一.下载hadoop
去官网下载某版本的hadoop,解压并配置环境变量
多版本可选择
win配置环境变量就不多说了
二.更换hadoop在windows 下的bin文件夹
1.到 https://github.com/steveloughran/winutils 下载hadoop对应版本的bin文件夹,并替换本地文件夹
三.配置pom.xml
1.项目结构类似
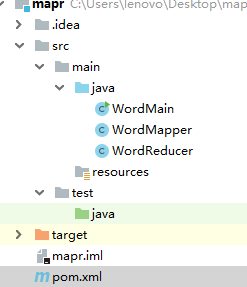
2.version 更改为hadoop对应版本
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-minicluster</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-assemblies</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-maven-plugins</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.6.0</version>
</dependency>
</dependencies>
3.WordMapper.java
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
import java.util.StringTokenizer;
public class WordMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
@Override
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
4.WordReducer.java
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class WordReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
5.WorkMain.java
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.util.Arrays;
import java.util.List;
public class WordMain {
public static void main(String[] args) throws Exception {
//如果配置好环境变量,没有重启机器,然后报错找不到hadoop.home 可以手动指定
System.setProperty("hadoop.home.dir", "F:\\hadoop\\hadoop-2.6.0");
List<String> lists = Arrays.asList("E:\\input_file.txt", "E:\\output_reduce");
Configuration configuration = new Configuration();
Job job = new Job(configuration, "word count");
job.setJarByClass(WordMain.class); // 主类
job.setMapperClass(WordMapper.class); // Mapper
job.setCombinerClass(WordReducer.class); //作业合成类
job.setReducerClass(WordReducer.class); // reducer
job.setOutputKeyClass(Text.class); // 设置作业输出数据的关键类
job.setOutputValueClass(IntWritable.class); // 设置作业输出值类
FileInputFormat.addInputPath(job, new Path(lists.get(0))); //文件输入
FileOutputFormat.setOutputPath(job, new Path(lists.get(1))); // 文件输出
System.exit(job.waitForCompletion(true) ? 0 : 1); //等待完成退出
}
}
四.运行main
如果运行出错,可把hadoop bin 目录中hadoop.dll复制到C:\windows\system32目录下