第五章:HDFS的API操作
5.2 从本地中上传文件到HDFS
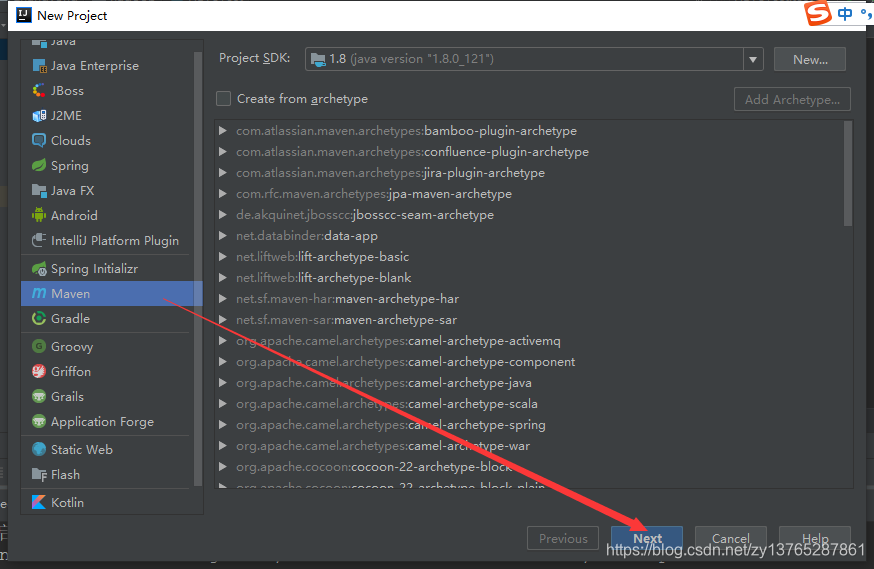
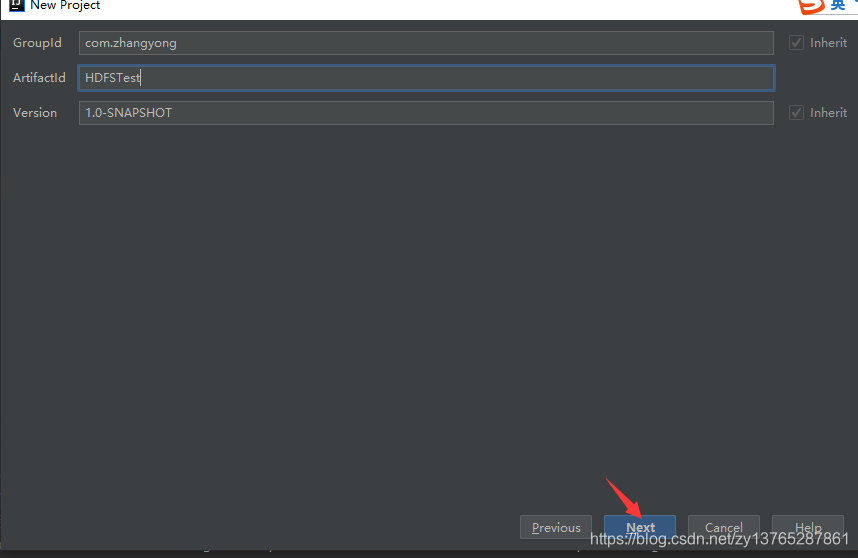
第一步:用IDEA创建Maven形式的Java项目
第二步:添加Maven依赖
在pom.xml添加HDFS的坐标,
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.1.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.1.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-yarn-common</artifactId>
<version>3.1.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-yarn-client</artifactId>
<version>3.1.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-yarn-server-resourcemanager</artifactId>
<version>3.1.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>3.1.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>3.1.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>3.1.2</version>
</dependency>
<dependency>
<groupId>net.minidev</groupId>
<artifactId>json-smart</artifactId>
<version>2.3</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.12.1</version>
</dependency>
<dependency>
<groupId>org.anarres.lzo</groupId>
<artifactId>lzo-hadoop</artifactId>
<version>1.0.6</version>
</dependency>
</dependencies>
第三步:在resources目录下加入日志文件
log4j.properties
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
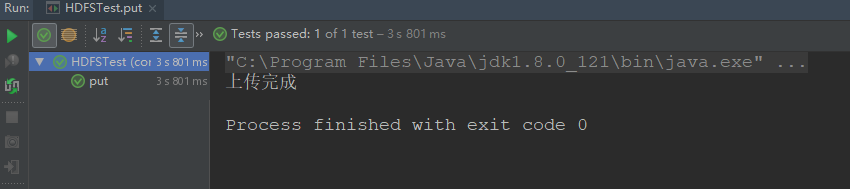
第四步:编写java代码将D盘的logs上传到HDFS
/**
* 从本地中上传文件到HDFS
* @throws URISyntaxException
* @throws IOException
*/
@Test
public void put() throws URISyntaxException, IOException, InterruptedException {
//虚拟机连接名,必须在本地配置域名,不然只能IP地址访问
String hdfs = "hdfs://hadoop101:9000";
//1、读取一个HDFS的抽象封装对象
Configuration configuration = new Configuration ();
FileSystem fileSystem = FileSystem.get (URI.create (hdfs), configuration, "zhangyong");
//用这个对象操作文件系统
fileSystem.copyFromLocalFile (new Path ("d:\\logs"),new Path ("/"));
System.out.println ("上传完成");
//关闭文件系统
fileSystem.close ();
}
第五步:运行结果
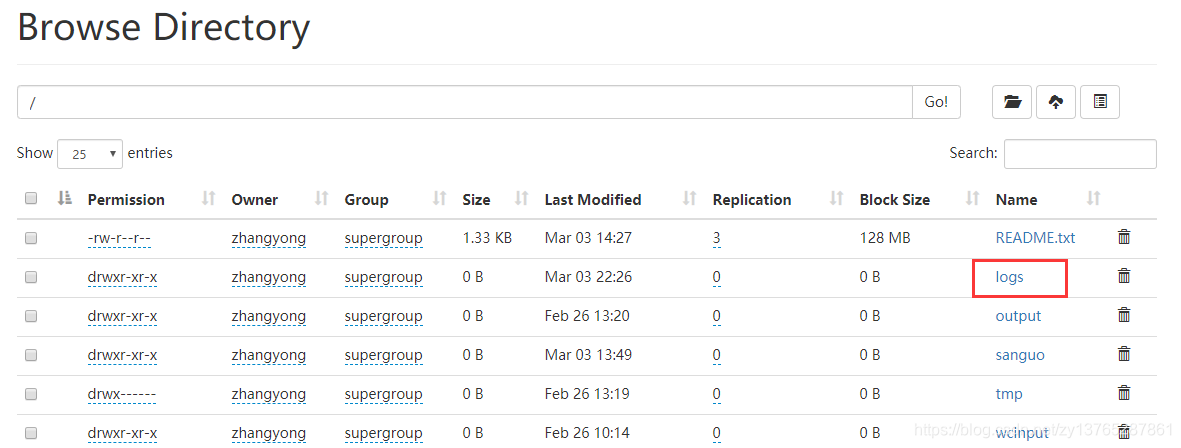
5.3 从HDFS中下载文件到本地
第一步:上面第一、二、三步一样
第二步:查看HDFS文件
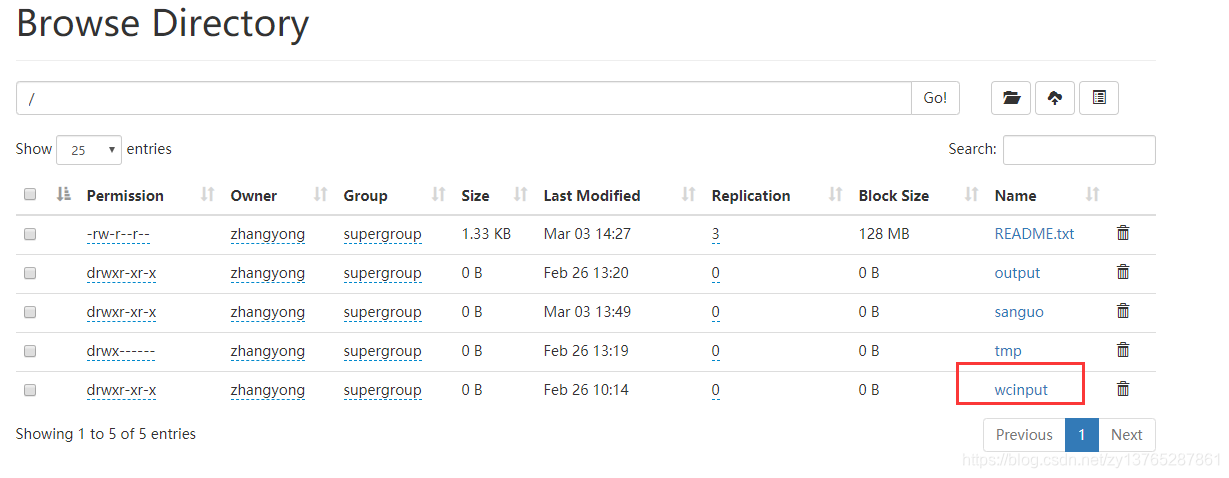
第三步:编写java代码,我们选择wcinput下载到本地
/**
* 从HDFS中下载文件
* @throws URISyntaxException
* @throws IOException
*/
@Test
public void get() throws URISyntaxException, IOException, InterruptedException {
//虚拟机连接名,必须在本地配置域名,不然只能IP地址访问
String hdfs = "hdfs://hadoop101:9000";
//1、读取一个HDFS的抽象封装对象
Configuration configuration = new Configuration ();
FileSystem fileSystem = FileSystem.get (URI.create (hdfs), configuration, "zhangyong");
//用这个对象操作文件系统
fileSystem.copyToLocalFile (new Path ("/wcinput"),new Path ("d:\\"));
System.out.println ("下载完成");
//关闭文件系统
fileSystem.close ();
}
第四步:运行结果

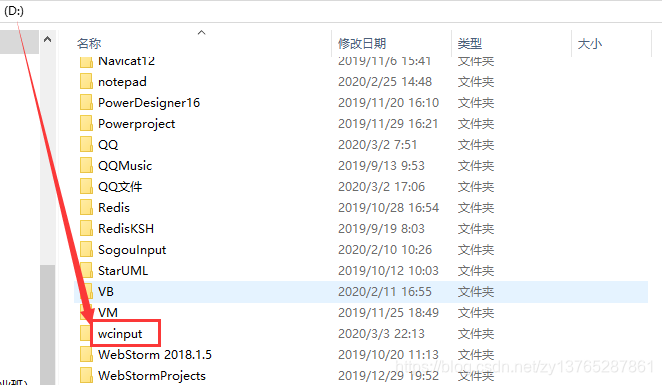
5.4 更改HDFS文件的名称
第一步:上面第一、二、三步一样
第二步:编写java代码,更改logs为logs2
/**
* 更改HDFS文件的名称
* @throws URISyntaxException
* @throws IOException
*/
@Test
public void rename() throws URISyntaxException, IOException, InterruptedException {
//虚拟机连接名,必须在本地配置域名,不然只能IP地址访问
String hdfs = "hdfs://hadoop101:9000";
//1、读取一个HDFS的抽象封装对象
Configuration configuration = new Configuration ();
FileSystem fileSystem = FileSystem.get (URI.create (hdfs), configuration, "zhangyong");
//用这个对象操作文件系统
fileSystem.rename (new Path ("/logs"),new Path ("/logs2"));
System.out.println ("更改完成");
//关闭文件系统
fileSystem.close ();
}
第三步:运行结果
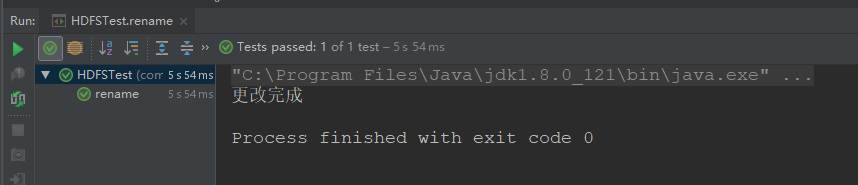
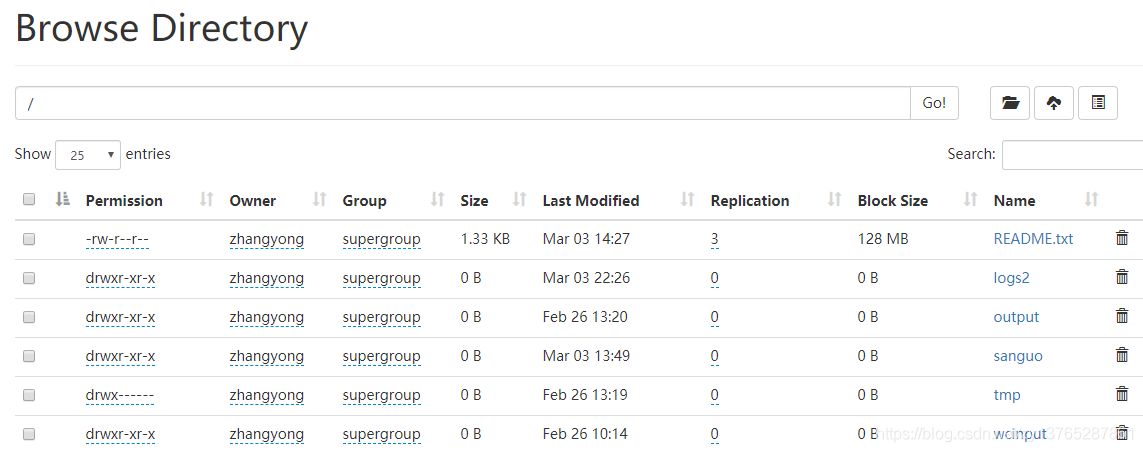
5.5 HDFS文件夹删除
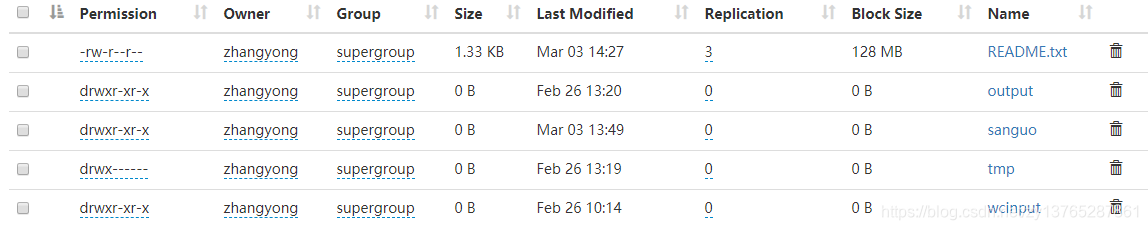
第一步:查看HDFS的文件夹,删除HDFS的logs2

第二步:编写java代码
/** HDFS文件夹删除
* @throws IOException
* @throws InterruptedException
* @throws URISyntaxException
*/
@Test
public void Delete() throws IOException, InterruptedException, URISyntaxException {
//虚拟机连接名,必须在本地配置域名,不然只能IP地址访问
String hdfs = "hdfs://hadoop101:9000";
// 1 获取文件系统
Configuration configuration = new Configuration ();
FileSystem fs = FileSystem.get (new URI (hdfs), configuration, "zhangyong");
// 2 执行删除
fs.delete (new Path ("/logs2/"), true);
// 3 关闭资源
fs.close ();
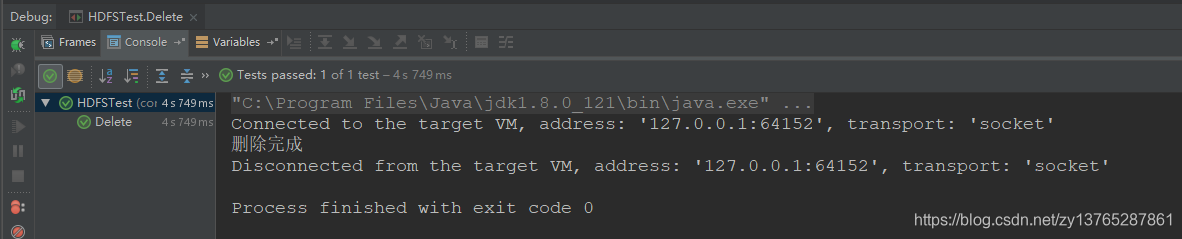
System.out.println ("删除完成");
}
第三步:测试结果
5.6 HDFS文件详情查看
第一步:查看文件名称、权限、长度、块信息
第二步:编写java代码
/**
* 查看文件名称、权限、长度、块信息
* @throws IOException
* @throws InterruptedException
* @throws URISyntaxException
*/
@Test
public void ListFiles() throws IOException, InterruptedException, URISyntaxException {
//虚拟机连接名,必须在本地配置域名,不然只能IP地址访问
String hdfs = "hdfs://hadoop101:9000";
// 1获取文件系统
Configuration configuration = new Configuration ();
FileSystem fileSystem = FileSystem.get (new URI (hdfs), configuration, "zhangyong");
// 2 获取文件详情
RemoteIterator<LocatedFileStatus> listFiles = fileSystem.listFiles (new Path ("/"), true);
while (listFiles.hasNext ()) {
LocatedFileStatus status = listFiles.next ();
// 输出详情
// 文件名称
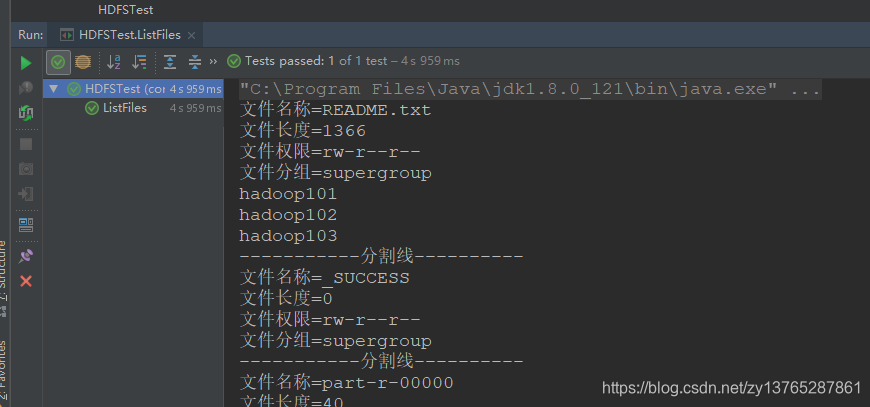
System.out.println ("文件名称="+status.getPath ().getName ());
// 长度
System.out.println ("文件长度="+status.getLen ());
// 权限
System.out.println ("文件权限="+status.getPermission ());
// 分组
System.out.println ("文件分组="+status.getGroup ());
// 获取存储的块信息
BlockLocation[] blockLocations = status.getBlockLocations ();
for (BlockLocation blockLocation : blockLocations) {
// 获取块存储的主机节点
String[] hosts = blockLocation.getHosts ();
for (String host : hosts) {
System.out.println (host);
}
}
System.out.println ("-----------分割线----------");
}
// 3 关闭资源
fileSystem.close ();
}
第三步:测试结果
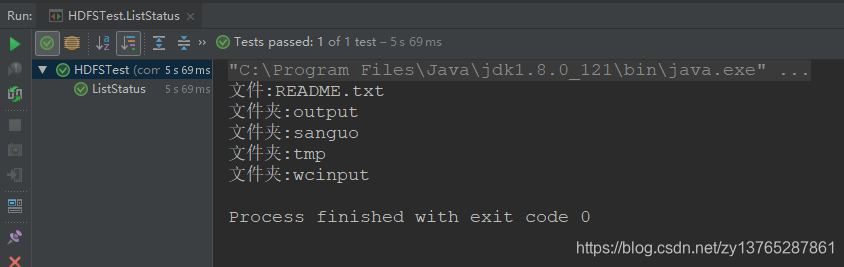
5.7 HDFS文件和文件夹判断
第一步:查看HDFS的文件
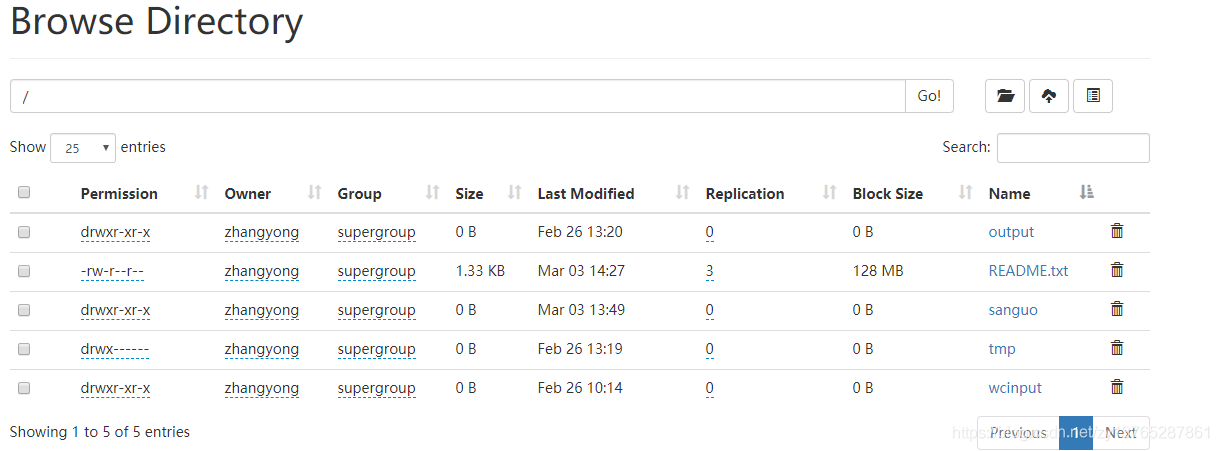
第二步:编写java代码
/**
* 查看HDFS的判断是文件还是文件夹
* @throws IOException
* @throws InterruptedException
* @throws URISyntaxException
*/
@Test
public void ListStatus() throws IOException, InterruptedException, URISyntaxException{
//虚拟机连接名,必须在本地配置域名,不然只能IP地址访问
String hdfs = "hdfs://hadoop101:9000";
// 1 获取文件配置信息
Configuration configuration = new Configuration();
FileSystem fileSystem = FileSystem.get(new URI(hdfs), configuration, "zhangyong");
// 2 判断是文件还是文件夹
FileStatus[] listStatus = fileSystem.listStatus(new Path("/"));
for (FileStatus fileStatus : listStatus) {
// 如果是文件
if (fileStatus.isFile()) {
System.out.println("文件:"+fileStatus.getPath().getName());
}else {
System.out.println("文件夹:"+fileStatus.getPath().getName());
}
}
// 3 关闭资源
fileSystem.close();
}
第三步:测试结果