1 可见性问题
1.1 复现可见性问题
可见性问题测试代码如下:
package com.nrsc.ch1.base.jmm.problem;
/***
* Description: 可见性问题,一个线程对共享变量的修改,另一个线程不能立即得到最新值
*/
public class VisibilityProblem {
/***共享变量*/
private static boolean flag = true;
public static void main(String[] args) throws InterruptedException {
//线程1
new Thread(() -> {
while (flag) {
}
}).start();
//睡一秒,保证线程1先运行
Thread.sleep(1000);
//线程2
new Thread(() -> {
flag = false;
System.err.println("本线程已经将flag改为了: " + flag);
}).start();
}
}
按理来说,上诉代码的运行过程应该如下:
- 线程1肯定会先运行,进入到一个死循环中;
- 然后线程2开始运行,将共享变量flag改为false;
- 最后由于共享变量flag的值已经改变,线程1应该感知到,并结束循环 —》 整个程序结束。
但是事实确实上的运行结果如下:

这就说明线程2对共享变量flag的修改,线程1是无法感知到的 — 》这就是并发编程中的可见性问题。
1.2 可见性问题产生的原因
可见性问题产生的原因与java内存模型(java memory model,JMM)有关 —》 JMM相关的概念请自行百度。
这里仅说一下可见性问题产生的原因。
首先应该知道,java的线程与主内存进行交互的动作有如下8个(均为原子性动作):
这里参考了文章《java内存模型JMM理解整理》
- lock (锁定):把一个变量标识为线程独占状态
- unlock (解锁):把一个处于锁定状态的变量释放出来,释放后的变量才可以被其他线程锁定
- read (读取):把一个变量的值从主内存传输到线程的工作内存中,以便随后的load动作使用
- load (载入):作用于工作内存的变量,它把read操作从主存中变量放入工作内存中
- use (使用):作用于工作内存中的变量,它把工作内存中的变量传输给执行引擎,每当虚拟机遇到一个需要使用到变量的值,就会使用到这个指令
- assign (赋值):作用于工作内存中的变量,它把一个从执行引擎中接受到的值放入工作内存的变量副本中
- store (存储):把一个从工作内存中一个变量的值传送到主内存中,以便后续的write使用
- write (写入):作用于主内存中的变量,它把store操作从工作内存中得到的变量的值放入主内存的变量中
1.1出现可见性问题的原因可以用下图来进行解释:

2 原子性问题
原子性问题测试代码如下:
package com.nrsc.ch1.base.jmm.problem;
import java.util.ArrayList;
import java.util.List;
/***
* Description: 原子性问题
*/
public class AtomicityProblem {
/***共享变量*/
private static int num = 0;
public static void main(String[] args) throws InterruptedException {
Runnable increment = () -> {
for (int i = 0; i < 1000; i++) {
num++;
}
};
List<Thread> threads = new ArrayList<>();
//10个线程各执行1000次num++
for (int i = 0; i < 10; i++) {
Thread t = new Thread(increment);
t.start();
threads.add(t);
}
//确保10个线程都走完
for (Thread thread : threads) {
thread.join();
}
System.out.println("10个线程执行后的结果为:" + num);
}
}
按理来说,上诉代码的运行结果应该为1000*10 = 10000,但是实际却可能产生如下结果:
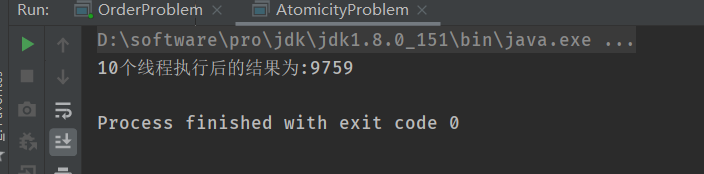
导致该问题的原因,相信大家都知道 —> num ++ 不是原子操作 —> 这就是并发编程中的原子性问题。
3 有序性问题
3.1 复现有序性问题
有序性问题常规条件下不是很好复现,可以借助于java并发压测工具: jcstress来进行
官网: https://wiki.openjdk.java.net/display/CodeTools/jcstress
其用法如下:
- (1)在pom.xml里引入jar — > 我参考的《Java中jcstress 高并发测试框架简单使用教程》这篇文章 —》 这里就不贴代码了,有兴趣的直接clone代码看吧。
- (2)代码如下:
package com.nrsc.ch1.base.jmm.problem;
import org.openjdk.jcstress.annotations.Actor;
import org.openjdk.jcstress.annotations.JCStressTest;
import org.openjdk.jcstress.annotations.Outcome;
import org.openjdk.jcstress.annotations.State;
import org.openjdk.jcstress.infra.results.II_Result;
import static org.openjdk.jcstress.annotations.Expect.ACCEPTABLE;
import static org.openjdk.jcstress.annotations.Expect.ACCEPTABLE_INTERESTING;
/***
* Description: 有序性问题
*/
@JCStressTest
/***
* r.r1 和 r.r2可能出现的结果
*/
@Outcome(id = {"0, 1", "1, 0", "1, 1"}, expect = ACCEPTABLE, desc = "ok")
@Outcome(id = "0, 0", expect = ACCEPTABLE_INTERESTING, desc = "danger")
@State
public class OrderProblem2 {
int x, y;
/****
* 线程1 执行的代码
* @param r
*/
@Actor
public void actor1(II_Result r) {
x = 1;
r.r2 = y;
}
/****
* 线程2 执行的代码
* @param r
*/
@Actor
public void actor2(II_Result r) {
y = 1;
r.r1 = x;
}
}
这里注意一下这个II_Result 对象,由于我这里想看两个值的结果,所以用到了II_Result 对象,如果我只想看一个值的结果,就得用I_Result 对象。@Outcome注解里列出的就是r.r1和r.r2可能的结果值。

另一个测试有序性的代码如下, 该代码就用到了I_Result对象。
package com.nrsc.ch1.base.jmm.problem;
import org.openjdk.jcstress.annotations.*;
import org.openjdk.jcstress.infra.results.I_Result;
/***
* Description: 有序性问题
*/
@JCStressTest
/***
* r.r1可能出现的结果
*/
@Outcome(id = {"1", "4"}, expect = Expect.ACCEPTABLE, desc = "ok")
@Outcome(id = "0", expect = Expect.ACCEPTABLE_INTERESTING, desc = "danger")
@State
public class OrderProblem1 {
int num = 0;
boolean ready = false;
/***
* 线程1 执行的代码
* @param r
*/
@Actor
public void actor1(I_Result r) {
if (ready) {
r.r1 = num + num;
} else {
r.r1 = 1;
}
}
/***
* 线程2 执行的代码
* @param r
*/
@Actor
public void actor2(I_Result r) {
num = 2;
ready = true;
}
}
- (3) 打包 —> 运行命令mvn clean install
注意: 由于我是按照多模块的方式创建的项目,所以必须要先进入到本项目所在的目录下,如:

命令运行完会在targe目录下生成两个jar包,我们要用的是下面那个

-(4) 通过java -jar jar包的方式运行jar包, 来进行并发压测

在展示压测结果之前,我们先分析一下上面两个代码。
按理来说:
上面的第一个代码(r1,r2)的值应该为(0,1)或(1,0);当然由于不符合原子性,也有可能出现(1,1) —> 但肯定应该不会出现(0,0)
上面的第二个代码(r1)的值应该为(1)或(4) —> 肯定不会出现其他的情况。
但是事实却并非如此。
某轮压测结果如下:


由此可以看到结果中出现了在我们看来不可能发生的情况。
而要出现这种问题的原因,以第二个代码为例,就是
- 先执行了线程2的ready = true;语句
- 紧接着又执行了线程1的if(ready)分支
这种现象其实就是并发编程中的有序性问题。
3.2 有序性问题产生的原因
其实通过分析已经可以知道,之所以出现3.1中的问题,就是因为代码出现了重排序问题,为什么代码会进行重排序呢?
通过下图可以看到,重排序后可以明显减少代码的指令 — 》 指令减少了,速度也就快了
也就是说重排序可以提高代码的处理速度。

其实我们写的代码到最终的执行指令,一般会涉及到三种重排序:
- (1) 编译器优化的重排序。编译器在不改变单线程程序语义的前提下,可以重新安排语句的执行顺序;
- (2)指令级并行的重排序。现代处理器采用了指令级并行技术(Instruction-LevelParallelism,ILP)来将多条指令重叠执行。如果不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序。
- (3)内存系统的重排序。由于处理器使用缓存和读/写缓冲区,这使得加载和存储操作看上去可能是在乱序执行的。

这时候,我想你一定像我刚知道这些时一样疑惑:
(1)我平时写代码没感觉到它进行过重排序啊;
(2)多线程情况下,如果每个线程都可能会发生重排序问题,那为了能写出按照我们的意愿执行的代码,那我们写代码时得考虑多少问题啊。。。
但是实际上以我们的开发经验来说,我们并不需要考虑这么多,这是为什么呢???
其实很简单,就是JMM规定了一些不可进行重新排序的规则,对此我们或许并不知道,但其实已经受益于这些规则了 —> 即happens-before规则 —> 抽空再好好对happens-before整理一下。
