【读书笔记】Python3 《机器学习实战》 k近邻算法改进约会网站的配对效果
书中用Python2实现。用Python3的话,一些命名方式,方法需要修改。
注释包括中英文,先英后中,中英之间空一行。
1. 创建py文件
首先创建一个python文件,命名为kNN.py,并输入以下代码来import这些模块。这些在之后的函数中会有用到。
from numpy import *
import operator
import matplotlib.pyplot as plt
from os import listdir
2. k-近邻算法函数
继续在kNN.py 文件中输入以下代码
与Python2 的主要不同:字典的.iteritems()方法在Python3中被删除,故用.items()替代。
参数说明(四个):
-
in_x: 是一个vector。 需要进行分类的向量。
-
data_set: 是一个matrix。训练的样本数据集。如果其有m行n列,那么共有m个数据,每个数据有n个特征值。
-
labels: 是一个vector。为样本分类的标签向量,挨个顺序对应data_set, 所以其元素数量与data_set的行数相同。
-
k: 是一个scalar。用于选择近邻的数据的数量。
def classify0(in_x, data_set, labels, k):
# 1 calculate distance
# 1 计算距离
## data_set rows number, which means the number of data, scalar
## data_set 的行数,意味着有多少个数据,是标量
data_set_size = data_set.shape[0]
## copy "in_x" by "data_set_size" times on row,
## and 1 time on column. Then get the difference between
## "in_x" to each element in "data_set"
## 把向量 "in_x" 在行方向上复制 "data_set_size" 次,
## 在列方向上复制1次,然后计算 in_x 与 "data_set" 每个数据之间的差,
## 用于之后的距离计算
diff_mat = tile(in_x, (data_set_size, 1)) - data_set
## below are the processes to calculate Euclidean distance
## 下面是利用上边的差计算欧几里得距离的过程
sq_diff_mat = diff_mat**2
### "axis=1" means summing for each row
### "axis=1" 意味着每一行内部自身求和
sq_distances = sq_diff_mat.sum(axis=1)
distances = sq_distances**0.5
# 2 get ascending sorted distance's index
# 2 按升序把距离排序,排好序后显示的为索引值,非距离值
sorted_dist_indices = distances.argsort()
# 3 choose the first k smallest distances by using a dictionary to record
# 3 选择前k个距离最近的点,通过字典来记录
class_count = {}
for i in range(k):
vote_label = labels[sorted_dist_indices[i]]
class_count[vote_label] = class_count.get(vote_label, 0) + 1
# 4 sort labels by frequency by descending order
# 4 按label出现的次数降序排序
sorted_class_count = sorted(class_count.items(),
## use operator.itemgetter(1) to sort
## by the second element,
## which is the value in the dictionary
## 使用operator.itemgetter(1)对第二个元素排序,
## 也就是字典中的value
key=operator.itemgetter(1),
## sort by descending order
##降序排序
reverse=True)
## return the label with the most appearence
## 返回出现次数最多的标签,可能是标量,字符串等等
return sorted_class_count[0][0]
3. 将txt文件内数据转换为Numpy格式数据的函数
同理,以下所有小节代码都在kNN.py 文件中输入,不再赘述
与书中代码不同的说明:因为之后要打开的两个文件的标签不一致,一个是数字标签,一个是文字标签,故与书中稍有不同。
参数说明(一个):
- filename: 是一个string。要打开的文件的全名,需要包含后缀名,例如: ‘datingTestSet2.txt’ 。该文件需要与kNN.py放在同一目录,才能在默认情况下打开。
def file2matrix(filename):
fr = open(filename)
# return a list which includes all lines
# 返回列表,元素是每行的数据
array_of_lines = fr.readlines()
number_of_lines = len(array_of_lines)
# create a matrix having "number_of_lines" rows and 3 columns,
# whose elements are all zeros.
# 创建一个元素全为0,"number_of_lines" 行,3列的矩阵
return_mat = zeros(number_of_lines, 3))
class_label_vector = []
index = 0
# below are some differences comparing codes in books,
# which are illustrated at begining of this chapter
# 下边的与书中的代码不同, 在本小节的开头有说明
labels = {'didntLike': 1, 'smallDoses: 2, 'largeDoses': 3}
for line in array_lines:
# delete space on two side
# 删除每行两边的空白符
line = line.strip()
# delete horizontal tabs between each element
# 删除行内各元素间的横向制表符,并返回list
list_from_line = line.split('\t')
# copy the three features of each data
# 复制每个数据的三个所有特征
return_mat[index, :] = list_from_line[0:3]
if list_from_line[-1] not in ['1', '2', '3']:
class_label_vector.append(int(labels[list_from_line[-1]]))
else:
class_label_vector.append(int(list_from_line[-1]))
index += 1
# return two values, a numpy matrix with data features and a list with data labels
# 返回两个值, 一个是数据特征值的numpy的矩阵,另一个是数据标签的的list
return return_mat, class_label_vector
4. 使用Matplotlib创建散点图,对数据有更直观印象
在 kNN.py 中创建 main 函数,输入如下代码:
def main():
dating_data_mat, dating_labels = file2matrix('datingTestSet2.txt')
# return a figure instance
# 返回一个图形实例
fig = plt.figure()
# divide canvas into 1 row 1 1 column,
# draw the picture at the first row first column.
# 将画布分割成1行1列,图像画在从左到右从上到下第1块
ax = fig.add_subplot(111)
# draw points by using the second and third features,
# whose sizes and colours are depending on its label
# 把第二列和第三列的特征值画到画布上。根据数据的标签,决定点的颜色和大小。
ax.scatter(dating_data_mat[:, 1], dating_data_mat[:, 2],
15.0*array(dating_labels),15*array(dating_labels))
# show the figure
# 展示图像
plt.show()
if __name__ == "__main__":
main()
然后运行kNN.py,得到如下图像: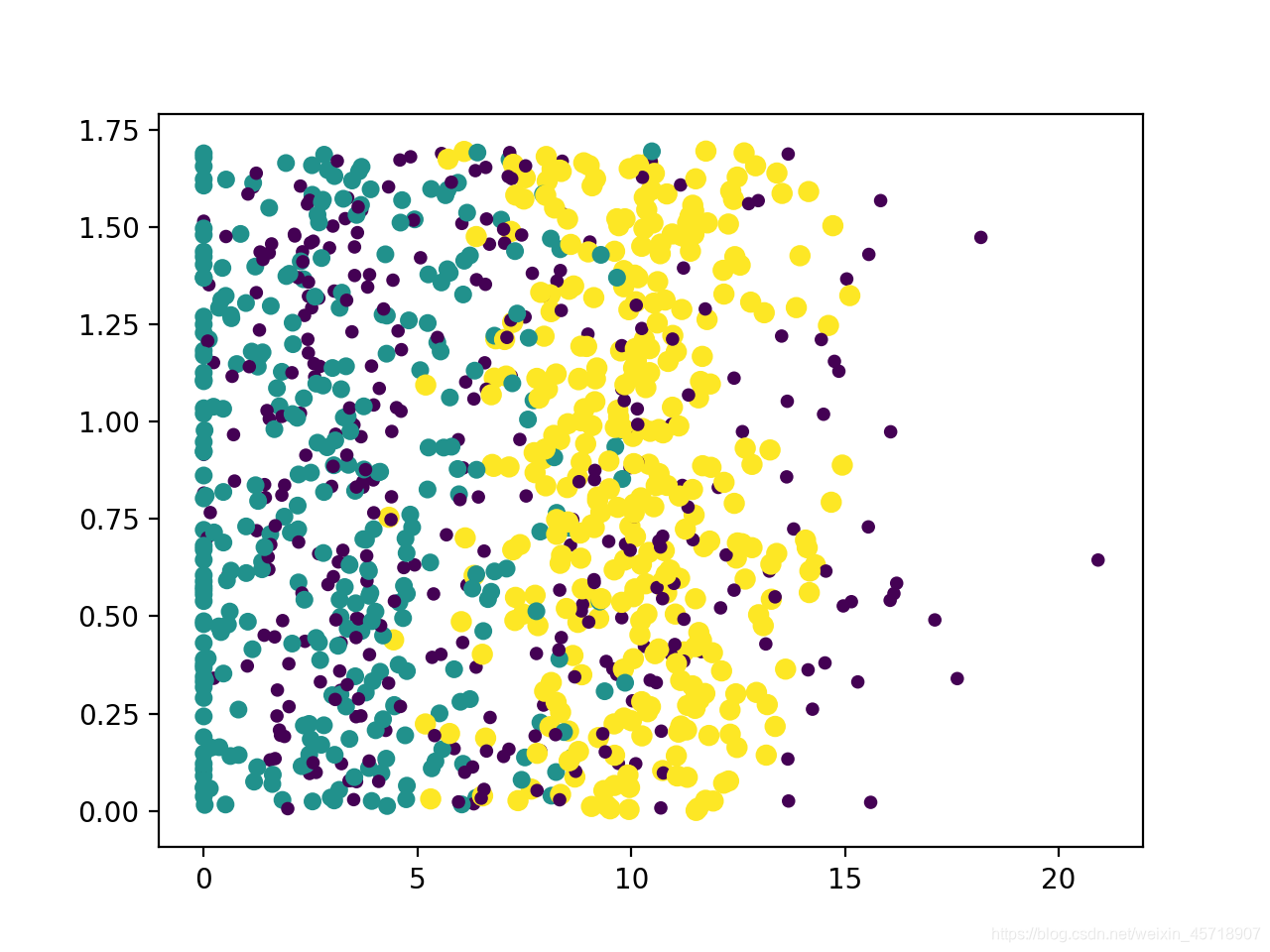
换成第一列和第二列属性,获得更好的展示效果,把上边代码中ax.scatter() 的方法改写成如下:
ax.scatter(dating_data_mat[:, 0], dating_data_mat[:, 1],
15.0*array(dating_labels), 15.0*array(dating_labels))
保存后运行kNN.py,得到如下图: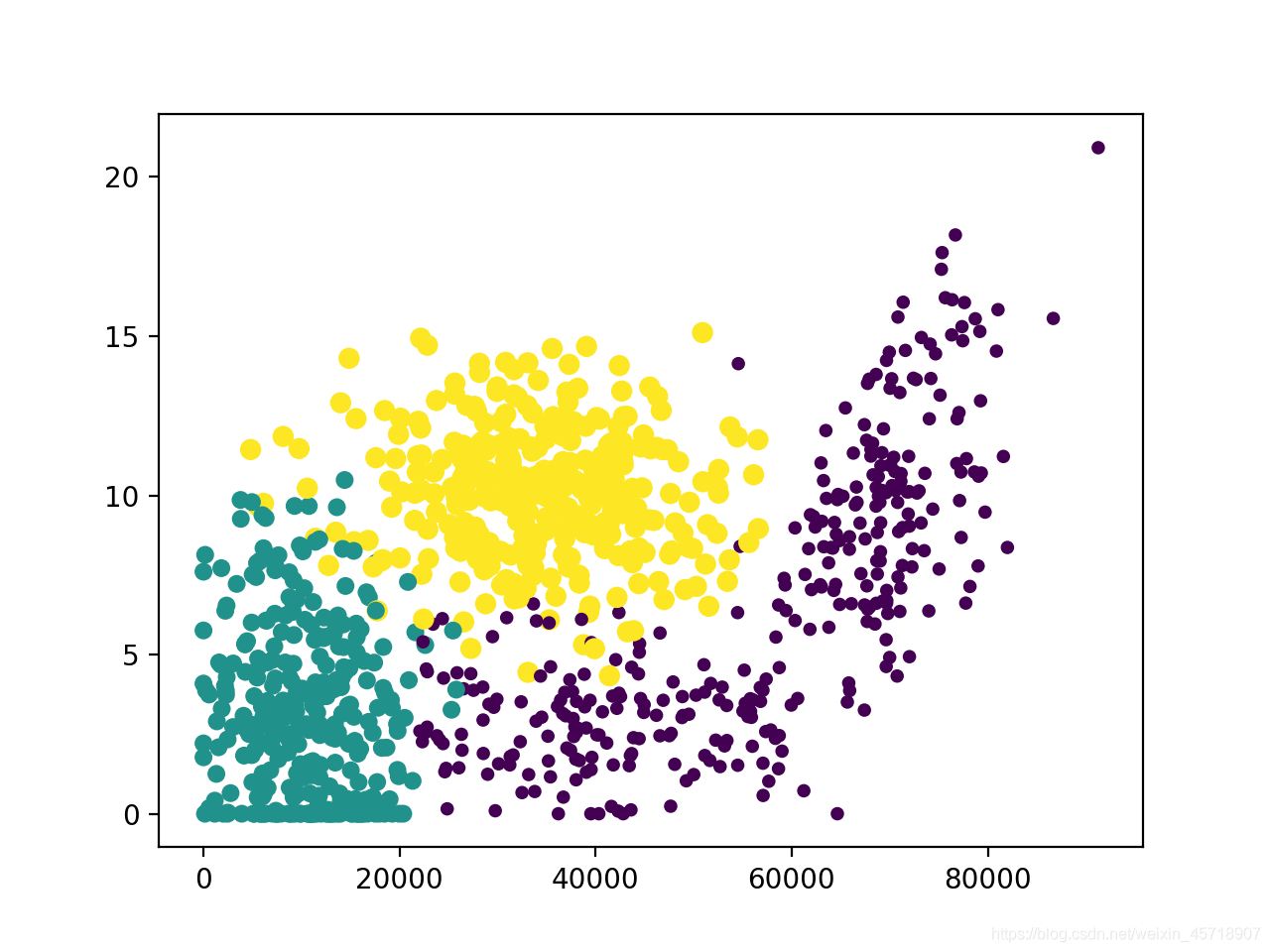
5. 归一化特征值函数
参数说明(一个):
- data_set: 是个matrix。需要进行归一处理的特征值矩阵。
def auto_norm(data_set):
# min value in each column
# 取得每列的最小值,返回一个向量
min_values = data_set.min(0)
# max value in each column
# 同理,取得每列的最大值。
max_values = data_set.max(0)
ranges = max_values - min_values
# number of rows
# 返回行数
m = data_set.shape[0]
norm_data_set = data_set - tile(min_values, (m, 1))
norm_data_set = norm_data_set/tile(ranges, (m, 1))
# return three values, normalised data set matrix, ranges vector
# and minimal values vector
# 返回三个值,归一化处理后的数据集矩阵,各特征范围向量,各特征最小值向量
return norm_data_set, ranges, min_values
6. 测试函数
参数说明:无
def dating_class_test():
# test percentage
# 测试集占的比例
ho_ratio = 0.10
# get data features matix and labels vector
# 获得数据特征值矩阵和标签向量
dating_data_mat, dating_labels = file2matrix('datingTestSet.txt')
# normalise data set features
# 归一化特征值
norm-mat, ranges, min_values = auto_norm(dating_data_mat)
# get number of rows(datas) in data set
# 获得数据集的行数(数据的个数)
m = norm_mat.shape[0]
# test data numbers
# 测试数据的数量
num_test_vectors = int(m*ho_ratio)
# error rate
# 错误率
error_count = 0.0
# input each test data to get result, record error rate
# 输入每个测试数据并获得结果, 记录错误率
for i in range(num_test_vectors):
classifier_result = classify0(norm_mat[i, :],
norm_mat[num_test_vector:m, :],
dating_labels[num_test_vectors:m],
3)
print("the classifier came back with: %d, the real answer is: %d"
% (classifier_result, dating_labels[i]))
if classifier_result != dating_labels[i]:
error_count += 1.0
print("the total error rate is: %f" % (error_count/float(num_test_vectors)))
运行kNN.py 文件,在 Shell 输入以下代码:
>>> dating_class_test()
按回车,得到结果如下输出结果:
the classifier came back with: 3, the real answer is: 3
the classifier came back with: 2, the real answer is: 2
the classifier came back with: 1, the real answer is: 1
the classifier came back with: 1, the real answer is: 1
the classifier came back with: 1, the real answer is: 1
the classifier came back with: 1, the real answer is: 1
the classifier came back with: 3, the real answer is: 3
the classifier came back with: 3, the real answer is: 3
the classifier came back with: 1, the real answer is: 1
the classifier came back with: 3, the real answer is: 3
the classifier came back with: 1, the real answer is: 1
the classifier came back with: 1, the real answer is: 1
the classifier came back with: 2, the real answer is: 2
the classifier came back with: 1, the real answer is: 1
the classifier came back with: 1, the real answer is: 1
the classifier came back with: 1, the real answer is: 1
the classifier came back with: 1, the real answer is: 1
the classifier came back with: 1, the real answer is: 1
the classifier came back with: 2, the real answer is: 2
the classifier came back with: 3, the real answer is: 3
the classifier came back with: 2, the real answer is: 2
the classifier came back with: 1, the real answer is: 1
the classifier came back with: 3, the real answer is: 2
the classifier came back with: 3, the real answer is: 3
the classifier came back with: 2, the real answer is: 2
the classifier came back with: 3, the real answer is: 3
the classifier came back with: 2, the real answer is: 2
the classifier came back with: 3, the real answer is: 3
the classifier came back with: 2, the real answer is: 2
the classifier came back with: 1, the real answer is: 1
the classifier came back with: 3, the real answer is: 3
the classifier came back with: 1, the real answer is: 1
the classifier came back with: 3, the real answer is: 3
the classifier came back with: 1, the real answer is: 1
the classifier came back with: 2, the real answer is: 2
the classifier came back with: 1, the real answer is: 1
the classifier came back with: 1, the real answer is: 1
the classifier came back with: 2, the real answer is: 2
the classifier came back with: 3, the real answer is: 3
the classifier came back with: 3, the real answer is: 3
the classifier came back with: 1, the real answer is: 1
the classifier came back with: 2, the real answer is: 2
the classifier came back with: 3, the real answer is: 3
the classifier came back with: 3, the real answer is: 3
the classifier came back with: 3, the real answer is: 3
the classifier came back with: 1, the real answer is: 1
the classifier came back with: 1, the real answer is: 1
the classifier came back with: 1, the real answer is: 1
the classifier came back with: 1, the real answer is: 1
the classifier came back with: 2, the real answer is: 2
the classifier came back with: 2, the real answer is: 2
the classifier came back with: 1, the real answer is: 1
the classifier came back with: 3, the real answer is: 3
the classifier came back with: 2, the real answer is: 2
the classifier came back with: 2, the real answer is: 2
the classifier came back with: 2, the real answer is: 2
the classifier came back with: 2, the real answer is: 2
the classifier came back with: 3, the real answer is: 3
the classifier came back with: 1, the real answer is: 1
the classifier came back with: 2, the real answer is: 2
the classifier came back with: 1, the real answer is: 1
the classifier came back with: 2, the real answer is: 2
the classifier came back with: 2, the real answer is: 2
the classifier came back with: 2, the real answer is: 2
the classifier came back with: 2, the real answer is: 2
the classifier came back with: 2, the real answer is: 2
the classifier came back with: 3, the real answer is: 3
the classifier came back with: 2, the real answer is: 2
the classifier came back with: 3, the real answer is: 3
the classifier came back with: 1, the real answer is: 1
the classifier came back with: 2, the real answer is: 2
the classifier came back with: 3, the real answer is: 3
the classifier came back with: 2, the real answer is: 2
the classifier came back with: 2, the real answer is: 2
the classifier came back with: 3, the real answer is: 1
the classifier came back with: 3, the real answer is: 3
the classifier came back with: 1, the real answer is: 1
the classifier came back with: 1, the real answer is: 1
the classifier came back with: 3, the real answer is: 3
the classifier came back with: 3, the real answer is: 3
the classifier came back with: 1, the real answer is: 1
the classifier came back with: 2, the real answer is: 2
the classifier came back with: 3, the real answer is: 3
the classifier came back with: 3, the real answer is: 1
the classifier came back with: 3, the real answer is: 3
the classifier came back with: 1, the real answer is: 1
the classifier came back with: 2, the real answer is: 2
the classifier came back with: 2, the real answer is: 2
the classifier came back with: 1, the real answer is: 1
the classifier came back with: 1, the real answer is: 1
the classifier came back with: 3, the real answer is: 3
the classifier came back with: 2, the real answer is: 3
the classifier came back with: 1, the real answer is: 1
the classifier came back with: 2, the real answer is: 2
the classifier came back with: 1, the real answer is: 1
the classifier came back with: 3, the real answer is: 3
the classifier came back with: 3, the real answer is: 3
the classifier came back with: 2, the real answer is: 2
the classifier came back with: 1, the real answer is: 1
the classifier came back with: 3, the real answer is: 1
the total error rate is: 0.050000
>>>
可知错误率为5%
7. 使用算法,约会网站预测函数,构建完整可用系统
参数说明:无
def classify_person():
result_list = ['not at all', 'in small doses', 'in large doses']
percent_tats = float(input("percentage of time spent playing video game?"))
ff_miles = float(input("frequent flier miles earned per year?"))
ice_cream = float(input("liters of ice cream consumed per year?"))
dating_data_mat, dating_labels = file2matrix('datingTestSet2.txt')
norm_mat, ranges, min_values = auto_norm(dating_data_mat)
# create input numpy array
# 创建输入numpy向量
in_arr = array([ff_miles, percent_tats, ice_cream])
classifier_result = classify0((in_arr-min_values)/ranges,
norm_mat, dating_labels, 3)
print("You will probably like this person: ",
result_list[classifier_result - 1])
运行kNN.py 文件,输入以下代码:
>>> classify_person()
并按回车,会出现问题,并按着如下示例数据依次输入,获得最后的预测结果 “in small doses”
percentage of time spent playing video games?10
frequent flier miles earned per year?10000
liters of ice cream consumed per year?0.5
You will probably like this person: in small doses
>>>
