Spark安装配置
1.先去Scala和spark官网下安装包
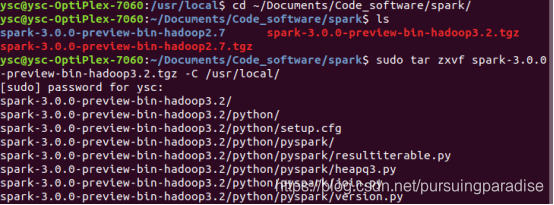
2.通过如
sudo tar zxvf spark-3.0.0-preview-bin-hadoop3.2.tgz -C /usr/local/
解压安装。
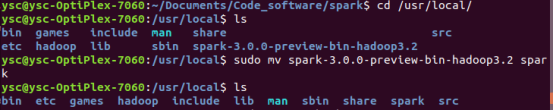
3.文件夹改名
sudo mv spark-3.0.0-preview-bin-hadoop3.2 spark
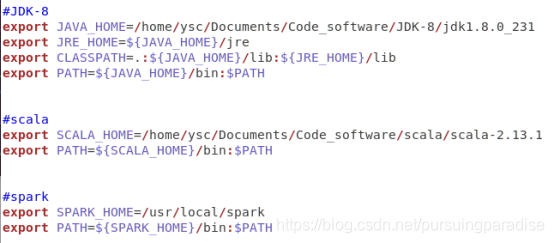
4.配置~/.bashrc
5.配置配置spark-env.sh
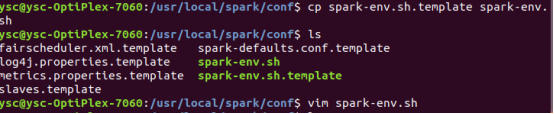
进入到spark/conf/
cp spark-env.sh.template spark-env.sh
vim spark-env.sh
export JAVA_HOME=/home/ysc/Documents/Code_software/JDK-8/jdk1.8.0_231
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
export SCALA_HOME=/home/ysc/Documents/Code_software/scala/scala-2.13.1
export SPARK_HOME=/usr/local/spark
export SPARK_MASTER_IP=127.0.0.1
export SPARK_MASTER_PORT=7077
export SPARK_MASTER_WEBUI_PORT=8099
export SPARK_WORKER_CORES=3
export SPARK_WORKER_INSTANCES=1
export SPARK_WORKER_MEMORY=5G
export SPARK_WORKER_WEBUI_PORT=8081
export SPARK_EXECUTOR_CORES=1
export SPARK_EXECUTOR_MEMORY=1G
export LD_LIBRARY_PATH=
HADOOP_HOME/lib/native
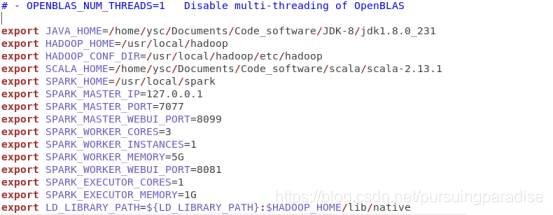
java,hadoop等具体路径根据自己实际环境设置。
6.配置Slave
cp slaves.template slaves

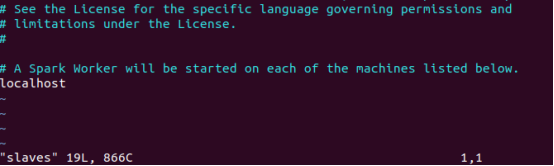
默认就是localhost
7.启动(前提是hadoop伪分布已经启动):
然后启动spark/sbin目录下的start-all.sh.
可能会出现如下问题:
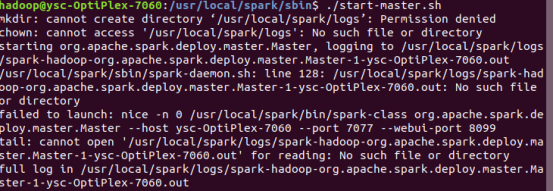
后通过以下方法解决问题
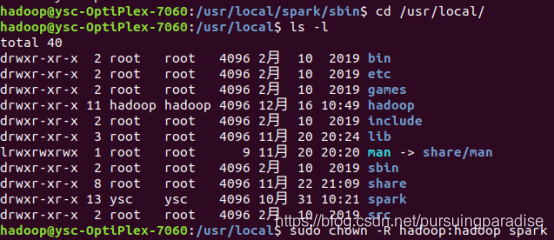
成功启动

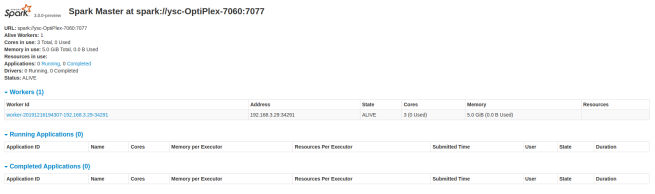
Spark的web界面:http://127.0.0.1:8099/
8.启动bin目录下的spark-shell
cd $SPARK_HOME/bin
./spark-shell
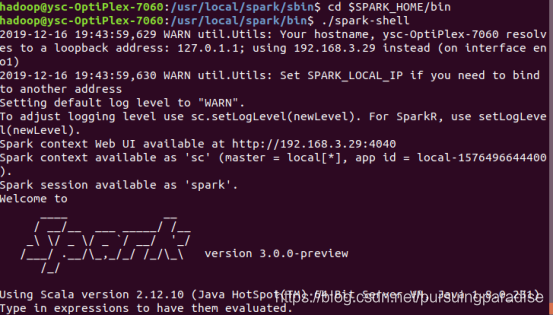
spark-shell的web界面http://127.0.0.1:4040
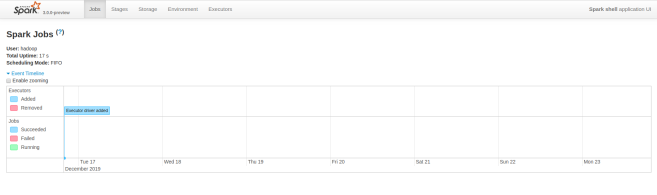
9.python中使用pyspark
当然了,我们在之后的开发过程中,不可能说只在这么一个解释器中开发,所以接下来我们要做的是让python能够加载spark的库。
所以我们需要把pyspark添加到python的寻找目录当中,同样我们需要编辑~/.bashrc文件,在最后添上
export PYTHONPATH=/usr/local/spark/python:/usr/bin/python
这样就把spark目录下的python库添加到了python的找寻目录中
但是由于python需要去调用java的库所以在/usr/local/spark/python路径下我们需要添加一个py4j的文件夹,这个文件可以在/usr/local/spark/python/lib目录下找到,在这个目录下有一个py4j-0.9-src.zip的压缩包,把他解压缩放到/usr/local/spark/python/目录下就可以了
sudo unzip -d /usr/local/spark/python py4j-0.9-src.zip
这个时候在任意目录下输入python

然后在这里输入 import pyspark
查看是否可以正确导入pyspark,如果没有出现任何提示,就说明pyspark能够正常导入。
这样就可以在任何地方编写.py文件,需要用到pyspark的地方用import导入即可。
10.pycharm导入pyspark
当然有些用户喜欢用pycharm来编写python,所以对于pycharm使用pyspark也做一下说明首先我们需要点击右上角的下拉框,选择 Edit Configurations…
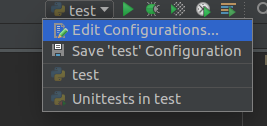
然后在弹出的对话框中,点击Enviroment variables:右侧的编辑按钮

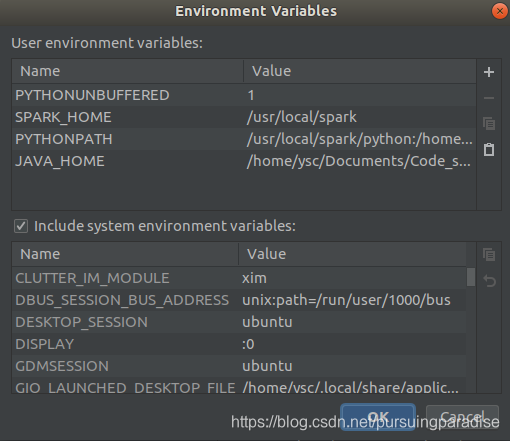
点击加号添加两条新的数据,
PYTHONPATH和
SPARK_HOME
数据内容和~/.bashrc中对应的内容相同
接下来是关键的一步,还要去配置其他的。很多网页上都只有到上一步。在perferences中的project structure中点击右边的“add content root”,添加py4j-some-version.zip和pyspark.zip的路径(这两个文件都在Spark中的python文件夹下)

Import pyspark 的红线消失,运行正常
然后用下述代码测试
import pyspark
conf = pyspark.SparkConf().setAppName(“sparkDemo”).setMaster(“local”)
sc = pyspark.SparkContext(conf=conf)
出现
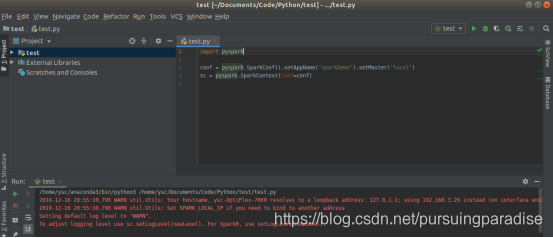
说明pycharm也能够正常载入pyspark了。
