嵌入式学习基础-数据结构链表的基本操作
一,链表的简介
链表是嵌入式开发人员必不可少的一项数据结构,在较为庞大的开发场合被广泛使用。
我们知道,数组是最基本的数据结构。结构体的出现是为了解决数组内部数据类型单一的问题。而链表的出现是为了解决数组的不可扩展性(只有一开始规定的大小),其主要通过结构体以及指针实现。
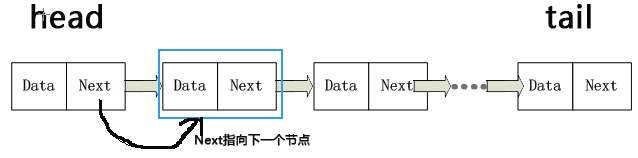
链表节点采用结构体的方式进行定义,下面是其最基础的定义方式,只有一个数据data,*pNext用于指向下一个节点(若为尾节点则指向NULL)。
//链表节点
struct node
{
int data;
struct node *pNext; //用于指向下一个节点
};链表的学习相对来说是用于对于C语言的进阶。在学习之前你必须对C语言基础有足够的了解,如函数,结构体,指针,结构体指针,内存组成,库函数的调用有一定的了解。读者可自行选择深入学习。
- 看代码不是一朝一夕之功,对于一些自己没接触过的东西要敢于发挥更多的时间去研究,只有这样你的努力才能真正的发挥到作用。
二,关于链表的操作解析(含代码)
代码的声明先在下面列出,完整main函数在最下面。
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
//链表节点
struct node
{
int data;
struct node *pNext;
};
int main(void)
{
struct node *pHeader = NULL; //头指针
pHeader = create_node(0); //创建头节点,头指针指向头节点- 注:本链表拥有头节点,用于存储有效链表的个数。
1,创建节点
制作链表最基础的是学会创建节点,链表需要内存,不过在这里系统不会自动给我们分配,我们必须自己获取。通过使用malloc分配堆内存作为各节点的存放地址(因此在删除节点时必须要记得free()释放该内存,否则会造成内存泄漏)。
//创建链表,返回值为链表节点类型
struct node * create_node(int data)
{
struct node *p = (struct node *)malloc(sizeof(struct node)); //在堆中给指针p分配空间
if(NULL == p)
{
printf("malloc error.\n");
return NULL;
}
memset(p,0,sizeof(struct node)); //清理从堆中分配的内存
p->data = data;
p->pNext = NULL;
return p;
}
- 注:为保证获取的堆内存干净必须先用memset清理。
2,插入节点
插入节点主要包括头插和尾插,其操作主要注意的是节点的指向问题。头插时一定要注意先保存第一个有效节点的地址起再指向新节点。

//在链表尾部插入节点;*pH为头指针 *new为要插入的节点
void inster_tail(struct node *pH,struct node *new)
{
struct node *p=pH;
while(NULL != p->pNext) //找到最后一个节点
{
p = p->pNext;
}
p->pNext = new;
pH->data += 1; //头节点(用于保存节点总数)加1
}
//在链表头部插入节点;*pH为头指针 *new为要插入的节点
void inster_head(struct node *pH,struct node *new)
{
new->pNext = pH->pNext;
pH->pNext = new;
pH->data += 1; //头节点(用于保存节点总数)加1
}3,查找第n个节点数据
通过该函数可辅助完成很多关于链表的算法问题。
//找到链表中的第n个节点数据,并作为返回值
int find_n_node(struct node *pH,int n)
{
struct node *p=pH;
int i=0;
while(NULL != p->pNext)
{
i++;
p = p->pNext;
if(i==n)
return p->data;
}
printf("without this node");
return -1;
}4,遍历链表
从头到尾打印链表内数据。
//链表的遍历
void bianli(struct node *pH)
{
struct node *p=pH;
printf("---%d---\n",p->data); //头节点,存储着节点数
while(NULL != p->pNext)
{
p = p->pNext;
printf("%d\n",p->data);
}
}5,删除链表
通过声明一个指针变量指向当前节点的前一个节点,从而达到新链表能够链接的目的。
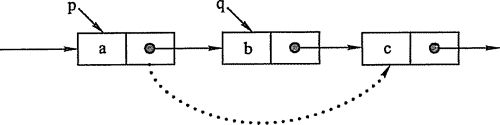
//删除链表中指定值为data的第一个节点
int delete_node(struct node *pH,int data)
{
struct node *pPrev = pH; //指向当前节点的前一个节点
struct node *p = pH->pNext; //当前节点
while(data != p->data && NULL != p->pNext)
{
pPrev = p;
p = p->pNext;
}
if(data == p->data) //找到为data值的节点
{
pPrev->pNext = p->pNext; //将要删除节点相邻的两个节点连接
free(p);
pH->data -= 1; //头节点(用于保存节点总数)减1
return 0;
}
else
{
printf("can not find node");
return -1;
}
}6,倒序链表
涉及到部分的算法知识,本例只做参考,可自行思考别的操作思路。
- 看懂代码终究只是看懂,和自己写或许是两码事,学会用自己不同的思路去解决同一个问题很重要。
//链表逆序
void nixu(struct node *pH)
{
struct node *p = pH->pNext;
struct node *pBack;
//没有有效节点或一个则不操作
if ((NULL ==p) || (NULL == p->pNext))
return;
while(NULL != p->pNext)
{
pBack = p->pNext;
//如果是第一个节点则指向NULL(逆序后为最后一个节点)
if(p == pH->pNext)
{
p->pNext=NULL;
}
else
{
p->pNext=pH->pNext; //当前节点指向头节点指向的节点
}
pH->pNext=p; //头节点指向当前节点
p = pBack; //指向下一个节点
}
inster_head(pH,p); //最后一个使用函数头插实现
}
7,主函数
主函数主要是调用前面的函数,用于对结果的验证。
int main(void)
{
struct node *pHeader = NULL; //头指针
pHeader = create_node(0);
inster_tail(pHeader,create_node(12)); //尾插12
inster_tail(pHeader,create_node(123)); //尾插123
inster_tail(pHeader,create_node(1234)); //尾插1234
inster_head(pHeader,create_node(1)); //头插1
printf("%d\n",find_n_node(pHeader,3)); //打印第三个节点
bianli(pHeader); //遍历链表
delete_node(pHeader,1234); //删除值为1234的节点
nixu(pHeader); //逆序
bianli(pHeader); //遍历
}执行结果,使用Linux的gcc编译器。

3,结叙
本博客只针对链表的最基本操作而讲解,如有错误欢迎指出。通过这些基础知识再结合一些算法即可完成链表的很多附加操作,在这里就不一一举例。C语言算法篇会在后续陆续发出。
关于链表的排序算法可参考:
https://blog.csdn.net/weixin_44313435/article/details/104388677
