INSERT
INSERT
INTO <表名> [(<属性列1>[,<属性列2 >…)]
VALUES (<常量1> [,<常量2>]… );
[例3.69]将一个新学生元组(学号:201215128;姓名:陈冬;性别:男;所在系:IS;年龄:18岁)插入到Student表中。
INSERT
INTO Student (Sno,Sname,Ssex,Sdept,Sage)
VALUES ('201215128','陈冬','男','IS',18);
后两行需一一对应,可改变Sno,Sname,Ssex,Sdept,Sage的顺序
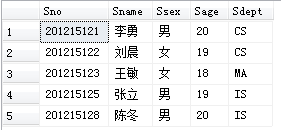
因建表时规定学号唯一,所以不能有两个相同学号

[例3.70]将学生张老三的信息插入到Student表中。
INSERT INTO Student
VALUES ('201215124','张老三','男',18,'CS');
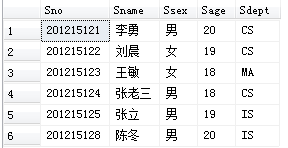
这种方式可省略属性名,但VALUES后数据必须按表格表头的顺序
给Course添加一行数据
INSERT INTO Course(Cno,Cname,Cpno,Ccredit)
VALUES ('1','数据库',NULL,4);
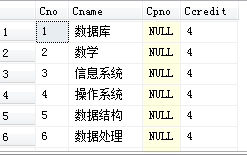
cpno是外键,而且引用的是该表的主键cno。参照完整性规则,外键cpno的取值不为空的情况下,与其对应的主键cno必须存在,所以这里cpno故意写的NULL
[例3.71] 插入一条选课记录( ‘200215128’,'1 ')。
INSERT
INTO SC(Sno,Cno)
VALUES ('201215128','1');
关系数据库管理系统将在新插入记录的Grade列上自动地赋空值。
或者:
INSERT
INTO SC
VALUES ('201215128','1',NULL);
(在表里添加了成绩)
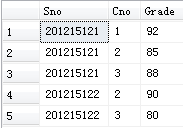
Sno和Cno是SC表的外键,SC表中的数据参照前两张表中的数据,所以必须是刚才两张表里面已经有的学号和姓名
INDEX
建立索引:
CREATE [UNIQUE] [CLUSTERED | NONCLUSTERED] INDEX <索引名> ON <表名>(<列名>[<次序>][,<列名>[<次序>] ]…);
<表名>:要建索引的基本表的名字
索引:可以建立在该表的一列或多列上,各列名之间用逗号分隔
<次序>:指定索引值的排列次序,升序:ASC,降序:DESC。缺省值:ASC
UNIQUE:此索引的每一个索引值只对应唯一的数据记录
CLUSTERED:表示要建立的索引是聚集索引
NONCLUSTERED:表示要建立的索引是非聚集索引
[例3.13] 为学生-课程数据库中的Student,Course,SC三个表建立索引。Student表按学号升序建唯一索引,Course表按课程号升序建唯一索引,SC表按学号升序和课程号降序建唯一索引
CREATE UNIQUE INDEX Stusno ON Student(Sno);
CREATE UNIQUE INDEX Coucno ON Course(Cno);
CREATE UNIQUE INDEX SCno ON SC(Sno ASC,Cno DESC);
第三个索引中,Sno升序排列与Cno降序排列的意思是先按Sno升序排序,在相同的Sno下对于不同的Cno再降序排列
修改索引:
ALTER INDEX <旧索引名> RENAME TO <新索引名>
[例3.14] 将SC表的SCno索引名改为SCSno
ALTER INDEX SCno RENAME TO SCSno;
而在SQL serever中,ALTER不能修改表名和索引名,如若改变索引名就需要调用存储过程。
在SQL serever中,ALTER可以:
1.新增列
ALTER TABLE Student ADD S_entrance DATETIME;–向基本表Student中增加“入学时间”属性列。
2.新增约束
例3.10
3.修改某字段的数据类型
例3.9
(https://blog.csdn.net/weixin_41287260/article/details/83627461)
删除索引:
DROP INDEX <索引名>;
[例3.15] 删除Student表的Stusname索引
DROP INDEX Stusname;
在SQL serever中执行出现以下错误:必须为 DROP INDEX 语句指定表名和索引名。
应该为 :
DROP INDEX Student.Stusname;
格式为 :
DROP INDEX <用户名>.<索引名>;
(http://blog.sina.com.cn/s/blog_4fe8580b0100c8z2.html)
SELECT
数据查询:
SELECT [ALL|DISTINCT] <目标列表达式>[,<目标列表达式>] …
FROM <表名或视图名>[,<表名或视图名> ]…|(SELECT 语句)
[AS]<别名>
[ WHERE <条件表达式> ]
[ GROUP BY <列名1> [ HAVING <条件表达式> ] ]
[ ORDER BY <列名2> [ ASC|DESC ] ];
SELECT子句:指定要显示的属性列
FROM子句:指定查询对象(基本表或视图)
WHERE子句:指定查询条件
GROUP BY子句:对查询结果按指定列的值分组,该属性列值相等的元组为一个组。通常会在每组中作用聚集函数。
HAVING短语:只有满足指定条件的组才予以输出
ORDER BY子句:对查询结果表按指定列值的升序或降序排序
[例3.16] 查询全体学生的学号与姓名。
SELECT Sno,Sname
FROM Student;
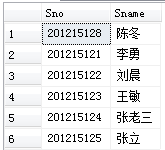
[例3.17] 查询全体学生的姓名、学号、所在系。
SELECT Sname,Sno,Sdept
FROM Student;
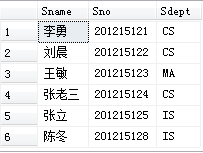
[例3.18] 查询全体学生的详细记录
SELECT Sno,Sname,Ssex,Sage,Sdept
FROM Student;
或
SELECT *
FROM Student;
可以在SELECT关键字后面列出所有列名,也可以用*代替
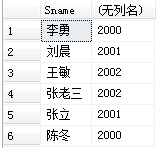
[例3.19] 查全体学生的姓名及其出生年份。
SELECT Sname,2020-Sage /*今年为2020年*/
FROM Student;
[例3.20] 查询全体学生的姓名、出生年份和所在的院系,要求用小写字母表示系名。
SELECT Sname,'Year of Birth: ',2020-Sage,LOWER(Sdept)
FROM Student;
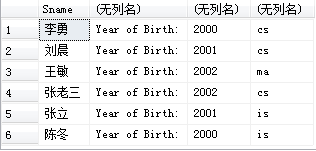
LOWER为函数,用来将文本中的字符串全部转换为小写
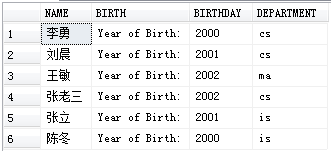
使用列别名改变查询结果的列标题:
SELECT Sname NAME,'Year of Birth:' BIRTH,
2020-Sage BIRTHDAY,LOWER(Sdept) DEPARTMENT
FROM Student;
在属性后+“ ”+“列名”
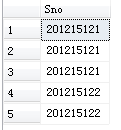
[例3.21] 查询选修了课程的学生学号。
没有指定DISTINCT关键词,则缺省为ALL
SELECT Sno FROM SC;
等价于:
SELECT ALL Sno FROM SC;
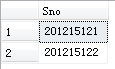
加上关键词DISTINCT会去掉表中重复的行
SELECT DISTINCT Sno
FROM SC;
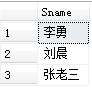
[例3.22] 查询计算机科学系全体学生的名单。
SELECT Sname
FROM Student
WHERE Sdept='CS';
[例3.23]查询所有年龄在20岁以下的学生姓名及其年龄。
SELECT Sname,Sage
FROM Student
WHERE Sage < 20;
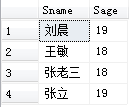
[例3.24]查询考试成绩有不及格的学生的学号。
SELECT DISTINCT Sno
FROM SC
WHERE Grade<60;
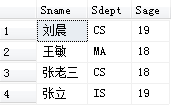
[例3.25] 查询年龄在20~23岁(包括20岁和23岁)之间的学生的姓名、系别和年龄
SELECT Sname, Sdept, Sage
FROM Student
WHERE Sage BETWEEN 20 AND 23;
[例3.26] 查询年龄不在20~23岁之间的学生姓名、系别和年龄
SELECT Sname, Sdept, Sage
FROM Student
WHERE Sage NOT BETWEEN 20 AND 23;
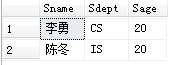
[例3.27]查询计算机科学系(CS)、数学系(MA)和信息系(IS)学生的姓名和性别。
SELECT Sname, Ssex
FROM Student
WHERE Sdept IN ('CS','MA','IS');
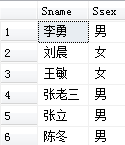
[例3.28]查询既不是计算机科学系、数学系,也不是信息系的学生的姓名和性别。
SELECT Sname, Ssex
FROM Student
WHERE Sdept NOT IN ('IS','MA','CS');
感想:做了大概一个半小时,可能是因为我这网不太好,SQL serever和标准数据库语言还是有很多不同的,有时候搜索资料就很慢(估计大周一都在上网课)。我自己打字也很慢(真的特别慢,还是要练)。虽说不要求截图了,但是我感觉自己回头再看会比较方便。中间遇到了问题还卡了一会,后来问了老师也在网上搜索了一下。基本都能理解,没有什么太大的问题。总之还是要继续努力,加油ヾ(◍°∇°◍)ノ゙
