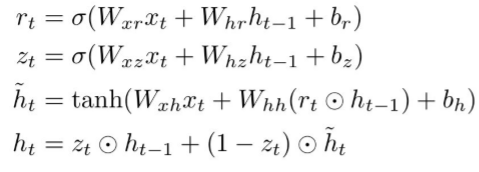目录
S10.1循环神经网络(Recurrent Neural Networks,RNN)
S10.3.2视觉问答Visual Question Answering
S10.1循环神经网络(Recurrent Neural Networks,RNN)
在机器学习领域中,管理模型的梯度流是非常重要的。以前网络的输入和输出大小是固定的。但对于图像摘要,情感分析,翻译等任务,输入和输出大小是不一样的。遇到上述任务,我们就希望机器能够灵活地处理各种数据类型。而RNN就有很大的发挥空间。RNN能够处理各种类型的输入和输出数据。
S10.1.1RNN通用架构
RNN通用架构:每个RNN网络都有一个循环单元,输入,输出。通用架构以及循环函数如下图所示,左边是循环函数,右边是通用架构,绿色框为循环单元。
RNN大致工作流程:首先,x传入循环单元,循环单元会生成一个状态h。这个状态称为内部隐藏态(internal hidden state)。然后,当读取下一次输入时,这个状态会反馈到循环单元,生成新的状态。
RNN模式:读取输入,更新隐藏态,并生成输出。
循环函数:f(h,x),其中h为状态,x为输入,这两个变量都是f的输入,f输出新的状态。该函数含有权重W,在循环时,W不变。
如何在每一时间步给出输出y:在每一个时间步,将当时的状态h输入到全连接层中,进行决策。

S10.1.2RNN的5种类型
依据输入或者输出的尺寸是否可变,RNN可分为5种情况,架构如下图所示:

One to One/(Vanilla) Recurrent Neural Network:Vanilla是一种前馈网络,所有的网络架构都有该基础架构。网络模型如下,输入是固定尺寸,经过一些隐层之后,给出单一的输出结果。Vanilla的循环函数有两个权重,两个权重分别与前一个时间步状态h和此时间步的输入x进行相乘求和,然后使用tanh函数,将结果缩放至[-1,1]范围。Vanilla简单,但效果不怎么好。

One to Many:该模型接收固定长的输入项,然后输出不定长的输出项。在第一个时间步时,有初始状态h0,通常情况下,h0=0。W是在进行f计算时的权重,可以看出,W不变。该类型网络只有一次输入x。在之后的时间步,仅使用前一个时间步h来进行f运算,得到该时间步的状态ht。每个时间步得到的ht作为输入传给之后的网络,得到该时间步下的输出yt。yt可以是每个时步的类别得分或者其他类似的东西。反向传播时,在每一个时步,计算梯度。最终的W梯度是所有时步下独立计算出的梯度之和。下图是该类型RNN的计算图。

Many to One:h0和x1共同输入,计算出下一个状态h1。在后面的时间步,重复之前的步骤,直到用完输入序列中的输入项目xt。最后一个时间步得到的ht作为输入传给之后的网络,得到网络的输出yt。下图是该类型RNN的计算图。

Many to Many:该模型接收固定长的输入项,然后输出固定长的输出项。每个时间步得到的ht作为输入传给之后的网络,得到该时间步下的输出yt。yt可以是每个时步的类别得分或者其他类似的东西。在每个时间步下,都有一个与输入序列对应的真是标签。这样就可以计算出每个时间步的损失Lt。这里的损失函数一般是softmax之类的。所有时间步的单独的损失值的总和是网络最终的损失值L。下图是该类型RNN的计算图。

Sequence to Sequence:该模型接收不定长的输入项,然后输出不定长的输出项。该类型的网络由两部分组成,一部分是Many to One网络,用于对输入进行编码;另一部分是One to Many网络,用于对一个网络的输出进行解码。

S10.2语言建模(Language Modeling)
一个经常使用RNN的领域是语言建模。在该任务中,模型读取一些语句进行学习,使得模型在一定程度上学会生成自然语言。这在字符水平上或者单词水平是可行的,使得模型逐个生成字符或单词。模型的输入可以是莎士比亚的诗,Linux内核源代码,数学拓扑学知识等等。
S10.2.1字符级语言模型例子
首先,语言模型有自己的词典,在本例中,词典为[h,e,l,o]。该模型对输入序列进行训练,最后进行预测。
在训练阶段,设训练序列为"hello",模型学习过程如下图所示。

在测试阶段,一次一个字符返回给模型。当输入一个字符时,会输出一个采样的值,如e。将e进行one-hot编码,当作下一个输入字符,放入模型中,生成下一个输出字符。重复上述步骤直到结束。该模型使用softmax函数进行采样。简单来说,该函数把一些数据映射到(0-1)之间的实数,并且进行归一化,从而保证和为1,即使得多分类的概率之和也刚好为1。模型不使用分数最高的进行输出,而是使用softmax函数进行输出。这样做的原因是,当使用softmax的最大概率值输出时,等同使用分数最高的进行输出。但当使用softmax的采样值(Sample)输出时,(下图中使用采样输出),这会增加模型的灵活性,使得每次模型的输出都不一样。

S10.2.2反向传播
Backpropagation through time :假设有一个序列,每个时间步生成y以及loss,这就是沿时间的反向传播方法。但该方法在序列很长的情况下,十分耗时。因为每次loss的计算,梯度计算和BP依赖于模型输入序列的长度。当输入序列很长时,BP就十分耗时。模型很难收敛,并且占用非常大的内存。

Truncated Backpropagation through time:在实际中,采用一种近似方法,被称为沿时间的截断反向传播方法。。每n个时间步,就计算一次损失以及梯度,在前n个时间步内进行BP,更新权重。min-char-rnn.py实现了该方法。

S10.3RNN应用
S10.3.1图像标注
图像标注是输入一幅图像,模型输出关于该图像的一个描述,这个文字描述是不定长的,考虑使用RNN或者带有注意力机制的模型。处理该任务的一个简单模型由两部分组成,CNN和RNN。CNN部分去掉经典CNN架构的顶层,生成图像的特征。RNN接收CNN特征v,x0(开始标记)和初始状态,进行描述语句的生成。在RNN部分中,循环单元的函数f需要再加上CNN特征项(Wv),一个f的示例:

该模型是一个监督学习模型。在训练阶段,每张图片对应一段描述,每段描述需要有开始标记和结束标记,分别告诉RNN,描述可以开始或者停止。在测试阶段,在t=0时,生成y0,从y0中进行采样,得到的结果作为x1输入到循环单元中进行计算。重复上述步骤,直到采样到停止标记。


一些较好的结果是:

S10.3.2视觉问答Visual Question Answering
这里给出一个视觉问答的模型。在这里,模型的任务是,将图片和问题输入到模型中,模型输出答案。模型由CNN和RNN组成。有时候也会结合soft spacial attention。CNN将图像概括为一个向量。输入的问题概括为一个向量。将CNN向量和输入向量结合,输入到RNN中,来对答案进行预测。
S10.4RNN变种
多层RNN:当网络越深时,性能越好,RNN也是如此。但一般RNN不会太深,大约是一层到四层就够了。下图是一个三层RNN网络结构。

Long Short Term Memory (LSTM):Vanilla RNN在反向传播时,会发生梯度爆炸或消失现象。梯度爆炸可以通过梯度剪切来控制;梯度消失可通过添加额外的交互来控制(LSTM)。实际情况中,通常使用LSTM[Hochreiter et al., 1997]和GRU,它们改进了梯度流。LSTM中的循环单元以及函数如下所示。LSTM单元有隐藏状态ht和单元状态ct。单元状态的值对其他单元不可见,只有隐藏状态可见。LSTM循环单元接收上个时间步的隐藏状态和单元状态。分别计算i,f,o,g四个门的值。然后计算该时间步的隐藏状态和单元状态。相关论文[Hochreiter et al., 1997]和[LSTM: A Search Space Odyssey, Greff et al., 2015]。

GRU: [Learning phrase representations using rnn encoder-decoder for statistical machine translation, Cho et al. 2014]。门控循环单元,单元函数如下所示。类似于LSTM。使用元素乘法和加法一起相互作用来避免梯度消失问题。