摘要:互联网上有很多丰富的信息可以被抓取并转换成有价值的数据集,然后用于不同的行业。比如企业用户利用电商平台数据进行商业分析,学校的师生利用网络数据进行科研分析等等。那么,除了一些公司提供的一些官方公开数据集之外,我们应该在哪里获取数据呢?
作为数据分析的核心,网路爬虫从作为一个新兴技术到目前应用于众多行业,已经走了很长的道路。互联网上有很多丰富的信息可以被抓取并转换成有价值的数据集,然后用于不同的行业。比如企业用户利用电商平台数据进行商业分析,学校的师生利用网络数据进行科研分析等等。那么,除了一些公司提供的一些官方公开数据集之外,我们应该在哪里获取数据呢?其实,我们可以建立一个网路爬虫去抓取网页上的数据。
网络爬虫的基本结构及工作流程
网络爬虫是捜索引擎抓取系统的重要组成部分。爬虫的主要目的是将互联网上的网页下载到本地形成一个或联网内容的镜像备份。
一个通用的网络爬虫的框架如图所示:
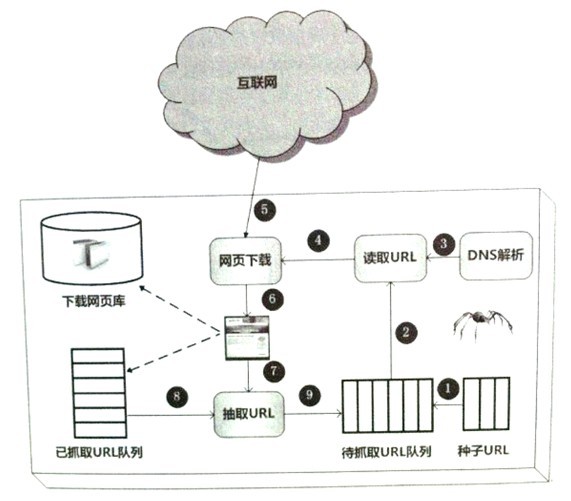
网络爬虫的基本工作流程如下:
1、首先选取一部分精心挑选的种子URL;
2、将这些URL放入待抓取URL队列;
3、从待抓取URL队列中取出待抓取在URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载下来,存储进已下载网页库中。此外,将这些URL放进已抓取URL队列。
4、分析已抓取URL队列中的URL,分析其中的其他URL,并且将URL放入待抓取URL队列,从而进入下一个循环。
创建网络爬虫的主要步骤
要建立一个网络爬虫,一个必须做的步骤是下载网页。这并不容易,因为应该考虑很多因素,比如如何更好地利用本地带宽,如何优化DNS查询以及如何通过合理分配Web请求来释放服务器中的流量。
在我们获取网页后,HTML页面复杂性分析随之而来。事实上,我们无法直接获得所有的HTML网页。这里还有另外一个关于如何在AJAX被用于动态网站的时候检索Javascript生成的内容的问题。另外,在互联网上经常发生的蜘蛛陷阱会造成无数的请求,或导致构建不好的爬虫崩溃。
虽然在构建Web爬虫程序时我们应该了解许多事情,但是在大多数情况下,我们只是想为特定网站创建爬虫程序,而不是构建一个通用程序,例如Google爬网程序。因此,我们最好对目标网站的结构进行深入研究,并选择一些有价值的链接来跟踪,以避免冗余或垃圾URL产生额外成本。更重要的是,如果我们能够找到关于网络结构的正确爬取路径,我们可以尝试按照预定义的顺序抓取目标网站感兴趣的内容。
找到一个合适的网络爬虫工具
网络爬虫的主要技术难点:
· 目标网站防采集措施
· 不均匀或不规则的网址结构
· AJAX加载的内容
· 实时加载延迟
要解决上诉问题并不是一件容易的事情,甚至可能会花费很多的时间成本。幸运的是,现在您不必像过去那样抓取网站,并陷入技术问题,因为现在完全可以利用爬虫工具从目标网站或者数据。用户不需要处理复杂的配置或编程自己构建爬虫,而是可以将更多精力放在各自业务领域的数据分析上。
在这里推荐一个自动化的网络爬虫工具 - 八爪鱼,可以爬取任何网站。用户可以使用内置的网站模板(简易采集)或者完全可视化的操作相应网站抓取数据。并且在八爪鱼中提供了许多技术支持来解决上文中提到的网络爬虫难点,比如:
· 增加代理ip功能,突破防采集的限制
· 内置正则表达式工具可以提取任意数据
· 抓取AJAX加载的内容
· 使用云采集即可支持大规模采集等。
要了解有关此爬虫软件的更多信息,可以查看下面新手入门教程,了解如何开始使用八爪鱼并开始抓取网站。
新手入门教程:
热门网站采集教程:
