一,简述
预训练模型因为模型参数太大,以及推断太耗时的原因导致工程上的应用受到了极大的限制,模型压缩技术就是在解决这一问题,对复杂的大模型,在不显著降低性能的情况下,尽可能的减少其参数量并提升其推断速度。模型压缩的的方法通常有蒸馏,剪枝,量化等。本篇文章会带来最近bert知识蒸馏的一些最新paper解读(假定大家熟悉知识蒸馏的概念)。
二,论文解读
论文一:Distilling Task-Specific Knowledge from BERT into Simple Neural Networks
19年3月份的一篇文章,算是比较早期的,整体并没什么亮点。本文是用bert作为teacher模型,单层的Bi-LSTM作为student模型。蒸馏过程中的teacher模型提供的唯一约束目标是soft logits和hard label(针对无标签的数据),针对标签数据的蒸馏过程如下:
1)teacher模型和student模型的soft logits的mse(均方误差)约束。
soft logits是softmax后的结果,损失函数如下:
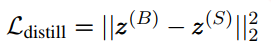
2)student模型的soft logits和one-hot标签的交叉熵损失,再组合上面的均方误差损失。
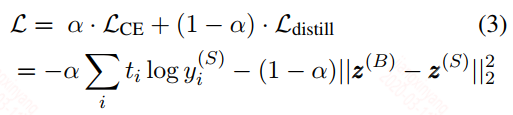
上面式子中$\alpha$是超参数。
无标签的数据和有标签的数据唯一不同的是,无标签数据先经过teacher模型得到一个“ground-truth”,而这个就作为one-hot标签,也就是说约束的soft logits和 ground-truth都是由teacher模型产生的。
这里的无标签的数据是作者自己生成的,类似于数据增强,但又有点不太一样,这里的数据增强只管生成和原始样本不同的样本,而不关注生成的样本的语义是否和之前一致,有随机mask,同词性的词替换,n-gram采样子序列,这一部分感觉意义不大,并且作者也没有给出实验证明引入了数据增强的对比,所以不细讲,有兴趣的自己去看。
蒸馏后的结果实验结果如下:
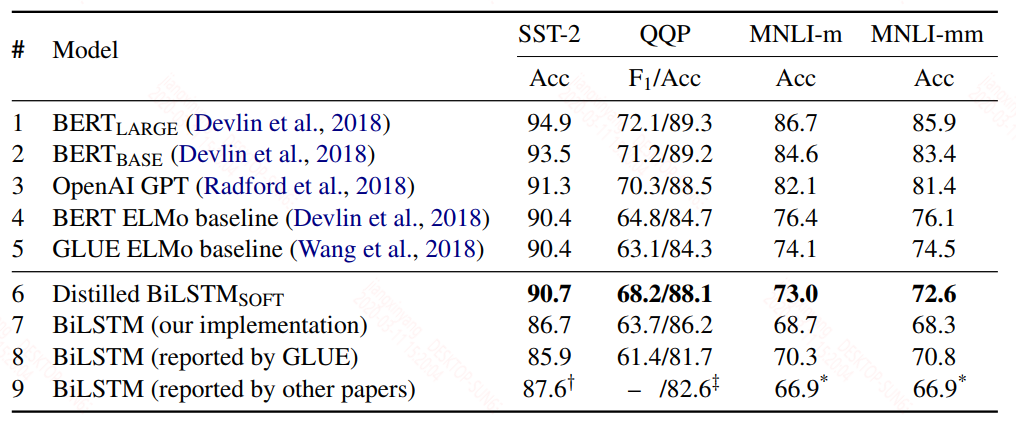
第6行是蒸馏的Bi-LSTM的结果,7,8,9行是不同来源的Bi-LSTM的结果,总体来看蒸馏后的效果确实是有比较大的提升,但是蒸馏的Bi-LSTM的结果较bert还是有明显差距的,尤其是比较比较难的任务,比如MNLI(自然语言推断任务),差了10个点以上,这个也好理解,对于比较难的任务,简单的模型容量不够,不能很好的表征任务。
模型大小和推断速度提升还是蛮明显的。
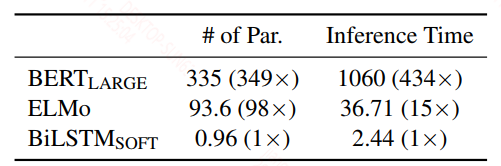
参数量只有bert_large的1 / 349,推断速度是bert_large的434倍,较elmo也是有不错的提升,关键在性能上也和elmo基本一致,简单的任务上优于elmo,复杂的任务上差点,感觉如果提升到两层Bi-LSTM,可能在复杂的任务上的效果会有提升。
论文二:Patient Knowledge Distillation for BERT Model Compression
Patient Knowledge Distillation,耐心的知识蒸馏,从标题上看就知道作者的蒸馏肯定比上面一篇文章要复杂点,确实,除了用teacher模型的最后输出,还是用了中间层的信息,既然要使用中间层,那么在student模型的结构上就得有一些约束,要和teacher相似,所以这里的student模型用的也是transformer,最后层的输出和上面一样:
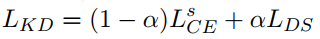
${L^S}_{CE}$是真实标签的交叉熵损失,$L_{DS}$是teacher的soft logits损失,和上面唯一不同的是这里的soft logits的损失也是用的交叉熵,不过目测用交叉熵还是均方误差影响并不大。
模型中间层的约束是直接对[CLS]字符的输出的约束,所以student模型除了层数比bert少,transformer层和bert的结构是一样的,约束的策略有两种,比如student取6层,bert_base是12层,第一种用bert_base的最后6层的输出约束student,另一种是使用skip的方式用{2, 4, 6, 8, 10, 12}层约束student。约束损失如下:
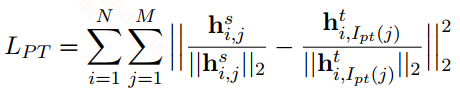
这里的输出是做了归一化的,所以更像是相对约束,而不是具体值得绝对约束。所以这种约束看上去和soft logits很相似,如果是内部权重参数的约束,一般都是绝对约束。
实验结果如下:

上面的下标系数6和3表示student的层数,当student模型较大时,还是能保留较好的结果,在MNLI上取得的效果也远好于上篇论文中的单层Bi-LSTM,这也是必然的,毕竟这里的student模型大小并没有减少太多。有一个比较有意思的地方,bert_large的蒸馏效果并不会好于bert_base:

个人理解,在知识蒸馏时并不一定是teacher能力越强,蒸馏的效果就一定越好,这还取决于student的接收能力,而这个接收能力就是studnet模型的复杂程度,当然如果一个teacher本身就很差,但肯定还是能力强的teacher表现会更好,但是这里的bert_base和bert_large在上述任务上的差距并不是很大,所以也导致这样的结果。
论文三:DISTILLING TRANSFORMERS INTO SIMPLE NEURAL NETWORKS WITH UNLABELED TRANSFER DATA
又一篇用bert来蒸馏Bi-LSTM的论文,这篇论文的蒸馏方法比第一篇要复杂一点,但效果比第一篇好多少,这个不确定,因为论文中并没有使用通用的GLEU数据来测试,而是在一些简单的任务上做的测试。本文的贡献还是在于在少量数据的情况下使用无标签的数据蒸馏student带来的效益。
student模型是双层的Bi-LSTM,蒸馏的知识除了第一篇文章中的两种,新引入了一种对bert最后层和Bi-LSTM最后的输出的约束,但是因为维度不一样,所以对Bi-LSTM的输出做了维度转换,这种方法看上去是针对student和teacher结构不同的一种可行的约束方式,间接约束:
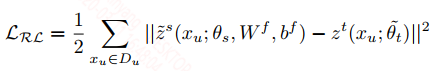
${\tilde{z}}^s$是转换后的Bi-LSTM的输出,$W^f, b^f$是转换参数,$z^t$是teacher的输出,用的也是均方误差来约束。最终的损失如下:
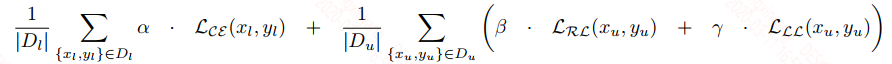
$\alpha, \beta, \gamma$都是可调的超参数。
除了三种损失之外,训练时也提供了三种策略:
1)联合上面三种损失训练,配置不同的权重参数
2)分两阶段训练,一阶段先用参数约束来训练student网络直到收敛,二阶段再用标注数据和teacher的logits来训练模型,为了避免一阶段的信息被灾难性遗忘,采用逐层解冻的方式训练student。
3)分两阶段训练,一阶段先用teacher的参数约束和logits来蒸馏训练student网络,二阶段用标注数据来fine-tuning student,并且也采用逐层解冻的方式训练,而且可以永久迭代式训练,即标注未标注的数据来训练模型。
在数据量很少的情况下,用标签数据fine-tuning teacher模型,在训练student的时候,taecher的监督信息都是使用无标签的数据,有标签的数据只用来对student做交叉熵损失。
实验结果如下:
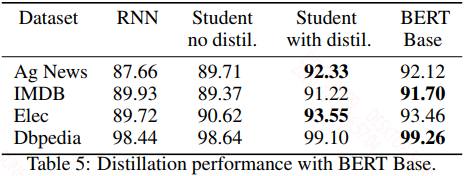
论文中的实验任务都比较简单,蒸馏和未蒸馏的其实差的不多,而且蒸馏后的结果和bert类似,这应该也是因为任务简单的缘故。
不同训练策略带来的结果:
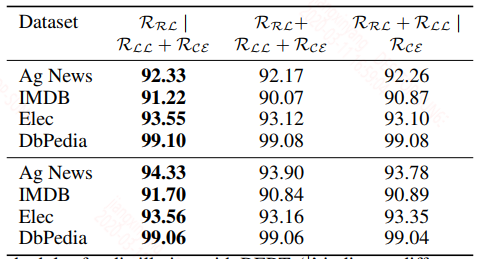
从结果上来看,第二种策略的效果最好,分析原因可能是,一阶段的输出约束可以讲参数初始化到一个合理的值,二阶段两个约束都属于分类层的约束,目标类似,放在一起会更合理。
当标签数据比较少的时候,假设每个标签下的数据只有500个,得到的结果如下:
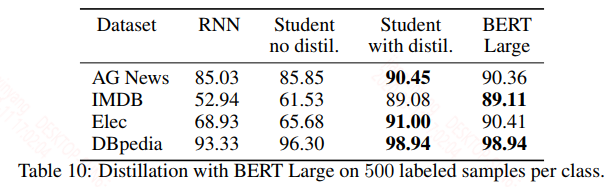
bert这种预训练模型在数据量比较少的情况下也能取得很好的效果,此时利用bert对标注无标签的数据来训练student能极大的提升student的效果。这种模式可以用来做半监督学习。
论文四:MOBILEBERT: TASK-AGNOSTIC COMPRESSION OF BERT BY PROGRESSIVE KNOWLEDGE TRANSFER
这篇论文应该是我目前看过最好的知识蒸馏来压缩bert的论文,当然这篇论文中不只是知识蒸馏的概念,还引入了bottleneck network(类似低秩近似),以及证明了把网络做深获得的收益要大于把网络做宽。非常好的一篇论文,建议大家去看看原文。先来看一张网络结构设计图:
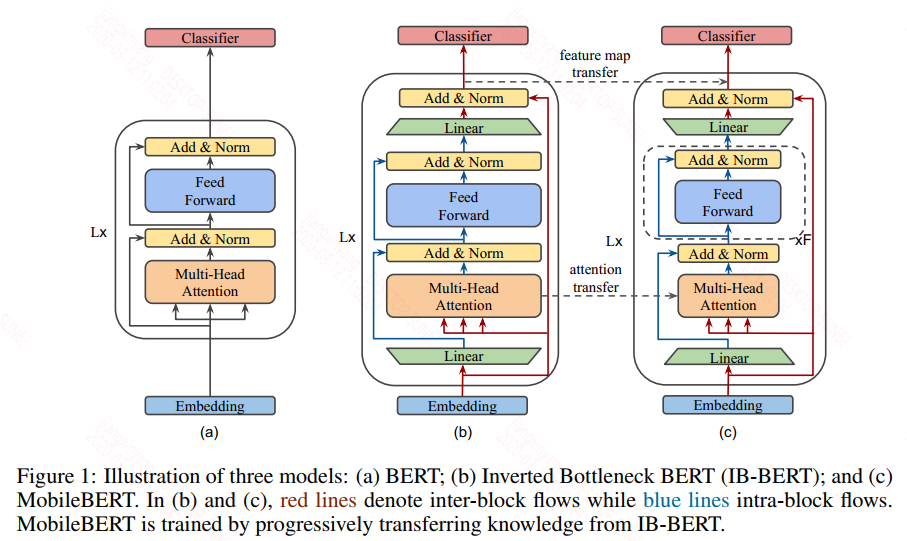
图(a)是正常的bert的结构图,图(b)是teacher模型图,图(c)是student模型图。图(a)不用再多讲了,假设你已经熟悉bert的结构,我们来看看teacher和student是怎么设计的。首先图中的Linear层是bottleneck network层,输入端称为inter-block,输出端称为intra-block,图(b)和图(c)的数据流动是一样的,唯一不同的是bottleneck network,在图(b)中intra-block的大小是大于inter-block,而图(c)中正好相反。图(b)的数据流向如下:
1)embedding层的输出输入到MHA层(在后面的layer中,embedding层的输出可以换成上一层的输出)
2)Liner层的输出和MHA层组成残差链接,表达式:$F(x) = f(MHA(x)) + Linear(x)$,这里的$f(x)$是保持维度一致,作者在论文中没有提,但从图中看应该是要有这样一部操作,否则MHA和Linear的输出维度不一致。
3)上一步$F(x)$的结果进入到FFN层,这个和bert中一致。
4)FFN层的输出经过一个和上一个Linear正好输入输出维度相反的Linear层,可以将每一个layer的输入输出的维度保持一致。
从上面的流程可以看到,进入到FFN层的维度值是比较大的,而在student中,因为bottleneck netword正好设置的相反,所以进入到FFN层的维度值是比较小的。在bert中FFN层是非常重要的非线性转换部分,从albert中也可以看到,不断地增大MHA的隐层大小和FFN的隐层大小是可以极大的提升性能,但是从诸多前人的经验知道网络做深比做宽好,但宽的网络更容易被训练,因此在student中要想仍然保持FFN的非线性能力,作者将每一个transformer layer中的FFN层的层数增加了。具体的teacher和student模型的参数设计看下图,作者设计了多种参数并对比了在SQuAD v1.1中的性能:
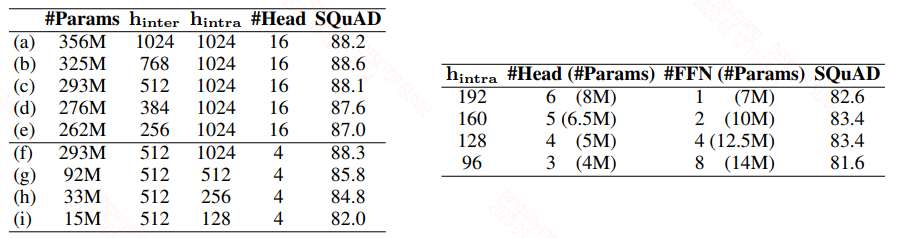
上图中左边是teacher的参数设计,从左图中的(c)和(a)来看保持intra-block的维度不变,降低inter-block对性能几乎没影响,从(f)和(c)中看较少MHA的头数,性能也基本不变。这也验证了一个问题,MHA的头数有时候并不需要这么多,大多数都是冗余的,当然减少头数基本不能降低参数和推断速度。
上图中右边是student的参数设计,作者发现当MHA的参数和FFN层的参数比在0.4 - 0.6之间(作者称在bert中MHA和FFN的参数比是0.5,一开始没算出来,因为FFN层的隐层大小是MHA层的4倍,而MHA中的key,value,query都有一个同维度的线性变换,后面发现MHA输出后还有一个同维度的线性变换,所以参数比确实是0.5),模型的效果最好,注意这里的student是未蒸馏的结果。
综上作者最终选择的teacher和student的模型参数如下,这里的teacher是作者自己从0训练的:

上图中第二行的三个模型都是标准的bert,第三行第一个模型是teacher,第二个是student。
模型设计完之后,接着谈论怎么设计蒸馏策略的。作者引入了一种从底到顶的促进式蒸馏的方法,针对每一层去蒸馏,即先蒸馏第一个transformer层的信息,收敛后再蒸馏第二层,依次类推,但是在蒸馏内部层的时,是没有目标分布信息来帮助训练的,因此作者提出了两种蒸馏模式来训练内部层,feature map transfer和attention transfer,直接内部的中间结果蒸馏,我们知道想做内部中间结果的蒸馏的必要条件是维度一致,再回到前面的模型结构图,(b)和(c)中的红线流向的值的维度作者给设计为一致的,也就是上面表格中teacher和student的$h_{inter}$的维度一致,因此每个transformer layer的最后输出的维度是一致的,从图中看也就是每个transformer layer的最后layer normalization的输出,以及MHA中的维度都是一致的。
feature map transfer
根据上面的描述,针对LN层的输出定制约束损失:
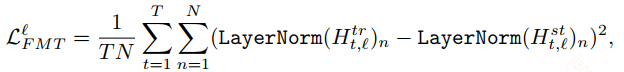
除了对输出的约束之外,还对LN中的均值和方差进行了约束:
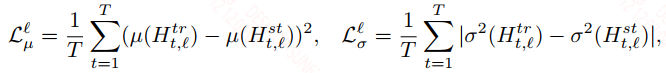
attention transfer
attention层的约束是对归一化后的权重参数的KL散度,因为归一化的值是服从概率分布的:
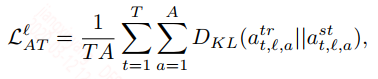
BOTTOM-TO-TOP PROGRESSIVE KNOWLEDGE TRANSFER (PKT)
逐层训练的策略如下图:
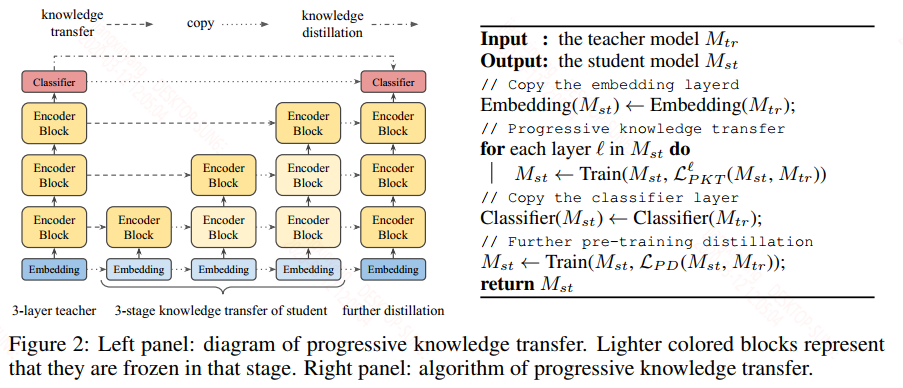
在训练$l$层时有必要将前面层的参数冻住,不过这里作者并没有完全冻住,而是给了一个很小的学习速率来训练前面的层。
由上面的策略来看只能处理中间的transformer layer,对于embedding layer和最后的output layer是没有作用到的,因此最后还是要以MLM和NSP这两个任务的目标信息来蒸馏:
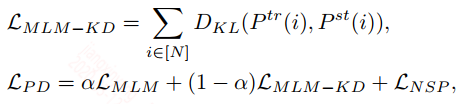
来看下结果,在GLEU上的结果:
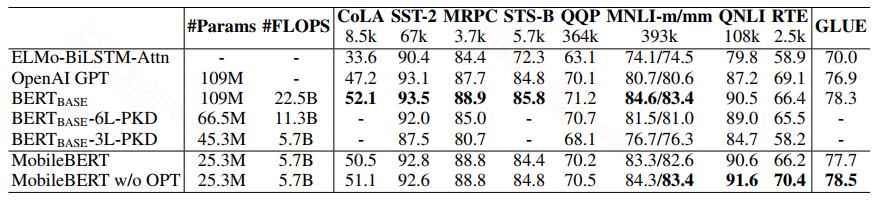
设计的MobileBERT的结果是要优于第二篇论文中的结果,并且接近于bert_base。而且带OPT的模式效果更好,那么这里的OPT是什么?
作者通过实验发现LN层和gelu激活函数占据了大部分计算资源,作者将这里的gelu激活函数换成了relu,将LN层改成下面的形式:
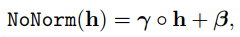
$\gamma$和$h$之间的element-wise的乘积。
在SQuAD上的结果:
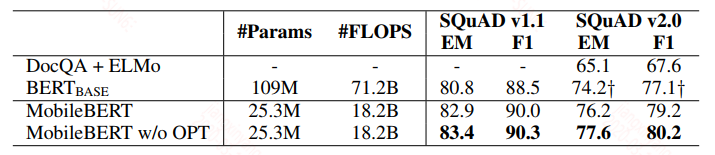
从结果上看是要优于bert的。不同的蒸馏策略的结果:
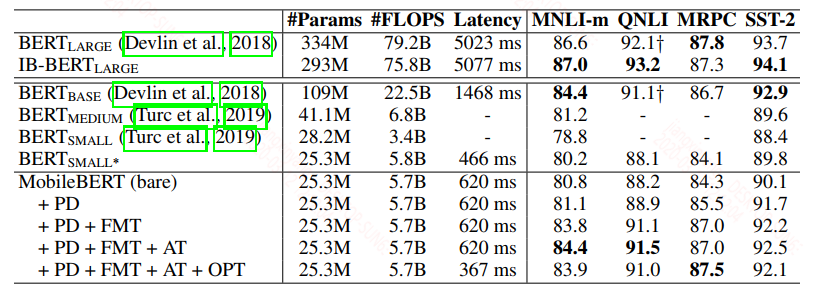
从上面看综合效果基本和bert_base持平,甚至略优,模型大小是bert的1/4,推断速度也是bert的1/4。压缩效果提升明显,并且效果基本不变,坐等开源。