- 难例挖掘是检测任务中常用的手段. 因为一个图片中负样本(背景)的数量远远大于正样本(GT), 因此将 loss 比较高(即难以分辨正负, hard negative)的样本保留下来继续训练模型, 其余的简单样本丢弃.
- 文本检测中除了基于回归就是基于分割的方法。
个人想法:
也许在处理相近文本时, 实例分割比语义分割有天然的优势.
1 PixelLink
作者采用实例分割的方法进行文字检测.
Pipeline:
- 网络对每个像素预测 文本/非文本.
- 将属于同一个实例(两个像素间的 link 为 positive)的像素连接, 组成一个 Connected Component (CC).
- 用 OpenCV 中 minAreaRect 在 CC 上绘出锚框(四边形).
- 作者根据对数据集的统计, 将短边小于 10 个像素或面积小于 300 像素的锚框丢弃(IC15中 99% GT 符合这个标准)
上面预测 文本/非文本, link 为 pos 或 neg 的两个阈值, 10 和 300 均为超参数, 不能通过学习得到.
2. Shape-Aware Embedding
作者通过实例分割的方法进行文本检测。
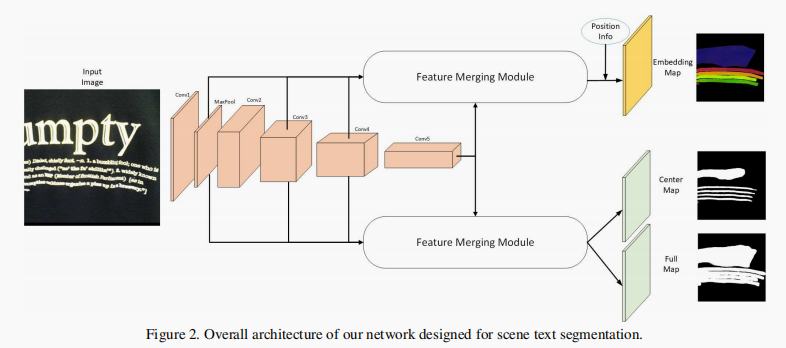
输入图片经过 backbone 后,分成两个分支。一个分支结合原始图片的像素位置生成 Embedding Map,另一个分支生成 Center Map 和 Full Map。
- Embedding Map 为八通道,每个像素值代表了该像素对应原始图片感受野的嵌入特征(而不是表示颜色);
- Full Map 为和原始图片大小相同的单通道二值图片(1 为文本,0 为背景),它提供了一个图片中总体的文本位置
- Center Map 提供了像素簇的初始位置(用于后续的膨胀,且降低了相近文本的干扰),借鉴了 EAST,作者将 Full Map 按 0.7 的比率缩小得到 Center Map。

图片分割的结果和使用 L SA 与 Dice Loss 的对比
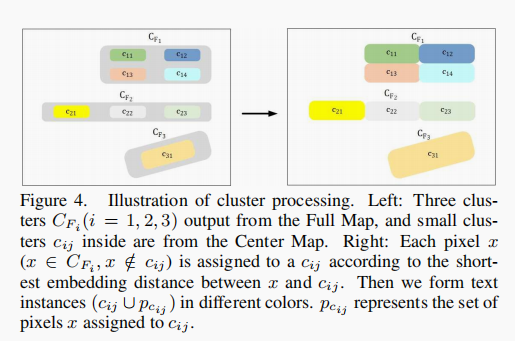
基于 Center Map , Full Map,根据 Embedding Map 将簇进行归类、膨胀
根据以下原则得到最终簇:
- 基于 Full Map 和 Center Map 使用 DBSCAN 算法得到两个簇 — CFi 和 CCi (分别表示 Full Map 的簇和 Center Map 的簇)。
- 对于介于 Full Map 和 Center Map 之间的像素,如果它的嵌入距离(pixel embedding)与一个簇的平均嵌入距离(average embedding of pixels)小于给定的阈值(人工指定的超参数) ,则将该像素归入该簇,否则忽略。
损失函数:
-
损失函数
其中 表示第 个文本实例, 表示该实例中含有的像素个数, 表示文本实例嵌入特征的平均值, 表示第 个像素的嵌入特征值. 0.5 表示 margins for varince loss. 1.5 表示 margins for distance loss. 和 表达式见论文,作者分别将其指定与区间(1, 1.65), (0.63,1). 正比于实例的尺寸。 越大, 越大,使得实例内部像素相互靠近,以降低 。 正比于实例 间的最短距离,使得两个文本实例的嵌入特征距离越来越远。因为 越小, 越大。因此设置一个较小的 有助于 的减小。第一个式子中, 绝对值的值越大, 越大, 第二个式子中, 绝对值的值越小(表示俩实例越近), 越大.
因此, 需要优化的参数是 , 表示:
- 同个文本实例内嵌入特征的像素值与像素均值差越小越好
- 不同文本实例间嵌入特征的均值差越大越好.
最终, 兼顾不同实例间距离和同一实例内像素间的距离,表达式为:
其中 N 为一张图片中所含文本实例的个数。
-
损失函数
用于训练 Center Map 和 Full Map,公式见论文。
3. PSENet
PSENet 的两大特点:1. 基于像素分割 2. 基于小 Kenel 进行扩展得到最终标定框。
具体来说特点 2,模型首先生成与文本形状类似的小 Kenel,然后采用逐步规模扩展(progressive scale expasion)来合并像素。网络结构如下:
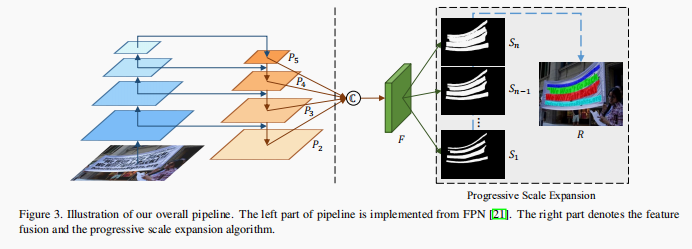
图片左边为 FPN,P3、P4、P5 进行上采样,然后和 P2 进行 concat,F 表示 feature map。S1 ,S2,…,Sn 表示逐步扩张的 Kenel,Sn 即为最终 Kenel。
逐步规模扩张算法如下:


在像素扩张过程中,若出现同一个像素被两个 Kenel 包含,则采取先到先得原则。
网络训练过程中由于 Kenel 尺寸不同,因此需要不同尺寸的标签。作者采用 Vatti clipping 算法对 GT 进行裁剪得到不同尺寸的标签。
4. DB
DB 兼顾了精度和速度。和其他基于分割的场景文本识别模型不同,DB 的阈值是可训练的,并且把图像二值化过程嵌入到训练过程。这样,网络可以对图像每个像素点进行自适应预测 ,来区分文本和背景。由于标准二值化公式是不可微的,作者提出了近似二值化公式,使网络可以端到端训练。
DB 的主要优点:
- 得益于可微分二值化,网络简化了繁杂的图像分割后处理步骤,大大提高了模型速度。
- 在推断阶段,网络可以去掉可微分二值化模块,不影响模型性能。(DB 可以理解为用来帮助模型训练的)
网络结构如下如所示:
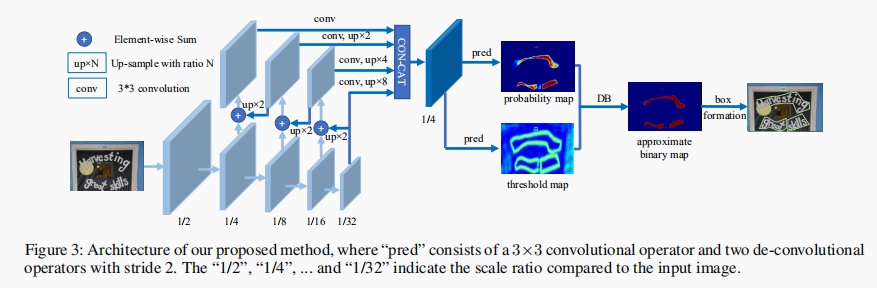
左边为 FPN,基于其生成的特征图同时预测概率图(Probability Map)和阈值图(Threshold Map),进而进行二值化,最终得到结果。
如上面提到的,标准二值化公式不可微:
因此作者提出了近似二值化公式:
其中
,损失函数采用二分类交叉熵损失函数:
它们的导数分别为:
可以看出,它们分别
- 对负数 敏感(分类为背景)。 为负时梯度大,为正时梯度小。
- 对正数 敏感(分类为文本)。 为 正时梯度大,为负时梯度小。
将其可视化如下:
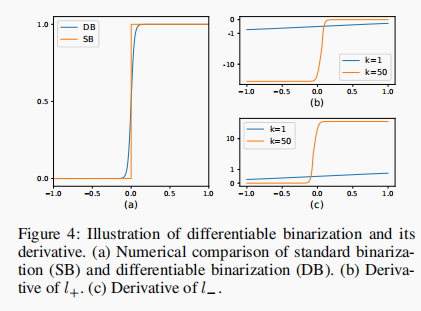
此外,作者同样采用了 Vatti clipping 算法对 GT 进行裁剪得到不同尺寸的标签和难例挖掘。作者还采用了可变形卷积(Deformable Convolution),来改善卷积效果。
数据集:
- SynthText (Gupta, Vedaldi, and Zisserman 2016)
是人工数据集,包含八百万张图片。作者将其用来预训练模型。 - MLT-2017 dataset
是多语言数据集,包含了九种语言。含有 7200 张训练图片,1800 张验证图片,9000 张测试图片。作者将训练和验证图片用来 fintune 模型。 - ICDAR 2015 dataset (Karatzas et al. 2015)
包含了 1000 张训练图片和 500 张测试图片。单词级标注。 - MSRA-TD500 dataset (Yao et al. 2012)
是多语言数据集(英语,中文)。300 张训练图片和 200 张测试图片。文本行(text-line)级别标注。作者还额外包括了来自 HUST TR400 (Yao, Bai, and Liu 2014) 的 400张训练图片。 - CTW1500 dataset CTW1500 (Liu et al. 2019a)
是曲线文本数据集,包含 1000 张训练图片和 500 张测试图片。文本行级别标注。 - Total-Text dataset Total-Text (Chng and Chan 2017)
为任意形状文本数据集,包括水平,多方向和曲线。包含1255 张训练图片,300 张测试图片。单词级标注。
CRAFT
对于训练标签生成,与以往分割图(以二值化的方式离散标记每个像素的label)的生成方式不同,本文采用高斯热度图来生成region score和affinity score.
