用于医学图像分割的非局部U-Net
这篇文章提出了一个新的U-Net模型,它的推理速度较之以往速度更快,精度更高,参数量更少。提出了一个新的上/下采样方法:全局聚合块,把self-attention和上/下采样相结合,在上/下采样的同时考虑全图信息。
U-Net的不足之处
- U-Net的encoder部分由若干卷积层和池化层组成,由于它们都是local的运算,只能看到局部的信息,因此需要通过堆叠多层来提取长距离信息,这种方式较为低效,参数量大,计算量也大。过多的下采样导致更多空间信息的损失,图像分割要求对每个像素进行准确的预测,空间信息的损失会导致分割图不准确。
- decoder的形式与encoder部分正好相反,包括若干个上采样运算,使用反卷积或差值的方法,这些也是local的方法。
创新点
- 为了解决以上问题,作者基于self-attention提出了一个Non-local的结构,global aggregation block用于在上/下采样时可以看到全图的信息,这样会使得到更准确的分割图。
- 简化U-Net,减少参数量,提高推理速度,上采样和下采样使用global aggregation block,使分割更准确。
全局聚合块如图所示。

- 该结构中,输入图为X(BxHxWxC),经过QueryTransform和1x1卷积,转换为Q(BxHqxWqxCk),K(BxHxWxCk),V(BxHxWxCv)。QueryTransform可以为卷积,反卷积,差值等方法,最后输出结果的H与W将与这个值一致。
- 代码里在unfold之前有Multi-Head的操作,不过在论文中没有说明,实际上是把通道分为N等份。Unfold是把batch,height,width,N通道合并。
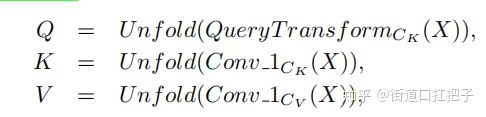
- 接下来是经典的点积attention操作,得到一个权值矩阵A((BxHqxWqxN)*(BxHxWxN)),用于self-attention的信息加权,分母Ck是通道数,作用是调节矩阵的数值不要过大,使训练更稳定。最后权值矩阵A和V点乘,得到最终的结果((BxHqxWqxN)xCv),可见输出的height和width由Q决定,通道数由V决定。

- 现在很多上采样相关的论文关注于在上采样时用CNN扩大感受野,增加图像局部信息。这篇文章提出的全局聚合块是一个将注意力机制和上/下采样相结合的方法,关注全图信息,感受野更大,可以在其他任务上试用一下,效果如何还是要看实践的结果。
Non-local U-Nets

相比U-Net,卷积层数减少,图像下采样倍率从16倍变成4倍,保留了更多空间信息。encoder和decoder之间的跳过连接用相加的方式,不是拼接的方式,让模型推理速度更快。
上下采样使用全局聚合块,使分割图更准确。
实验结果


参数量减少了很多,推理速度更快。

结果图如下:训练数据是3D多模态等强度婴儿脑MR图像。

