义内容,并将其表示成连接各个原因与各个结果的“因果图”。
③标明约柬条件。由于语法或环境的限制,有些原因和结果的组合情况是不可能出现的。
④把因果图转换成判定表。
⑤为判定表中的每一列表示的情况设计测试用例。
基本图形符号:
-
恒等:若原因出现,则结果出现;若原因不出现,则结果不出现。
-
非(~) :若原因出现,则结果不出现;若原因不出现,则结果出现。
-
或(V) :若几个原因中有一个出现,则结果出现;若几个原因都不出现,则结果不出现。
-
与(N) :若几个原因都出现,结果才出现;若其中有一个原因不出现,则结果不出现。

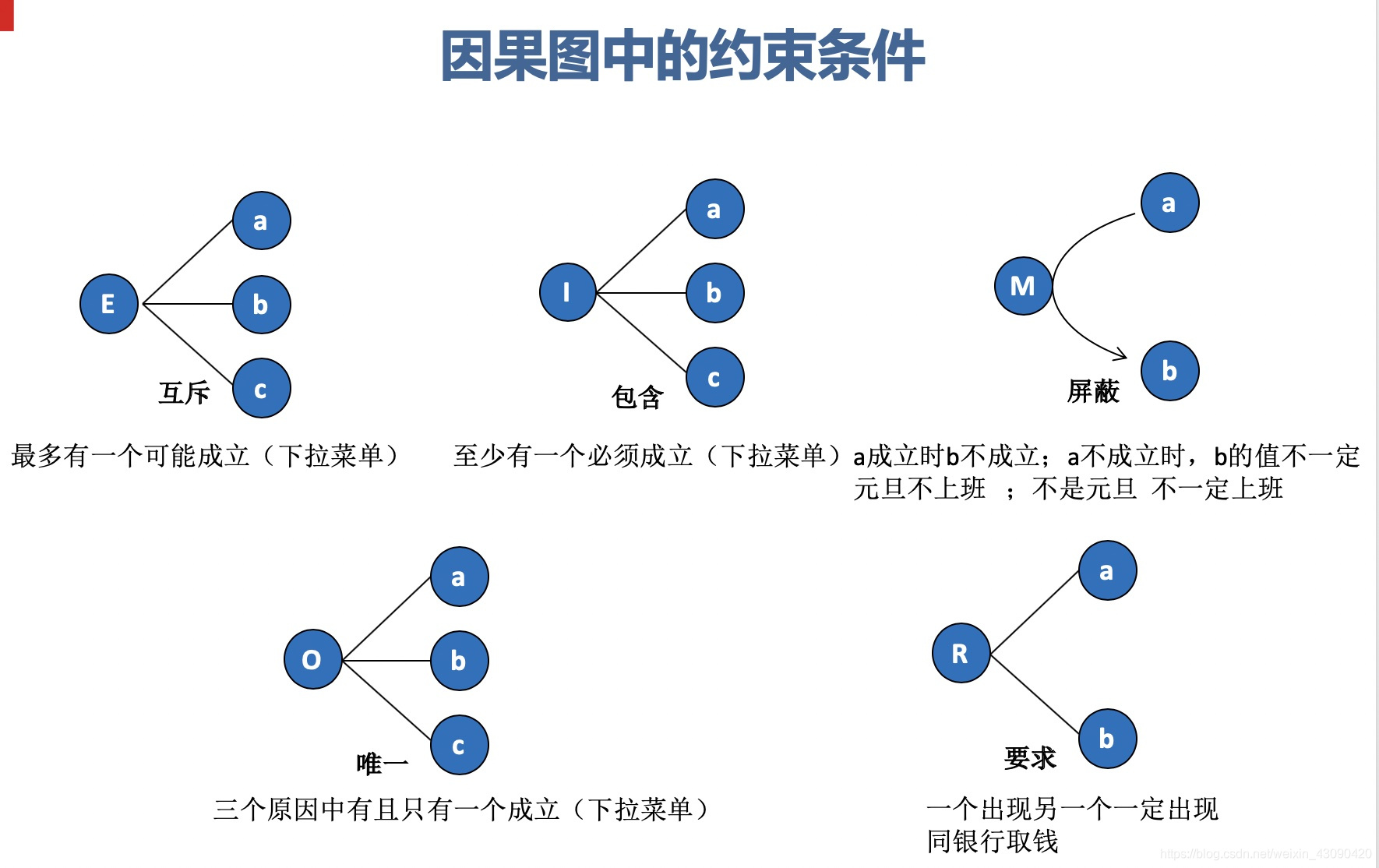
约束符号:
-
E (互斥) :表示两个原因不会同时成立,两个中最多有一个可能成立
-
I (包含) :表示三个原因中至少有一个必须成立
-
0 (惟一) :表示两个原因中必须有一个,且仅有一个成立
-
R (要求) :表示两个原因,a出现时,b也必须出现,a出现时,b不可能不出现
例:有一个处理单价为2.5元的盒装饮料的自动售货机软件。若投入2.5元硬币,按可乐”。“啤酒” 、或“奶茶”按钮。相应的饮料就送出来。若投入的是3元硬币。在送出饮料的同时退还5角硬币。
原因(输入):
①投入2.5元硬币;
②投入3元;
③按“可乐”按钮;
④按“啤酒”按钮;
⑤按“奶茶”按钮。
中间状态:
①已投币;
②已按钮
结果(输出):
①退还5角硬币;
②送出“可乐”饮料;
③送出“啤酒”饮料;
④送出“奶茶”饮料:

因果图转换成判定表

根据判定表设计测试用例

因果图法的问题
-
作为输入条件的原因和输出结果之间的因果关系,有时候很难从软件规格说明中得到。
-
因果图得到的测试用例数量将达到惊人的程度,这给软件测试工作带来了沉重负担。
5.正交试验设计法
什么是正交试验设计法?
正交试验设计法,是一-种成对测试交互的系统的统计方法。它提供了一种能对所有变量对的组合进行典型覆盖(均匀分布)的方法。可以从大量的试验点中挑出适量的、有代表性的点,利用“正交表” ,合理的安排试验的一种科学的试验设计方法。
正交表的构成
-
行数:正交表中的行的个数,即试验的次数,也是我们通过正交实验法
-
设计的测试用例的个数。
-
因素数:正交表中列的个数,即要测试的功能点。
-
水平数:任何单个因素能够取得的值的最大个数,即要测试功能点的取值个数。
-
正交表的形式: L行数(水平数^因素数)如: L8(2^7)。

用正交表设计测试用例的步骤
(1)有哪些因素(功能点)
(2)每个因素有哪几个水平(功能点的取值)
(3)选择一个合适的正交表
(4)把变量的值映射到表中
(5)把每一行的各因素水平的组合做为一个测试用例
(6)加上你认为可疑且没有在表中出现的组合
如何选择正交表
-
考虑因素(功能点)的个数
-
考虑因素水平(功能点的取值)的个数
-
考虑正交表的行数
-
取行数最少的一个
设计测试用例的三种情况
-
因素数(变量)、水平数(变量值)相符:因素数与水平数刚好符合正交表。
-
因素数不相同:如果因素数不同的话,可以采用包含的方法,在正交表公式中找到包含该情况的公式,如果有N个符合条件的公式,那么选取行数最少的公式。
-
水平数不相同:采用包含和组合的方法选取合适的正交表公式。
例一:视图选项卡上的“显示隐藏”组中有3个可用选项:

有3个因素:网格线、编辑栏、标题
每个因素有2个水平:选与不选
选择正交表的分析:
1、表中的因素数>=3;
2、表中至少有3个因素数的水平数>=2;
3、行数取最少的一个。
4、从正交表公式中开始查找,结果为: L4(2^3)。
正交表变量的映射
网格线: 0→选,1→不选
编辑栏: 0→选,1→不选
标题:0→选,1→不选
|
|
列号
|
|||
|
1
|
2
|
3
|
||
|
行号
|
1
|
0
|
0
|
0
|
|
2
|
0
|
1
|
1
|
|
|
3
|
1
|
0
|
1
|
|
|
4
|
1
|
1
|
0
|
|
||
\ /
|
|
列号
|
|||
|
1
|
2
|
3
|
||
|
行号
|
1
|
选
|
选
|
选
|
|
2
|
选
|
不选
|
不选
|
|
|
3
|
不选
|
选
|
不选
|
|
|
4
|
不选
|
不选
|
选
|
|
测试用例如下:
1.选中网格线、选中编辑栏、选中标题
2.选中网格线、不选编辑栏、不选标题
3.不选网格线、选中编辑栏、不选标题
4.不选网格线、不选编辑栏、选中标题
增补测试用例
5.不选风格线、不选编辑栏、不选标题
测试用例的减少数: 8→5
例二:根据PowerPofnt的打印功能的描述设计测试用例,功能描述如下:
-
打印范围分:全部、当前幻灯片、给定范围
-
打印内容分:幻灯片、讲义。备注页、大纲视图
-
打印颜色/灰度分8颜色。灰度、黑白
-
打印效果分8幻灯片加框、幻灯片不加框
案例分析:
根据以上提到的功能说明,构造因子状态表,得到因子状态
|
状态/因素
|
A打印范围
|
B打印内容
|
C打印颜色/灰度
|
D打印效果
|
|
0
|
全部
|
幻灯片
|
颜色
|
幻灯片加框
|
|
1
|
当前幻灯片
|
讲义
|
灰度
|
幻灯片不加框
|
|
2
|
给定范围
|
备注页
|
黑白 |
|
|
3
|
|
大纲视图
|
|
|
将中文字转换成字母的因子状态表
|
状态/因素
|
A
|
B
|
C
|
D
|
|
0
|
A1 |
B1
|
C1
|
D1
|
|
1
|
A2
|
B2
|
C2
|
D2
|
|
2
|
A3
|
B3
|
C3
|
|
|
3
|
|
B4
|
|
|
选择正交表的分析:
1、表中的因素数>=4;
2、表中至少有4个因素数的水平数>=2;
3、行数取最少的一个。
4、从正交表公式中开始查找,结果为: L16(4^5)
注:此案例中有四个被测对象,每个被测对象的状态都不一样。
正交表:

因为分析第5列是没有意义的,所以第5列可以删掉,由于4个因素中那么有一些是小于3的,所以第13到第16我们都可以删除
得到如下测试用例:

6.场景图
用例场景是用来描述流经用例路径的过程,这个过程从开始到结東遍历用例中所有基本流和备选流。
用例场景举例:

场景1:基本流
场景2:基本流备选流1
场景3:基本流备选流1备选流2
场景4:基本流备选流3
场景5:基本流备选流3备选流1
场景6:基本流备选流3备选流1备选流2
场景7:基本流备选流4
场景8:基本流备选流3备选流4
举例8 ATM机用例场景
基本流
1、准备提款:用户将银行卡插入ATM取款机
2、验证银行卡: ATM机从银行卡的磁条中读取帐户代码,检查它是否是可接收的银行卡
3、输入密码: ATM机要求用户输入密码
4、验证账户和密码:确定该帐户是否有效和所输入密码是否正确
5、ATM选项:显示本机的各种选项,如果选择“取款”
6、输入金额:要从ATM机取款金额
7、授权: ATM机通过帐户、密码、金额以及帐户信息作为一笔交易发给银行系统来启动验证过程。对此事件,银行系统处理连机状态,并对授权请求给予答复,批准完成取款过程,同时更新帐户余额
8、出钞:提供现金
9、返回银行卡:银行卡被返还
10、打印收据:打印收据并提供给用户,同时更新内部记录
备选流2
ATM机内没有现金
备选流3
ATM机内现金不足
备选流4
密码有误
备选流5
帐户不存在或帐户类型有误
备选流6
帐面金额不足
测试用例矩阵:

测试用例数据:

7.流程图法
我们在编程时,一般都需要画程序的算法流程图,可以将这一思想应用到黑盒测试领域。算法流程图是针对程序内部结构的,而黑盒测试的流程图是针对整个系统业务功能流程的。
流程图法的步骤:
第一步:详细了解需求
第二步:根据需求说明或界面原型,找出业务流程的各个页面以及各页面之间的流转关系
第三步:画出业务流程
第四步:写用例,覆盖所有的路径分支
流程图用例:订票模块业务流程图

8.小结
在实际测试过程中,我们往往需要综合各种测试技术,现在我们来总结一下如何踪合运用的前面学的测试技术。

测试用例的设计方法不是单独存在的,具体到每个测试项目里都会用到多种方法,每种类型的软件有各自的特点,每种测试用例设计的方法也有各自的特点,针对不同软件如何利用这些黑盒方法是非
常重要的,在实际测试中,往往是综合使用各种方法才能有效提高测试效率和测试覆盖度,这就需要认真掌握这些方法的原理,积累更多的测试经验,以有效提高测试水平。
