介绍
论文地址:Attention-over-Attention Neural Networks for Reading Comprehension
参考博文:
https://www.imooc.com/article/29985
https://www.cnblogs.com/sandwichnlp/p/11811396.html#model-4-aoa-reader
数据集:CNN&Daily Mail、CBT;
阅读理解样本:<D,Q,A>
AOA Reader 属于是一种二维匹配模型(Impatient Reader也是二维匹配模型,AoA Reader类似于CSA Reader),AOA Reader结合了按照列和按照行的方式进行Attention计算(因此叫AoA),同时使用了二次验证的方法对AOA Reader模型计算出的答案进行再次验证。该论文的亮点是将另一种注意力嵌套在现有注意力之上的机制,即注意力过度集中机制。
1 AoA模型具体

Context Embedding:文档嵌入层和问题嵌入层的权值矩阵共享,
Pair-wise Matching Score:将document与query的隐藏状态点乘(因为权值矩阵共享,都是双向GRU,所以维度同),得到pari-wise matching matrix(成对匹配矩阵)
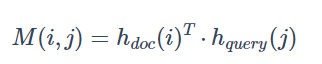
Individual Attentions:
注意力按列计算:计算的是doc中每个词对query中某个词的注意力(重要程度),最后形成文档级别的注意力分布a(t),也就是所谓的query-to-document attetion,见下图,得到α矩阵。其中α的维度为|D|*|Q|
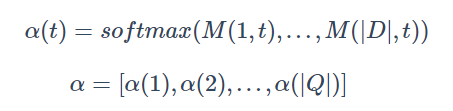
注意力行方向归一化——AoA模型(亮点):
利用注意力来对注意力权重进行加权求和。表示的含义就变成了给定一个文章中的单词,问题中的那些单词对其的重要性
在行的方向进行 Softmax 归一化,得到 document-to-query attention。

对上做平均,得到query-level attention:
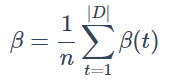
最后,用每个query-to-document attention和刚刚得到的query-level attention做点乘,得到document中每个词的score。(|DQ| * |Q1|)
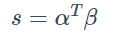
以上按行与按列,总结起来类似于人阅读文档的过程:
在看问题的时候,问题中的单词的重要性是不一样的。主要分析问题中每个单词的贡献,先定位贡献最大的单词(列attention+softmax),然后再在文档中定位和这个贡献最大的单词相关性最高的词(row attention + sum)作为问题的答案
Final Predictions:单词w可能在单词空间V中出现了多次,其出现的位置i组成一个集合I(w, D)

