自定义函数UDF
虽然hive已经提供了足够多的内置函数供我们使用,但是有时候需要自己去写函数来处理业务数据。
以官方给的UDF例子来说明,代码如下
创建一个将字符串转换成小写的函数,Lower类需要继承UDF类,并在Lower类定义访问类型为public方法名为evaluate的函数
package com.utstar.patrick;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.io.Text;
public class Lower extends UDF {
public Text evaluate(final Text s) {
if (s == null) { return null; }
return new Text(s.toString().toLowerCase());
}
}
将写的代码打成一个jar包,假如jar名为udf.jar,并上传到服务器目录/usr/local/src/hive/jars。
执行add jar /usr/local/src/hive/jars/udf.jar; 将jar文件放到分布式缓存里。

执行create temporary function my_lower as 'com.utstar.patrick.Lower';创建临时的function
然后就像使用内置方法一样使用my_lower方法。如select my_lower("ABc");

可以执行drop temporary function if exists my_lower;来删除临时的function
关于org.apache.hadoop.hive.ql.exec.UDF类更详细的说明可以查看源码

transform脚本
Hive的 TRANSFORM 关键字提供了在SQL中调用自写脚本的功能,适合实现Hive中没有的功能但是又不想写UDF的情况。
关于TRANSFORM首先需要知道的是,所有的column在作为参数传入用户自定义的transform脚本时都会预先转换成字符串并且用TAB分隔。如果是NULL值的话会转变成\N字符串以区别空字符串,脚本里标准的输出也是用TAB分隔的字符串,如果是\N字符串会被hive当做NULL处理。
如下一个简单的字符串拼接脚本。这个脚本和HadoopStreaming脚本非常类似的,都是通过标准输入和输出来处理数据。
注意需要用strip()来消除首尾的空格和换行符,否则打印时会有换行。
import sys
for line in sys.stdin:
a, b = line.strip().split("\t")
print " : ".join([a, b])
假如上述脚本文件保存为 /usr/local/src/hive/jars/my.py
添加文件到分布式缓存 add file /usr/local/src/hive/jars/my.py;
示例如下
select transform("name","patrick") using 'my.py' as str;
如下图所示

我们以HIVE学习四:Window And Analytical Function中的orders表为例将order_id和customer_name拼接起来
select transform(order_id, customer_name) using 'my.py' as str from orders;
如下图所示


lateral view
在说明这个lateral view,需要先了解下explode函数。
如下所示,explode函数的参数是array,该函数会将array转变成多条数据。

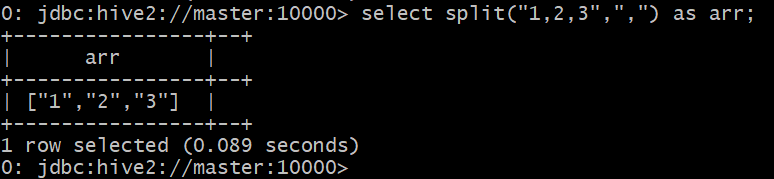
用split函数可以生成array

如图 select split("1,2,3",",") as arr; 将字符串1,2,3按照逗号分割成了一个array
然后通过 select explode(split("1,2,3",",")) as arr; 将一个array变成了多条数据,成功地实现了行转列。

在了解到explode之后我们接着看Lateral View
其完整语法如下,一般都与UDTF函数如explode联合使用
lateralView: LATERAL VIEW udtf(expression) tableAlias AS columnAlias (',' columnAlias)*
fromClause: FROM baseTable (lateralView)*
假设我们有如下一张表pageads,其中add_list的类型是array<int>
create table pageads
(pageid string, adid_list array<int>);
初始化表pageads
insert into table pageAds
select "front_page", Array(1,2,3)
union
select "contact_page", Array(3,4,5);
查看表数据
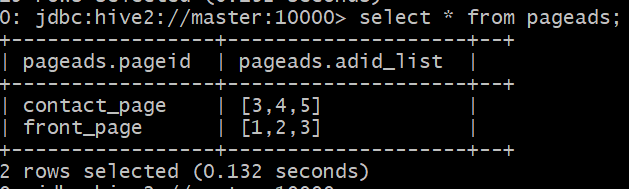
可以通过 show create table pageads;和desc formatted pageads;查看表的具体信息


然后我们想查看每个广告在哪个页面上出现过,可以执行如下语句
select pageid, adid from pageads lateral view explode(adid_list) temp as adid;

如果想查看每个广告出现的次数,就可以执行如下语句
select count(*), adid from pageads lateral view explode(adid_list) temp as adid group by adid;

Multiple Lateral Views
一个from语句可以包含多个LATERAL VIEW语句。后面的LATERAL VIEW语句可以引用出现在LATERAL VIEW左边的表的任何字段。
例如,下面sql查询是正确的
SELECT * FROM exampleTable
LATERAL VIEW explode(col1) myTable1 AS myCol1
LATERAL VIEW explode(col2) myTable2 AS myCol2;
创建如下表
create table test
(col1 array<int>, col2 array<string>);
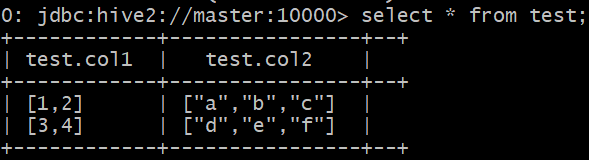
初始化数据如下
insert into table test
select Array(1,2), Array("a","b","c")
union
select Array(3,4), Array("d","e","f");
查看数据如下图
然后执行下面的sql语句,包含多个lateral view
SELECT * FROM test
LATERAL VIEW explode(col1) myTable1 AS myCol1
LATERAL VIEW explode(col2) myTable2 AS myCol2;
结果如下图

一个包容万象的小例子
假设有这么一张表stu
create table stu
(name string, info string);
表中有如下数据
insert into table stu
select "zhangsan","math:90,english:60"
union
select "lisi","chinese:80,math:66,english:77"
union
select "wangwu","chinese:66,math:55,english:80";
如下图所示

现在要查询每门课程中最高分和其对应的学生姓名
第一步,首先explode出学生、课程、分数的信息,sql如下
select transform(name, sub_grade) using 'split.py' as name,sub,grade
from stu lateral view explode(split(info,",")) temp as sub_grade

注意一点,transform脚本需要处理name, sub_grade,而不能像select name,transform(sub_grade) using 'split.py' as sub,grade from stu lateral view explode(split(info,",")) temp as sub_grade;一样,简单地说你所返回的数据要全部从transform脚本里输出,而不能一部分从表引用,一部分从transform脚本里输出。
其中transform脚本文件split.py内容如下
import sys
for line in sys.stdin:
a, b = line.strip().split("\t")
sub, grade = b.split(":")
print "{}\t{}\t{}".format(a, sub, grade)
第二步,由于用transform脚本做了transformation处理,类型全部会变成string类型,具体可参考Setting Types for Sort By这篇我写的博客,需要用cast函数将grade转化为int类型。
select name, sub, cast(grade as int) grade from
(
select transform(name, sub_grade) using 'split.py' as name,sub,grade from stu lateral view explode(split(info,",")) temp as sub_grade
) a
第三步,用窗口函数获取每个课程的最高分及学生姓名
select *,first_value(grade) over (partition by sub order by grade desc) as g
,first_value(name) over (partition by sub order by grade desc) as n
from
(
select name, sub, cast(grade as int) grade from
(
select transform(name, sub_grade) using 'split.py' as name,sub,grade from stu lateral view explode(split(info,",")) temp as sub_grade
) a
) b

第四步,去重即可完成最终的sql
select distinct sub,first_value(grade) over (partition by sub order by grade desc) as g
,first_value(name) over (partition by sub order by grade desc) as n
from
(
select name, sub, cast(grade as int) grade from
(
select transform(name, sub_grade) using 'split.py' as name,sub,grade from stu lateral view explode(split(info,",")) temp as sub_grade
) a
) b

参考网址
HivePlugins
LanguageManual+Transform
LanguageManual+Commands
LanguageManual+UDF
LanguageManualDDL-CreateFunction
UDF简单使用
how-can-select-a-column-and-do-a-transform-in-hive
