(更新时间:2020-03-05)
接上一篇,继续解读Style2paints V3论文 "Two-stage Sketch Colorization"。
目录
8.1.2 草图合成算法1:Random Region Proposal and Pasting
8.1.3 草图合成算法2:Random Transform
8.1.4 草图合成算法3:Random Color Spray
7. 阶段一:草图阶段(Drafting Stage)
7.1 网络结构

7.2 损失函数

其中:lamda=0.01
损失函数的任务目标为:不强制要求网络生成高质量的上色结果,但要求网络根据用户的颜色提示,将较丰富的色彩泼洒到画布上,以增加配色的丰富性和鲜艳性。
为了增加色彩的丰富程度,损失函数中加入了正则约束项(Positive Regulation Loss)L(x),如式(2)所示。该式类似于方差公式,能增加选取的颜色在RGB空间中的多样性(较大的方差)。该约束项能部分地解决部分情况下上色饱和度低的问题。其效果对比如图 10所示。
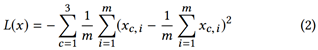

7.3 如何生成模拟颜色提示点?
论文没有具体展开描述颜色提示点的模拟生成算法,只说明基于文献[1]的算法进行改进。下面介绍黑白照片上色论文[1]中的颜色提示点生成算法。
要训练基于颜色提示(Color hint)的深度上色网络,必须拥有Color hint数据。然而问题在于,不仅收集该类数据的代价高昂,而且实际上是不可行的!因为收集Color hint数据是一个chicken and egg问题(先有鸡还是先有蛋问题)。具体而言,Color hint数据是在用户与上色系统交互的过程中产生的,用户在评估系统输出的初步上色结果之后,才能在不满意的位置添加下一个Color hint;但是,由于没有现有的Color hint数据,所以没有已训练好的上色网络,因此无法给用户呈现初步上色结果。即:用户的颜色提示与系统呈现的上色效果存在“循环依赖”关系!为了打破这一“循环依赖”,本文使用模拟合成的用户Color hint数据来训练网络。由此引发的潜在问题为:模拟合成数据与实际用户数据存在分布差异的问题。但本文实验结果表明,模拟合成的数据能够训练出的效果较好的上色网络。
关键问题在于:如何生成模拟的颜色提示点?

模拟颜色提示点生成算法:
(1)对于每张图像,需要添加几个颜色提示点?
提示点的数量,从p=1/8的几何分布中随机抽取。
(2)在整幅图像的哪些位置添加颜色提示点?
每个提示点的坐标,从二维高斯分布(![]() )中随机抽取。选择使用二维高斯分布的原因为:本文预计用户对靠近图像中心的区域添加颜色提示点的可能性更大。
)中随机抽取。选择使用二维高斯分布的原因为:本文预计用户对靠近图像中心的区域添加颜色提示点的可能性更大。
(3)用户在选择提示点的颜色时,往往会存在一定的偏差。那么,模拟生成的颜色提示点该如何选择颜色?
提示点的颜色:以该提示点为中心确定一个较小的矩形区域,并取区域的平均颜色值。区域的大小从1×1至9×9的均匀分布中随机抽取。(取区域的平均颜色, 应该是考虑到用户添加的颜色提示与照片对应像素的实际颜色常存在一定的误差。)另外,为了增强网络对用户颜色提示的服从性,取1%的训练图像,其提示点的颜色直接取该坐标上对应像素的颜色。
8. 阶段二:精修阶段(Refinement Stage)
8.1 草图模拟合成算法
8.1.1 动机
Drafting阶段生成的草图上色质量较低,往往包含较多上色错误和缺陷。为了提高上色质量,算法必须能够检测出包含缺陷的区域并对其进行修正。为了实现这一目标,本文提出了Refinement模型。
要让深度网络学会自动检测和修正上色缺陷,需要有足够的训练数据。一种可能的方案是邀请专业画师对上一阶段生成的草图进行逐一修正,形成用于训练的成对图像{网络输出的草图,画师修正图}。但该方案过于费时费力。另一种方案是使用“上一阶段生成的草图”和“数据集中的原版彩色漫画”作为训练集,形成用于训练的成对图像{网络输出的草图,原版彩色漫画}。但该方案的缺陷在于可能会对特定的草图过拟合,而降低模型的泛化能力。另外,更糟的是,该方案等价于同时训练两个阶段的网络,使得本文设计的两阶段模型框架变得毫无意义。而且本文的实验结果也表明该方案的上色效果并不好。
为了解决这一问题,本文提出了一种算法,用于模拟合成包含上色缺陷的草图(Draft)。该算法根据原版彩色漫画来合成带上色缺陷的草图,形成用于训练的成对图像{模拟合成草图,原版彩色漫画}。该算法能帮助Refinement模型学会如何修正不同类型的上色错误。另外,该算法还能增强Refinement模型的泛化能力,使得Refinement模型不仅能够修正本文Drafting网络生成的草图,还能修正其他深度上色网络(如:PaintsChainer)生成画作中的上色缺陷。
需要指出的是,草图模拟合成算法与“数据增强”(Data Augmentation)算法存在本质区别:“数据增强”算法是对输入的数据(本文的输入为线稿和颜色提示点)进行变换,而草图模拟合成算法是在模拟Drafting模型的输出。
8.1.2 草图合成算法1:Random Region Proposal and Pasting
模拟的上色缺陷:Color mistakes(填充了错误的颜色)
算法:

1.随机补丁(patch)抽取:对每幅彩色漫画,使用以下两种方法抽取10,000个patch。
法1:随机从彩色漫画中裁剪出矩形区域,区域的大小从64×64至256×256范围的均匀分布中随机抽取。
法2:对漫画进行边缘检测,然后分割出不规则形状的图形。
2.将抽取的patch经过随机旋转后,粘贴到原版漫画的随机位置。
8.1.3 草图合成算法2:Random Transform
模拟的上色缺陷:Color distortion(边界线识别错误,着色发生偏移)
算法:

对原版漫画进行随机扭曲变换,使着色区域发生偏移。
8.1.4 草图合成算法3:Random Color Spray
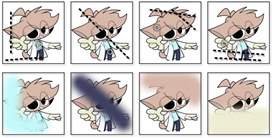
模拟的上色缺陷:Color bleeding(色彩弥散式溢出)
算法:
1.从原版漫画中随机选择一种颜色。
2.用较大半径的喷枪将该颜色随机喷洒到漫画上。半径r从[64,128]范围的均匀分布中随机抽取。喷洒的路径为多个随机生成的线性路径。喷枪纹理使用专门设计的纹理,用于模拟颜色溢出。
8.2 网络结构


Refinement模型的网络结构,与Style2paints V1(基于风格迁移的线稿上色)的网络结构具有相似性(详见S2P V1论文解读)。在Refinement阶段,U-net的输入仍然包含线稿。草图作为“上色参考图”,使用Inception提取出特征,然后输入到U-net中层。
8.3 损失函数
损失函数如式(3)所示,结合了mean absolute error和adversarial loss。

其中:lamda=0.01
9. 数据集
训练集:使用Danbooru 2018数据集。超过三百万张漫画,总大小约2.5 TB。
测试集:使用53张从网上下载的真实手绘线稿(不包含在训练集中)。涵盖了来自多位人类画家的多种绘画类型,包括:人物、动物、植物、风景画。为避免训练集中包含与测试集相似的图片,对于每张测试线稿,都移除训练集中与该线稿最相似的3幅图片。
最后,感谢作者开源了相关代码与模型!
参考文献:
[1] Richard Zhang, Jun-Yan Zhu, Phillip Isola, Xinyang Geng, Angela S Lin, Tianhe Yu, and Alexei A Efros. Real-time user-guided image colorization with learned deep priors. ACM Transactions on Graphics (TOG), 9(4), 2017.
