1 案例分析
案例一:Library cache lock等待
问题背景:
严重的Library cache lock等待,导致SQL执行的很慢

问题分析:
Library cache lock等待常见场景:
- DDL、统计信息搜集
Namespace→1:table/view/sequence/synonym/ - 错误密码登陆
Namespace→79:Account status - FailureParse
Namespace→82:SQL AREA BUILD - ADG
Namespace→74:DBINSTANCE

案例二:row cache lock等待
问题背景:
大量的row cache lock等待事件,导致数据库夯住。
问题分析:
从dba_hist_active_sess_history中分析看到,数据库于17:30:28开始出现row cache lock(dc_user),从中可以看到,1号节点的会话4901阻塞了3052,4901是一个sqlplus程序,在执行grant object操作。
分析数据库audit日志XXXX1_ora_25757616_1.aud如下:

因为这个系统业务期间每个节点每秒大概有5、6次的login,两个节点加起来每秒大概有10到12次的login。在因此导致了大量的row cache lock等待事件。
DC_USERS This may occur if a session issues a GRANT to a user and that user is in the process of logging on to the database. Investigate why grants are being made while the users are active.
解决方案:
避免在业务期间进行grant/revoke操作。
案例三:truncate大表
问题背景:
truncate大表,导致业务等待资源释放,进而数据库服务器连接数太多导致崩溃
问题分析:
在表的truncate的操作没有完成的情况下,所有的INSERT操作都被挂起了。然后由于这个INSERT操作又是应用程序的日志记录操作,所以造成了大部分客户化的应用程序都因为等待日志表的写而挂起。
ASH记录中,有2000多个6zx4a78zj3963(Insert CUX_0_WS_INVOKE_LOG)都执行了20分钟以上。
分析原因,可能是除了Truncate进程,其他排队的进程基本都是6zx4a78zj3963。因为6zx4a78zj3963数量非常多,但是又因为Truncate在前,Insert执行不了。到Truncate终止,Insert语句才开始执行。
注:检查了6zx4a78zj3963的执行数量,从5月27日10:11到5月30日14:45,一共76.5小时,一共执行了月500万次,平均每小时6.5万次,每分钟超过1000次。尽管每次连接不只写入一条记录,保守估计,以每次连接写入10条记录来算,每小时的连接数也有6500次。因此,Truncate语句如果40多分钟没有执行完成,堵住的Insert语句就有可能超过最大进程数5000。
解决方案:
Truncate大表的时候,虽然不写日志,但因为要回收空间,所以也是会有性能问题的。对于有CLOB字段的表,Truncate的性能就有点类似Delete了。另外,索引的存在,也会影响Truncate的性能。
Truncate大表,虽然手工终止,但是数据库后台还在继续释放资源,这个过程可能持续20分钟之久。
建议将表按时间分区,并定期清理。清理时,直接Drop掉不再需要的历史分区即可。但使用分区表时也要注意,尽量不要有全局索引。如果有全局索引,无论是Truncate分区还是Drop分区,都会造成全局索引失效,需要重建索引。
Truncate大表时,可以结合使用reuse storage来提高性能。
通常认为,Truncate和Drop都是ddl语句,都会释放表占用的空间,且不可回退。这是因为Truncate默认使用的是drop storage,Truncate的同时会立即释放extent,删除的表如果非常大,就会有很明显的性能问题。如果使用reuse storage的话,是不会立即释放表的extent的,性能就会好很多。
具体做法是先使用如下Truncate语句:
Truncate table tableName reuse storage;
然后,再分批释放空间:
ALTER TABLE BIGTAB DEALLOCATE UNUSED KEEP 4096M;
ALTER TABLE BIGTAB DEALLOCATE UNUSED KEEP 2048M;
ALTER TABLE BIGTAB DEALLOCATE UNUSED KEEP 1M;
对于LOB字段和索引,也可以采用同样的方式逐步回收:
ALTER TABLE MODIFY LOB() DEALLOCATE UNUSED KEEP xxxM;
ALTER INDEX DEALLOCATE UNUSED KEEP xxxM;
案例四:统计信息收集不及时
问题背景:
统计信息收集不及时,导致执行计划变了,有一个sql,一段时间比较快,一段时间比较慢。
问题分析:
这个sql_id的执行计划主要有两个,Plan Hash Value分别是2716755970和256938306。

像这种情况,建议直接通过SQL Profile绑定执行计划,使其固定使用Plan Hash Value = 2716755970的执行计划。
为什么会出现两个效率明显差异的执行计划交替使用呢?我们认为应该跟表的统计信息有一定的关系。
这个sql中用到的几个大表,MTL_MATERIAL_TRANSACTIONS的统计信息是2018/5/5的,表OE_ORDER_HEADERS_ALL的统计信息是2018/2/5的,但表OE_ORDER_LINES_ALL的却是2018/5/26的。这种直接关联的表,统计信息日期相差太大的话,会出现不匹配的现象。如果查询的条件刚好覆盖到最新一部分数据时,就会造成有的表有该部分数据的统计信息,但有的表却没有的情况。这时CBO就会认为两表关联结果为0,出现误判。
案例五:乱加并行度,会话数暴增
问题背景:
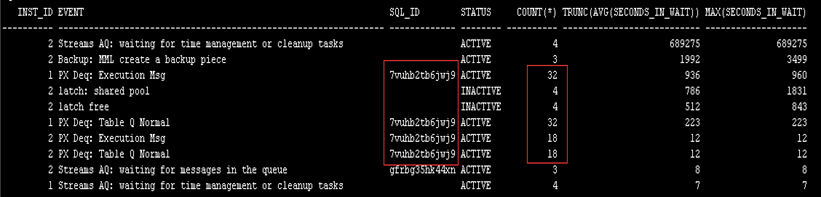
有些SQL,占用Session数很多,比如下面的7vuhb2tb6jwj9
问题分析:
从等待事件看,这些Session都是等待PX相关事件,说明这些都是并行执行的Slave Session,但整个SQL里并没有添加Parallel提示,怀疑是某个表或者索引的Degree大于1。
检查发现,一些表重建索引的时候加了并行,但是事后没有将并行去掉。
一个sql,消耗太多Session,就会造成资源浪费,并有可能导致连接数不够,影响其他用户登录。
而且,如果不是Index Full Scan,而是Index Range Scan或者Index Unique Scan等的话,并行扫描是完全不会提高性能的。几乎没有哪个表或者索引,启用并行扫描一定就会快。一定要根据具体的执行计划才能决定是否需要加并行。因此,在表上或者索引上设置Degree大于1是不提倡的。可以根据需要在相应的SQL语句上加并行提示。
另外,视图创建脚本上,也不需要加并行提示。
案例六:SQL未加绑定变量
问题背景:
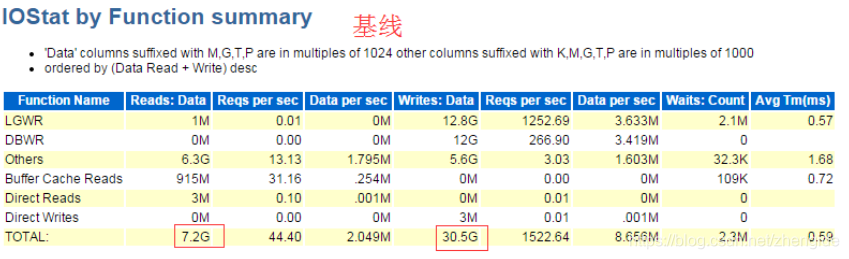
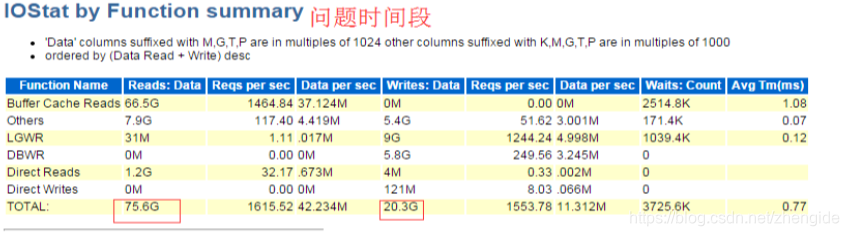
大量SQL未加绑定变量,导致共享池资源争用严重,从而引发数据库资源不足,导致hang。
SQL解析命中率:
Library Hit %: 72.53 Soft Parse %: 52.59
共享池大小抖动情况:(SGA_TARGET = 7168M)
MIN_SIZE MAX_SIZE CURRENT_SIZE
1120M 6048M 1384M
问题分析:
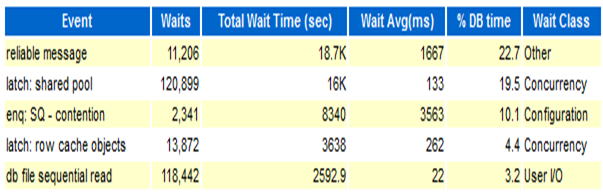
应用系统中存在大量SQL语句未使用绑定变量,导致共享池的争用严重,共享池的严重争用导致相关事件的等待时间变长,数据库响应变慢。
当系统处于业务高峰,数据库会话数急剧增加,操作系统内存耗尽,出现了严重的换页现象,最终导致数据库hang。
案例七:SQL语法不规范
问题背景:
SQL语法写法不规范,造成PGA耗用较大且不释放。
现象:收到监控系统反馈,一个Linux系统上的RAC数据库的内存耗用较多,swap空间也使用较多。
问题分析:
-
按照操作系统命令,对内存使用情况的进程进行排序。
ps -aux | sort -k4nr | head -20 -
对排名靠前的会话进行分析,且分析awr报告,发现内存耗用都是在PGA上。
-
对排名靠前的会话进行采用heapdump分析。
# 数据库heapdump命令. oradebug setospid 108856 oradebug unlimit oradebug dump heapdump 5 oradebug tracefile_name -
对trace文件分析解读,发现超过90%的内存耗费在top uga heap段的qmxdpls_subheap部分。
EXTENT 8 addr=0x7fe877963030 Chunk 7fe877963040 sz= 2072 freeable "qmxdpls_subhea " ds=0x7fe8bc0ce278 Chunk 7fe877963858 sz= 4264 freeable "qmxdpls_subhea " ds=0x7fe8bc0ce278 Chunk 7fe877964900 sz= 4184 freeable "qmxdpls_subhea " ds=0x7fe8bc0ce278 Chunk 7fe877965958 sz= 4264 freeable "qmxdpls_subhea " ds=0x7fe8bc0ce278 -
对qmxdpls_subhea进行分析,此部分是由解析xml时使用的,初步怀疑问题点是在程序调用xml时造成内存泄漏。
-
为了进一步对初步判断的点进行更深入的程序分析,定位找到相应的代码
select PGA_ALLOC_MEM/1024/1024/1024 GB,a.spid,b.machine,b.program,b.sql_id,b.event,b.status from v$process a,v$session b where a.addr=b.paddr and PGA_ALLOC_MEM/1024/1024/1024>1 order by 1;发现多个进程耗用PGA 4G,且都是一个sql_id,直接杀掉这些进程,释放部分空间,可是过一会,又起来了。
-
分析sql代码,找到发现调用xml解析的点。
代码里面有一段:XMLDOM.OPENDOCUMENT,上MOS进行查询,Oracle对此语句的写法有建议:
调用后,用XMLDOM.FREEDOCUMENT 释放内存。
-
通知开发,对此sql进行修改,按照官方建议整改,后续监控发现,没有该问题发生。
2 数据库性能最佳实践
2.1 使用连接池
当数据库操作和访问频繁的时候,使用连接池可以减少创建连接和打开连接所耗的时间,提升数据库服务器的性能。
2.2 绑定变量减少硬解析
硬解析消耗大量的CPU时间和系统资源。硬解析过多会降低系统性能。
2.3 业务高峰期,尽量避免实行DDL
• 一个简单的GRANT语句都可能会引起性能问题。
• 执行DDL后会引起相关的SQL在共享池中的失效。
当相关SQL再次并发执行,可能会导致硬解析风暴。从而引起"library cache lock", "row cache lock", "cursor: pin S wait on X"以及相关latch的等待。
2.4 数据库服务器上部署OSWatcher
完善的监控有助于提前发现性能问题,并且在出现性能问题时快速定位瓶颈。
2.5 定时搜集统计信息
• 优化器并不完美。
• 优化器有效的补充:
(1)SQL Tuning Advisor
(2)SQL Plan Baseline
(3)SQL Profile
(4)SQL Patch
(5)SQL 书写优化
2.6 按时应用PSU/RU
定时打补丁,有助于提高数据库安全性及性能。
2.7 使用AWR基线