前言
作为一个伪守望迷,如何快速上手某个新英雄呢?
自然是查看官方的视频教程了!
本次博主将会给位守望迷们讲解如何使用python从守望先锋官网爬取英雄教学视频。
环境准备
本次教程将会用到如下内容,为完美享用本次教程大餐,各位读者请尽可能的使用和博主相同的版本。
- python----版本:3.7.2(这个没啥硬性要求,只要是python3的即可)
- requests库----版本:2.22.0(这个没啥硬性要求,只要不要使用远古版本即可)
- lxml库----版本:4.4.1(这个没啥硬性要求,只要lxml库中包含etree模块即可)
- 谷歌浏览器----版本要求暂无
- 一双手和睿智的头脑----相信各位读者大大都有。
网页分析
1.首先我们打开守望官网中的英雄视频教程页面,链接:https://ow.blizzard.cn/media/
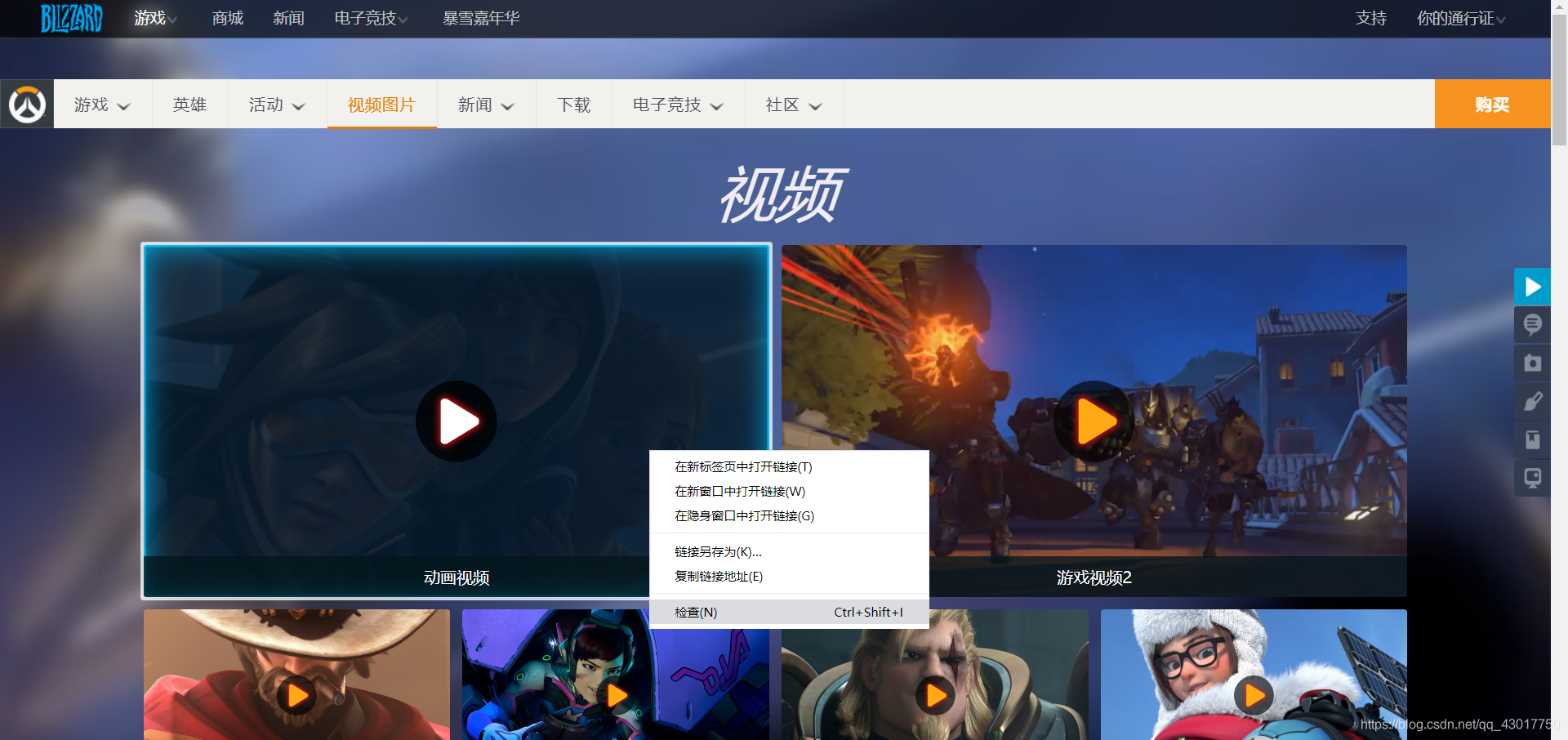
我们右键视频选择【检查】
打开网页源代码
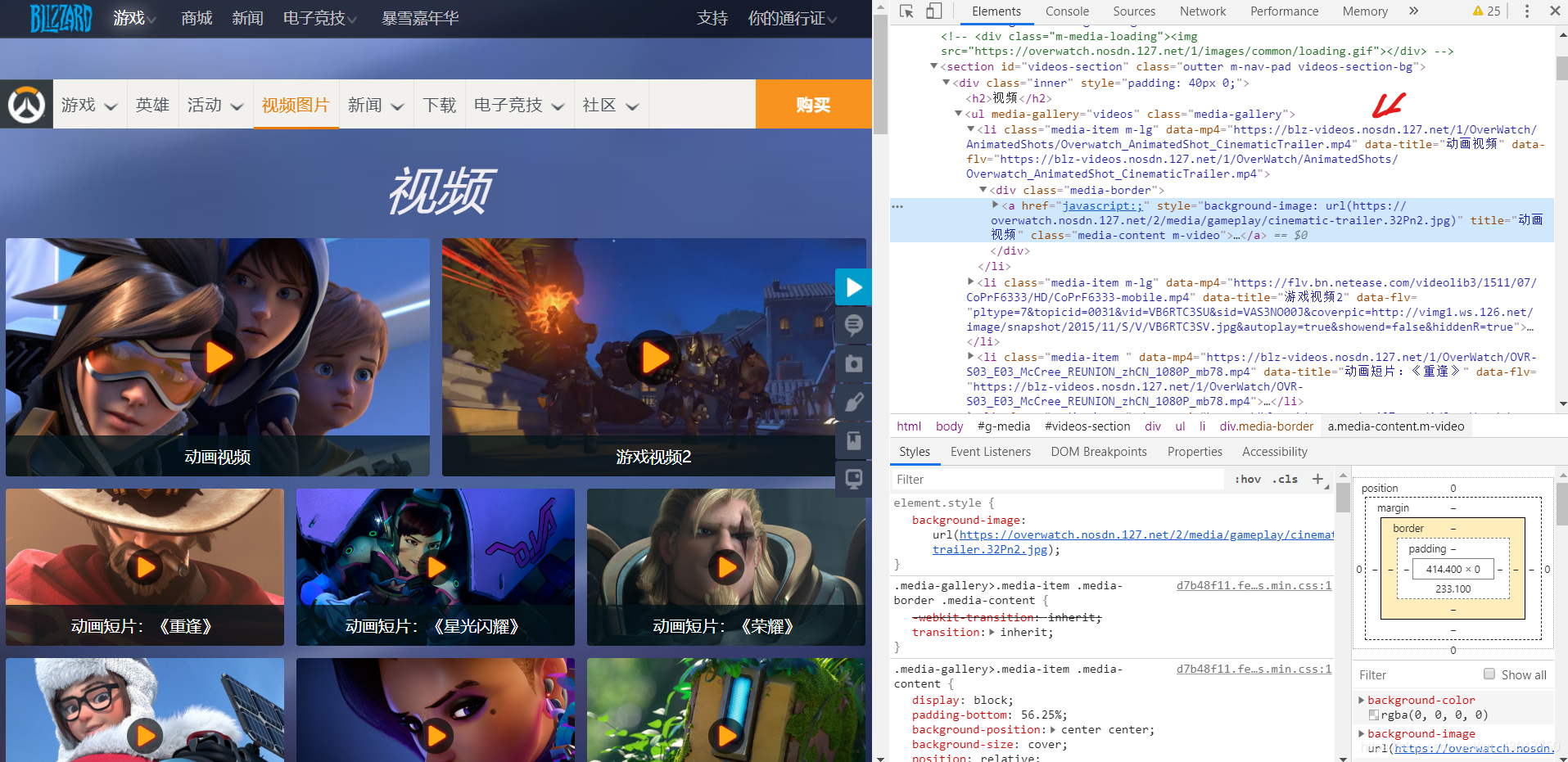
可以看到视频的链接存在于【class】属性为【media-item m-lg】的【li】标签中,内容存在于【data-mp4】属性中
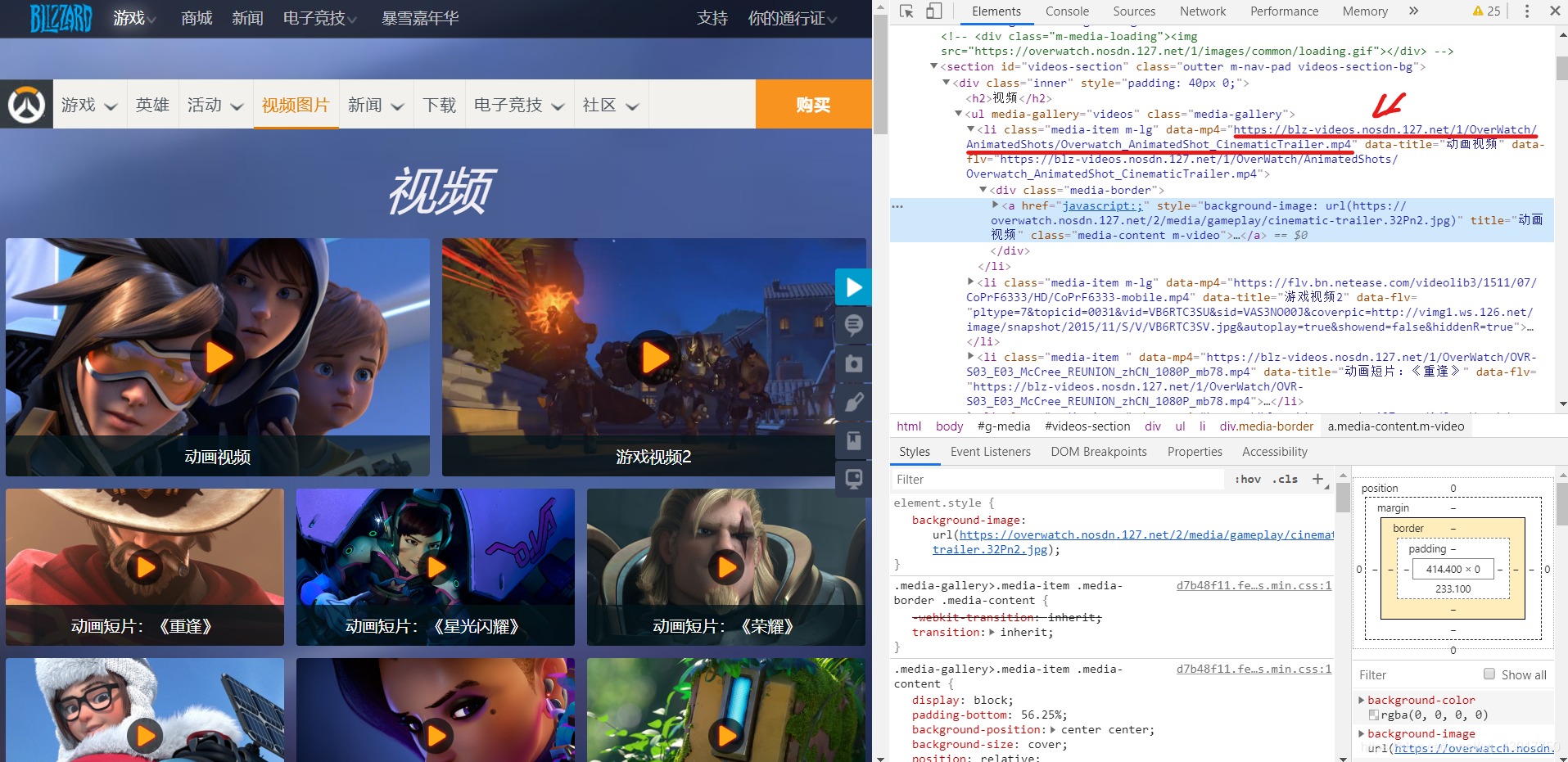
尝试打开该链接,验证是否可以成功打开视频。
视频链接:https://blz-videos.nosdn.127.net/1/OverWatch/AnimatedShots/Overwatch_AnimatedShot_CinematicTrailer.mp4
可以看到成功打开了视频。
代码
# -*- coding:utf-8 -*-
#时间:2019年12月19日
#作者:猫先生的早茶
import requests;
from lxml import etree;
class SHOUWANGXIANFENG():
def __init__(self):
"""定义预定参数"""
#守望官网中的英雄视频教程页面url
self.page_url = "https://ow.blizzard.cn/media/";
#设置请求头
self.headers = {
"Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9",
"Cache-Control": "no-cache",
"Connection": "keep-alive",
"Cookie": "123456789",
"Host": "ow.blizzard.cn",
"Pragma": "no-cache",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "none",
"Sec-Fetch-User": "1",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36",
};
def download_video(self,video_info):
"""下载并保存视频"""
video_header = {
"Accept": "*/*",
"Accept-Encoding": "identity;q=1, *;q=0",
"Accept-Language": "zh-CN,zh;q=0.9",
"Cache-Control": "no-cache",
"Connection": "keep-alive",
"Host": "blz-videos.nosdn.127.net",
"Pragma": "no-cache",
"Referer": "https://blz-videos.nosdn.127.net/1/OverWatch/AnimatedShots/Overwatch_AnimatedShot_CinematicTrailer.mp4",
"Sec-Fetch-Mode": "no-cors",
"Sec-Fetch-Site": "same-origin",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36",
}
#下载视频内容
video_content = requests.get(url=video_info[1],headers=video_header,verify=False).content;
#保存视频
#print (video_info[1]);
with open(video_info[0]+".mp4".replace(':','').replace(' ',''),mode='wb') as write_video:
write_video.write(video_content);
def main(self):
"""控制程序运行"""
#获取页面内容,(注意,可能会提示证书错误,这个不用管,不影响程序运行)
page_html = requests.get(url=self.page_url,headers=self.headers,verify=False).text;
#打印页面内容
#print (page_html);
#将网页转换为etree格式
page_html_etree = etree.HTML(page_html);
#匹配出视频标题
video_title = page_html_etree.xpath("//li[@class='media-item ']/@data-title");
#匹配出视频链接
video_url = page_html_etree.xpath("//li[@class='media-item ']/@data-mp4");
#将视频标题和视频链接压缩在一起
video_infos = dict(zip(video_title,video_url));
#下载视频
for video_info in video_infos.items():
self.download_video(video_info);
shouwangxianfeng = SHOUWANGXIANFENG();
shouwangxianfeng.main();
