1.问题现象
在RobotFramework中执行自动化用例时,日志中出现中文乱码如“\xE5\x8C\x97\xE4\xBA\xAC”,如下图:
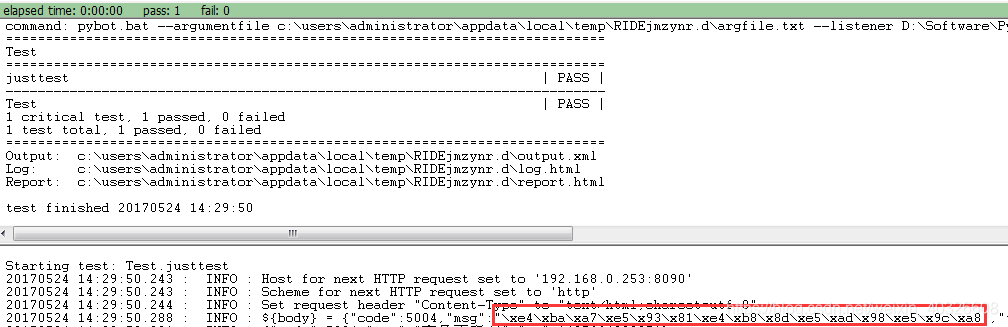
2.问题原因
经过我的一番调查,才发现:\x 是16进制的unicode编码。
在Python中,我们可以使用 decode(‘utf-8’) 方法将这种“\x”格式解码成中文,比如:
str=“\xe4\xbc\x98\xe5\x8c\x96”
print(str.decode('utf-8'))
那么为什么unicode编码可以使用utf-8格式来解码呢?原因是:UTF-8 是 Unicode 的实现方式之一。
这个细讲的话就很长了,这里不做详述,大家可以参考《字符编码笔记:ASCII,Unicode 和 UTF-8》这篇文章,讲得非常棒。
然后问题又来了,为啥我的RobotFramework没有使用utf-8进行decode呢?
后来调查才发现,我的RobotFramework版本是基于Python2的,Python2默认是ASCII编码,所以这种问题基本上都是在py2中出现的。而在Python3中,默认编码是unicode,就不会出现这种问题。
3.解决方法
既然知道了是默认编码ASCII的原因,且RobotFramework为开源项目,所以直接去找源代码即可。
3.1 方法一
这是个一劳永逸的解决办法,在python安装目录下,在Lib/site-packages/robot/utils目录下的unic.py文件中,在下面两个位置,把“ASCII”改为“utf-8”,如下图:

再次执行,检查log,OK了,如下图:

3.2 方法二
第二种方法就是写自己的关键字,把对应中文转换为“utf-8”即可。
def logConvertStr(self,content,charset='utf-8'):
"""常用于日志中文乱码如‘\xe4\xba\xa7’
转换为指定字符编码,常用字符集编码有utf-8,utf-8,gbk,gb2312等"""
content = str(content).decode(charset)
print content
