1 导入相应的库
2 爬取网站url:
http://top.baidu.com/buzz?b=341&c=513&fr=topbuzz_b1
3 找到爬取的内容
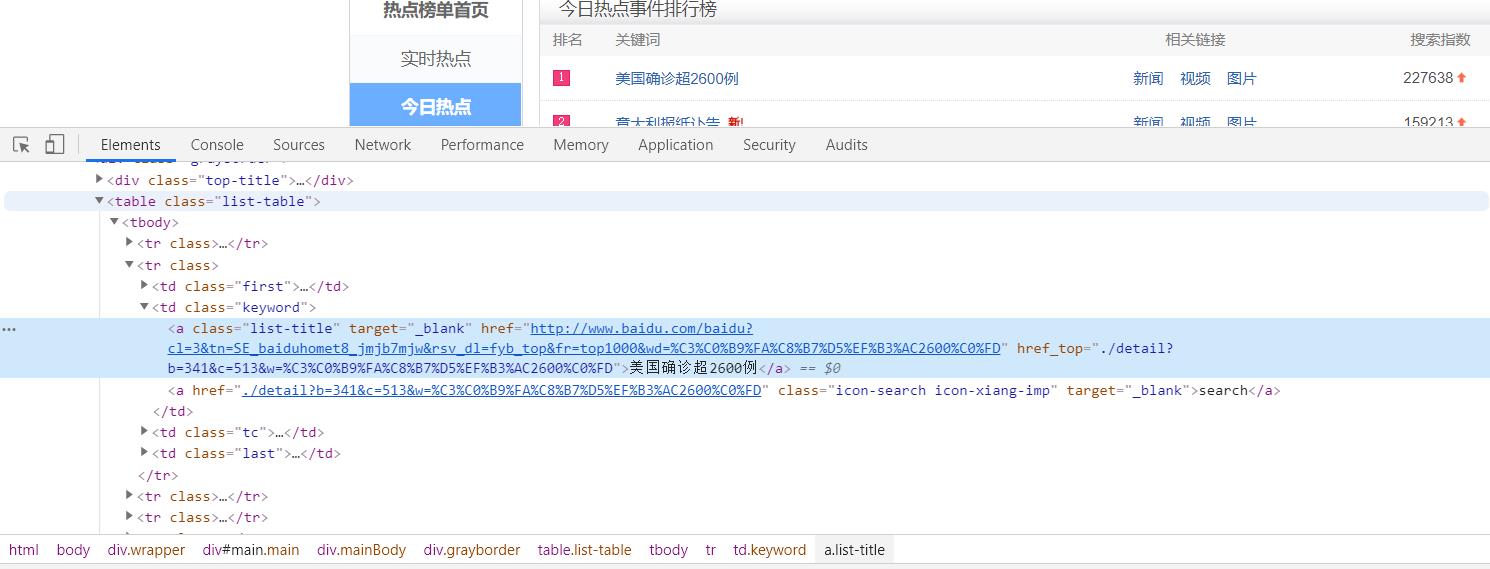
4 具体的代码实现
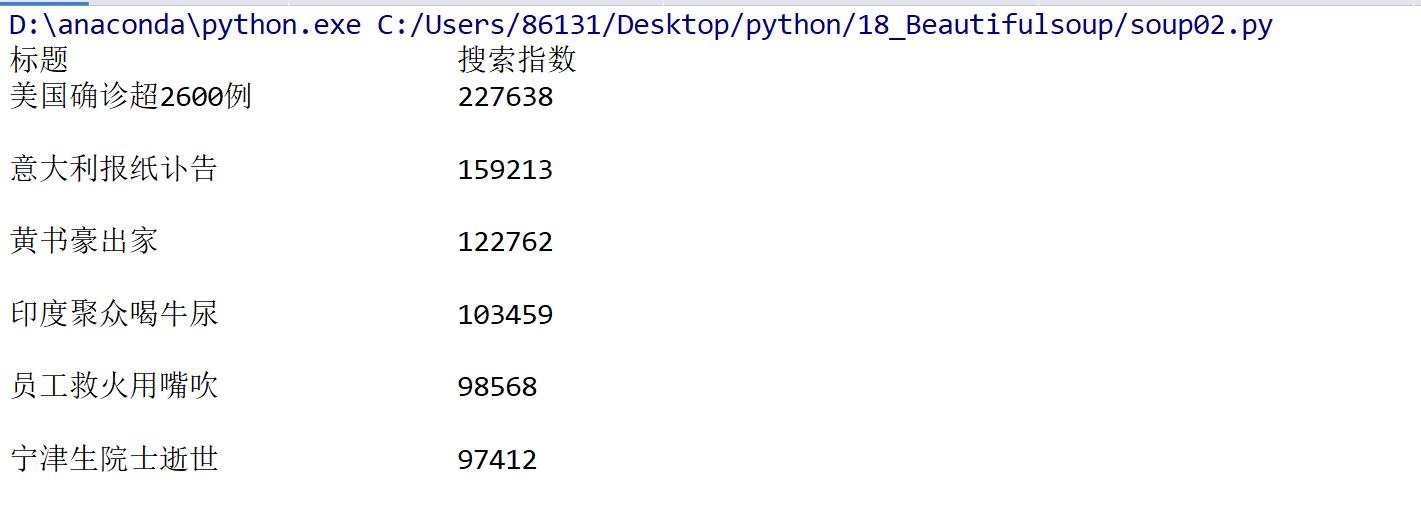
import requests from bs4 import BeautifulSoup url = 'http://top.baidu.com/buzz?b=341&c=513&fr=topbuzz_b1' headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'} urls = requests.get(url, headers=headers) urls.encoding = urls.apparent_encoding text = urls.text soup = BeautifulSoup(text, 'lxml') a = soup.find_all(class_="list-title") aa = [i.get_text() for i in a] q = soup.find_all('td', class_="last") qq = [i.get_text().strip() for i in q] print('{:25}\t{}'.format('标题', '搜索指数')) for i,y in zip(aa,qq): print('{:20}\t{}\n'.format(i,y))
5 test