介绍
优化上一个挑战中完成的计算器,完善下述需求:
- 使用
getopt模块处理命令行参数 - 使用 Python3 中的
configparser模块读取配置文件 - 使用
datetime模块写入工资单生成时间
计算器执行中包含下面的参数:
-h 或 --help,打印当前计算器的使用方法,内容为:

-C 城市名称指定使用某个城市的社保配置信息,如果没有使用该参数,则使用配置文件中[DEFAULT]栏目中的数据,城市名称不区分大小写,比如配置文件中写的是[CHENGDU],这里参数可以写-C Chengdu,仍然可以匹配-c 配置文件配置文件,由于各地的社保比例稍有不同,我们将多个城市的不同配置信息写入一个配置文件-d 员工工资数据文件指定员工工资数据文件,文件中包含两列内容,分别为员工工号和工资金额-o 员工工资单数据文件输出内容,将员工缴纳的社保、税前、税后工资等详细信息输出到文件中
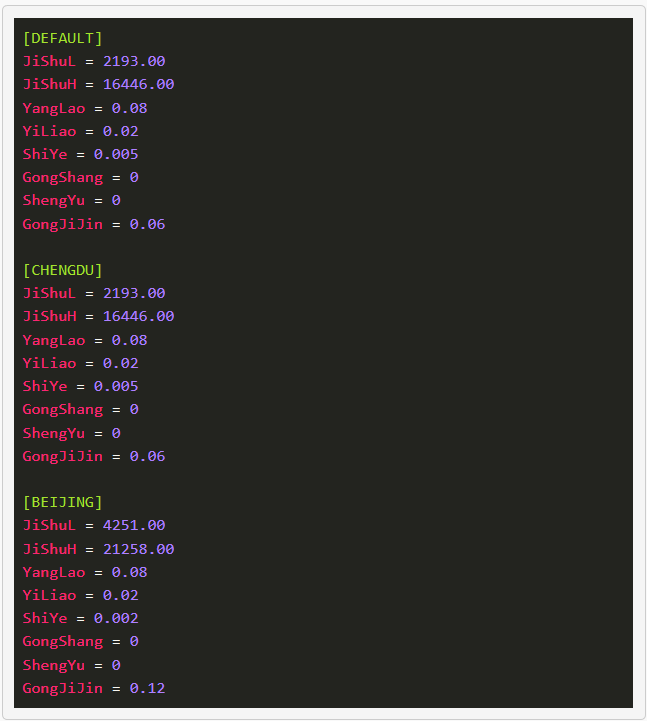
配置文件格式如下,数字不一定非常准确,仅供参考:
员工工资数据文件格式每行为 工号,税前工资,举例如下:

输出的员工工资单数据文件每行格式为 工号,税前工资,社保金额,个税金额,税后工资,计算时间如下:

计算时间为上一挑战中实现的多进程代码中的进程2计算的时间,格式为 年-月-日 小时:分钟:秒。
程序的执行过程如下,注意配置文件和输入的员工数据文件需要你自己创建并填入数据,可以参考上述的内容示例:

目标
完成任务需要达成的目标:
- 程序存放的位置
/home/shiyanlou/calculator.py - 能够正确处理程序的参数,参数不准确需要返回错误信息并打印使用方法
提示语
上一节中我们学习了几个常用的模块,但没有讲 getopt 及 configparser 模块,这两个模块的内容需要你自己阅读官方文档学习并在本次挑战中实践使用,遇到问题欢迎随时与讨论组中的助教交流,助教会引导你去阅读一些内容,帮助你避免走弯路,但不会告诉你最终答案,仍然需要你自己独立完成。
下述实现方案仅供参考,会涉及到先前实验中学习到的知识点,如果自己对程序有足够的理解也可以不按照下述提示编写
- 基于 getopt 模块处理程序的参数
- 基于 configparser 实现配置文件的读取
- 基于 datetime 返回数据计算的时间
- 最后,如果你希望保存自己的程序,可以将代码提交到自己的 Github 账号中
知识点
- Python3 模块使用
- getopt 处理命令行参数
- configparser 读取配置文件
- datetime 格式化输出时间
通过代码:(注意,本代码在判断城市上并选择默认方案上并不完善)
#!/usr/bin/env python3 # _*_ coding: utf-8 _*_ import sys import csv import getopt from configparser import ConfigParser from multiprocessing import Process,Queue from datetime import datetime class Brgs: def __init__(self): try: opts,args = getopt.getopt(sys.argv[1:], "C:c:d:o:") global x x = [] for optname in opts: a,b = optname x.append(b) # print(x) except getopt.GetoptError: print("Usage:calculator.py -C cityname -c configfile -d userdata -o resultdata") #brgs = Brgs() class Config: def __init__(self): self.config = self._read_config() def _read_config(self): l = sys.argv[1:] c_conf = l[l.index('-c') + 1] C_city = l[l.index('-C') + 1].upper() C_city = repr(C_city) #print(C_city) d = {'s': 0} with open(c_conf) as f: conf = ConfigParser() conf.read(c_conf) city = conf.sections() #print(1) #if x[0] in city:#== 'CHENGDU' or C_city == 'BEIJING': # print(2) op = conf.items("CHENGDU") for line in op: #for m in line: #m = line.split(',') a, b = line[0].strip(),line[1].strip() # print(a,b) if a == 'jishul' or a == 'jishuh': d[a] = float(b) else: d['s'] += float(b) #print(d) return d #config = Config() def f2(q2,q1): for a,b in q1.get(): starttime = datetime.now().strftime('%Y-%m-%d %H:%M:%S') salary = int(b) shebao = salary * config['s'] if salary < config['jishul']: shebao = config['jishul'] * config['s'] if salary > config['jishuh']: shebao = config['jishuh'] * config["s"] m = salary - shebao - 3500 if m <= 0: shui = 0 elif m <= 1500: shui = m * 0.03 elif m <= 4500: shui = m * 0.1-105 elif m <= 9000: shui = m * 0.2-555 elif m <= 35000: shui = m * 0.25-1005 elif m <= 55000: shui = m * 0.3-2755 elif m <= 80000: shui = m * 0.35-5505 else: shui = m * 0.45-13505 shuihou = salary - shebao - shui # endtime = datetime.now().strftime('%Y-%m-%d %H:%M:%S') # caltime = endtime - starttime # caltime.strftime('%Y-%m-%d %H:%M:%S') newdata1 = [a,salary, format(shebao, '.2f'), format(shui, '.2f'), format(shuihou, '.2f'),starttime] # time.sleep(0.01) newdata.append(newdata1) q2.put(newdata) def f1(q1): #d_conf = l[l.index('-d') + 1] with open(x[2]) as f: data = list(csv.reader(f)) q1.put(data) def f3(q2): #o_conf = l[l.index('-o') + 1] with open(x[3], 'w') as f: for w in q2.get(): csv.writer(f).writerow(w) def main(): Process(target=f1, args=(queue1,)).start() Process(target=f2, args=(queue2, queue1)).start() Process(target=f3, args=(queue2,)).start() if __name__ == '__main__': queue1 = Queue() queue2 = Queue() brgs = Brgs() config = Config().config newdata = [] main()