不积跬步,无以至千里;不积小流,无以成江海。
----荀子《劝学》
Dropout发展史:

标准dropout:

从数学上来说,神经网络层训练过程中使用的标准 Dropout 的行为可以被写作:
![]()
其中 f(·)为激活函数,x 是该层的输入,W 是该层的权值矩阵,y为该层的输出,而 m 则为该层的 Dropout 掩膜(mask),mask 中每个元素为 1 的概率为 p。
在测试阶段,该层的输出可以被写作:
![]()
DropConnect:

DropConnect的行为可以被写作:
![]()
其中 f(·)为激活函数,x 是该层的输入,W 是该层的权值矩阵,y为该层的输出,而M则为该层的weights对应的DropConnect掩膜(mask),mask 中每个元素为 1 的概率为 p。
DropConnect的训练和测试过程:

训练时和dropout的区别在于,dropout是对当前节点的输出进行drop操作,而DropConnect是对当前节点的输入权重进行drop操作。
测试时dropout对所有的权重W都scale一个系数p,而DropConnect进行推理时,采用的是对每个输入(每个隐含层节点连接有多个输入)的权重进行高斯分布的采样。该高斯分布的均值与方差当然与前面的概率值p有关
测试时速度上,dropout快于DropConnect,因为DropConnect需要进行Z次的样本采样。
精度上,DropConnect的效果应该比dropout好,因为,本质上,两者都是一种模型集成,求平均的思想。Dropout集成的模型是m个,存在2|m|种组合,DropConnect集成的模型是M个。M和网络当前节点的输出大小一样,M和网络当前节点的权重weights大小一样,存在 2|M|种组合。对于全连接层来说,|M|>|m|。DropConnect集成度更好,因此效果会更好。(m是向量,M是矩阵,取模表示矩阵或向量中对应元素的个数)
Fast dropout:
如下面的式子所示,训练时候,Fast dropout和标准dropout的区别在于,m是基于W的高斯函数得到的。其中g(·)表示激活函数。α和 β表示高斯函数的均值和方差。
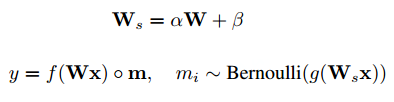
测试的时候和标准dropout也很类似,只不过概率p是经过高斯函数结合当前输入计算出的。
![]()
Fast dropout相比dropout可以极大的加速。因为dropout每次只以概率p进行采样,需要连续训练迭代多次,才可以将整个样本都采样全。而Fast dropout每一次的迭代都是所有样本都参与了计算。因此可以获得加速比。
Dropout 的实现方式
Dropout的实现方式有两种。
Dropout:(使用较少, AlexNet使用的是这种Dropout,At test time, we use all the neurons but multiply their outputs by 0.5, which is a reasonable approximation to taking the geometric mean of the predictive distributions produced by the exponentially-many dropout networks)
训练阶段:
drop_ratio:随机drop的概率
retain_prob =1- drop_ratio: 保留该神经元的概率。
Sample = np.random.binomial(n=1,p=retain_prob,size=x.shape)
x = x * Sample
测试阶段: 计算的结果需要乘以x = x * retain_prob:
Inverted Dropout:(目前常用的方法):
训练阶段:
drop_ratio:随机drop的概率
retain_prob =1- drop_ratio: 保留该神经元的概率。
Sample = np.random.binomial(n=1,p=retain_prob,size=x.shape)
x=x * Sample/ retain_prob
测试阶段: x = x
Python 版本的dropout函数实现:
def dropout(x, level):
if level < 0. or level >= 1:#level是概率值,必须在0~1之间
raise Exception('Dropout level must be in interval [0, 1].')
retain_prob = 1. - level
#我们通过binomial函数,生成与x一样的维数向量。binomial函数就像抛硬币一样,我们可以把每个神经元当做抛硬币一样
#硬币 正面的概率为p,n表示每个神经元试验的次数
#因为我们每个神经元只需要抛一次就可以了所以n=1,size参数是我们有多少个硬币。
sample=np.random.binomial(n=1,p=retain_prob,size=x.shape)#即将生成一个0、1分布的向量,0表示这个神经元被屏蔽,不工作了,也就是dropout了
print (sample)
x *=sample#0、1与x相乘,我们就可以屏蔽某些神经元,让它们的值变为0
print (x)
x /= retain_prob
return x
#对dropout的测试,大家可以跑一下上面的函数,了解一个输入x向量,经过dropout的结果
x=np.asarray([1,2,3,4,5,6,7,8,9,10],dtype=np.float32)
dropout(x,0.4)
keras中dropout实现:
https://github.com/keras-team/keras/blob/master/keras/backend/theano_backend.py
def dropout(x, level, noise_shape=None, seed=None):
"""Sets entries in `x` to zero at random,
while scaling the entire tensor.
# Arguments
x: tensor
level: fraction of the entries in the tensor
that will be set to 0.
noise_shape: shape for randomly generated keep/drop flags,
must be broadcastable to the shape of `x`
seed: random seed to ensure determinism.
"""
if level < 0. or level >= 1:
raise ValueError('Dropout level must be in interval [0, 1[.')
if seed is None:
seed = np.random.randint(1, 10e6)
if isinstance(noise_shape, list):
noise_shape = tuple(noise_shape)
rng = RandomStreams(seed=seed)
retain_prob = 1. - level
if noise_shape is None:
random_tensor = rng.binomial(x.shape, p=retain_prob, dtype=x.dtype)
else:
random_tensor = rng.binomial(noise_shape, p=retain_prob, dtype=x.dtype)
random_tensor = T.patternbroadcast(random_tensor,
[dim == 1 for dim in noise_shape])
x *= random_tensor
x /= retain_prob
return x
caffe中dropout实现:
template <typename Dtype>
void DropoutLayer<Dtype>::LayerSetUp(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {//初始化
NeuronLayer<Dtype>::LayerSetUp(bottom, top);
threshold_ = this->layer_param_.dropout_param().dropout_ratio();
DCHECK(threshold_ > 0.);
DCHECK(threshold_ < 1.);
scale_ = 1. / (1. - threshold_);//inverted dropout中需要的1/(1-dropout_ratio)
uint_thres_ = static_cast<unsigned int>(UINT_MAX * threshold_);
}
template <typename Dtype>
void DropoutLayer<Dtype>::Reshape(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
NeuronLayer<Dtype>::Reshape(bottom, top);
// Set up the cache for random number generation
// ReshapeLike does not work because rand_vec_ is of Dtype uint
rand_vec_.Reshape(bottom[0]->shape());
}
template <typename Dtype>
void DropoutLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {//前向
const Dtype* bottom_data = bottom[0]->cpu_data();
Dtype* top_data = top[0]->mutable_cpu_data();
unsigned int* mask = rand_vec_.mutable_cpu_data();//mask表示对应位置的像素是否被drop,内部元素取值为0,1,类型和bottom[0],top[0]一样,都是Blob类型。区别在于mask是unsigned int类型,bottom和top是Dtype类型。
const int count = bottom[0]->count();
if (this->phase_ == TRAIN) {
// Create random numbers
caffe_rng_bernoulli(count, 1. - threshold_, mask);//训练中每次都重新生成drop的mask
for (int i = 0; i < count; ++i) {
top_data[i] = bottom_data[i] * mask[i] * scale_;// x=x * Sample/ retain_prob
}
} else {
caffe_copy(bottom[0]->count(), bottom_data, top_data);
}
}
template <typename Dtype>
void DropoutLayer<Dtype>::Backward_cpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down,
const vector<Blob<Dtype>*>& bottom) {
if (propagate_down[0]) {
const Dtype* top_diff = top[0]->cpu_diff();
Dtype* bottom_diff = bottom[0]->mutable_cpu_diff();
if (this->phase_ == TRAIN) {
const unsigned int* mask = rand_vec_.cpu_data();
const int count = bottom[0]->count();
for (int i = 0; i < count; ++i) {
bottom_diff[i] = top_diff[i] * mask[i] * scale_;//返向传播的梯度跟新公式,和前向的很像,只跟新位置的梯度,为了保证均值和方差,也进行scale操作,所以很好理解。
}
} else {
caffe_copy(top[0]->count(), top_diff, bottom_diff);
}
}
}
Dropout作用:
- 和BN类似,防止模型过拟合,增加泛化性
- 可以利用dropout做模型压缩
- 可以利用dropout测试神经网络的不确定性
相关文献:
ImageNet Classification with Deep Convolutional
Improving neural networks by preventing co-adaptation of feature detectors
Improving Neural Networks with Dropout
Dropout: A Simple Way to Prevent Neural Networks from Overtting
Dropout Training as Adaptive Regularization
