参考:
https://blog.csdn.net/dream_188810/article/details/78870520
https://blog.csdn.net/soonfly/article/details/70238902
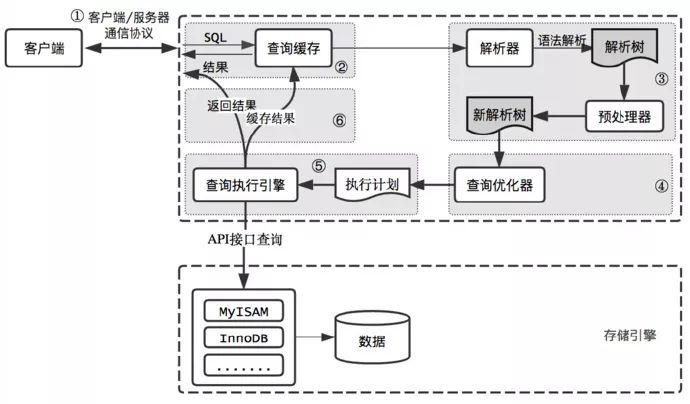
MySQL执行流程
监听到客户端(php/java/py等)请求连接 MySQL 服务器时,客户端会建立一个线程,而 MySQL 服务器有一个线程池(Connection Pool)接管这些连接。
mysql -u root -p -P 3306 -h 127.0.0.1
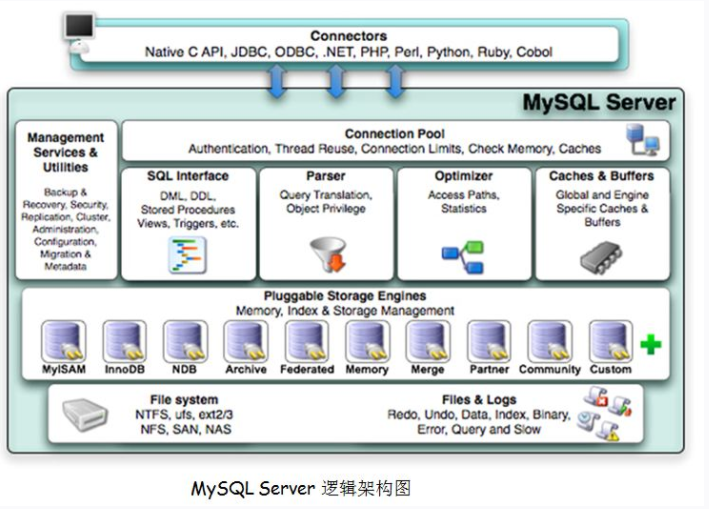
当有 sql 语句传入时:
SELECT * FROM `user` WHERE `id` = 1;
- sql 语句先会交由处理器(Management Serveices & Utilities)等待处理;
- 当该请求从等待队列进入到处理队列,管理器会将该请求丢给 SQL 接口(SQL Interface);
- (查询缓存): SQL 接口会进入【缓存器】进行命中,如果缓存命中成功,直接进入返回结果;
- 如果没有命中,SQL接口丢给后面的解释器(Parser),它判断SQL语句正确与否,正确则将其解析为数据结构,否则返回异常;
- 解释器将解析的数据结构交给后面的优化器(Optimizer),它会产生多种执行计划。
- 最终数据库确定一种最优执行计划后,此时便可以交由存储引擎(Engine)处理。
- 存储引擎将会到存储设备中取得相应的数据,并原路返回给程序。
MySQL 各个组件工作原理
线程池(Connection Pool)
- 每个客户端都会建立一个与服务器连接的线程,服务器会有一个线程池来管理这些连接。
- 如果客户端需要连接到MYSQL数据库还需要进行验证,包括用户名、密码、主机信息等。
处理器(Management Serveices & Utilities)
系统管理和控制工具。
SQL接口(SQL Interface)
用于接受SQL命令,和返回查询结果的对外处理接口。
解释器(Parser)
- SQL命令传递到解析器的时候会被解析器验证和解析,解析器是由Lex和YACC实现的,是一个很长的脚本。
- 将SQL语句分解成数据结构,并将这个结构传递到后续步骤,以后SQL语句的传递和处理就是基于这个结构的。
- 如果在分解构成中遇到错误,那么就说明这个sql语句是不合理的。
优化器(Optimizer)
- SQL语句在查询之前会使用查询优化器对查询进行优化。他使用的是“选取-投影-联接”策略进行查询。
- 用一个例子就可以理解: select uid,name from user where gender = 1;
- 这个select 查询先根据 where 语句进行选取,而不是先将表全部查询出来以后再进行 gender 过滤。
- 这个select查询先根据 uid 和 name 进行属性投影,而不是将属性全部取出以后再进行过滤。
- 将这两个查询条件联接起来生成最终查询结果。
缓存器(Cache & Buffer)
- 如果查询缓存有命中的查询结果,查询语句就可以直接去查询缓存中取数据。
- 这个缓存机制是由一系列小缓存组成的。比如表缓存,记录缓存,key缓存,权限缓存等。
插入式存储引擎(Pluggable Storage Engine)
数据库存储引擎负责创建、查询、更新和删除数据,不同的存储引擎提供不同的存储机制、索引技巧、锁定水平等功能,使用不同的存储引擎,还可以获得特定的功能。
Innodb vs MyISAM
存储引擎在MySQL的逻辑架构中位于第三层,负责MySQL中的数据的存储和提取,MySQL存储引擎有很多,不同的存储引擎保存数据和索引的方式是不同。
Innodb
- Innodb 存储引擎表默认使用独立表空间(vs 系统表空间)存储数据,即由 .frm 和 .idb 两个文件进行存储。
- 作为典型的事务型存储引擎,完全支持事务的 ACID 特性。(由 Redo Log 和 Undo Log 实现)
- 支持行级锁,锁的存在是为了处理并发问题,分为共享锁(读锁)和排他锁(写锁)。
适用:Innodb 始终是最优选择项。
MyISAM
- MyISAM 存储引擎表由 .frm(用于存储表结构).MYD(用于存储表数据) .MYI (存储表索引)组成。
- 使用表级锁而不是行级锁,所以并发写操作的处理效率差些(读操作时不阻塞末尾的插入数据)。
- 表损坏时可检查和修复:check table test; repair table test;
- 支持全文索引,是一种基于分词创建的索引,可以支持复杂的查询。
- 支持表压缩(压缩之后只读):myisampack -b -f \mysql\data\test\test.MYI
- MyISAM 不支持事务,不支持外键,不支持集群数据库。
适用:非事务型应用、静态类(即数据不经常更新/删除)、空间类应用。
锁
MyISAM 表锁
表共享读锁(Table Read Lock):当一个线程获得对一个表的写锁后,只有持有锁的线程可以对表进行更新操作,其他线程的读、写操作都会等待,直到锁被释放为止。
表独占写锁(Table Write Lock):当一个线程获得对一个表的读锁后,这个线程可以查询锁定表中的记录,但更新或访问其他表都会提示错误,其他线程可以查询表中的记录,但更新就会出现锁等待。
InnoDB 行锁
InnoDB的行锁是基于索引实现的,如果不通过索引访问数据,InnoDB会使用表锁。行锁带来的问题有 脏读(Dirty Reads)、不可重复读(Non-Repeatable Reads)、幻读(Phantom Reads)等问题。
为此可选择不同的事务隔离级别来保证数据的准确性:未提交读(Read uncommitted)、提交读(Read committed)、可重复读(Repeatable read,默认)、序列化(Serializable)。
共享锁(S):又称读锁。允许一个事务去读一行,阻止其他事务获得相同数据集的排他锁。若事务T对数据对象A加上S锁,则事务T可以读A但不能修改A,其他事务只能再对A加S锁,而不能加X锁,直到T释放A上的S锁。这保证了其他事务可以读A,但在T释放A上的S锁之前不能对A做任何修改。
排他锁(X):又称写锁。允许获取排他锁的事务更新数据,阻止其他事务取得相同的数据集共享读锁和排他写锁。若事务T对数据对象A加上X锁,事务T可以读A也可以修改A,其他事务不能再对A加任何锁,直到T释放A上的锁。
