图片及文字参考:https://blog.csdn.net/weixin_41190227/article/details/86600821
0、排序算法说明
0.1 排序的定义
对一序列对象根据某个关键字进行排序。
0.2 术语说明
稳定 :如果a原本在b前面,而a=b,排序之后a仍然在b的前面;
不稳定 :如果a原本在b的前面,而a=b,排序之后a可能会出现在b的后面;
内排序 :所有排序操作都在内存中完成;
外排序 :由于数据太大,因此把数据放在磁盘中,而排序通过磁盘和内存的数据传输才能进行;
时间复杂度 : 一个算法执行所耗费的时间。
空间复杂度 :运行完一个程序所需内存的大小。
0.3 算法总结
- 图片名词解释:
- n: 数据规模
- k: “桶”的个数
- In-place: 占用常数内存,不占用额外内存
- Out-place: 占用额外内存
0.5 算法分类

0.6 比较和非比较的区别
常见的快速排序、归并排序、堆排序、冒泡排序 等属于比较排序 。在排序的最终结果里,元素之间的次序依赖于它们之间的比较。每个数都必须和其他数进行比较,才能确定自己的位置 。
在冒泡排序之类的排序中,问题规模为n,又因为需要比较n次,所以平均时间复杂度为O(n²)。在归并排序、快速排序之类的排序中,问题规模通过分治法消减为logN次,所以时间复杂度平均O(nlogn)。
比较排序的优势是,适用于各种规模的数据,也不在乎数据的分布,都能进行排序。可以说,比较排序适用于一切需要排序的情况。
计数排序、基数排序、桶排序则属于非比较排序 。非比较排序是通过确定每个元素之前,应该有多少个元素来排序。针对数组arr,计算arr[i]之前有多少个元素,则唯一确定了arr[i]在排序后数组中的位置 。
非比较排序只要确定每个元素之前的已有的元素个数即可,所有一次遍历即可解决。算法时间复杂度O(n)。
非比较排序时间复杂度底,但由于非比较排序需要占用空间来确定唯一位置。所以对数据规模和数据分布有一定的要求。
1.快排:
快速排序 的基本思想:通过一趟排序将待排记录分隔成独立的两部分,其中一部分记录的关键字均比另一部分的关键字小,则可分别对这两部分记录继续进行排序,以达到整个序列有序。
1.1 算法描述
快速排序使用分治法来把一个串(list)分为两个子串(sub-lists)。具体算法描述如下:
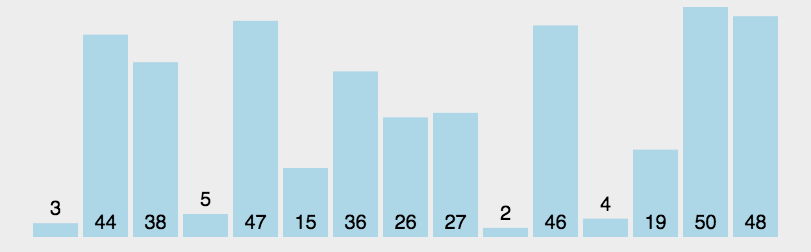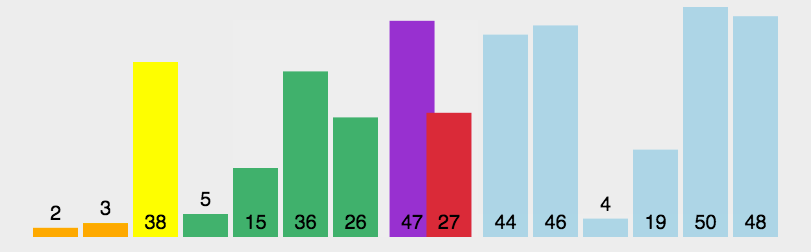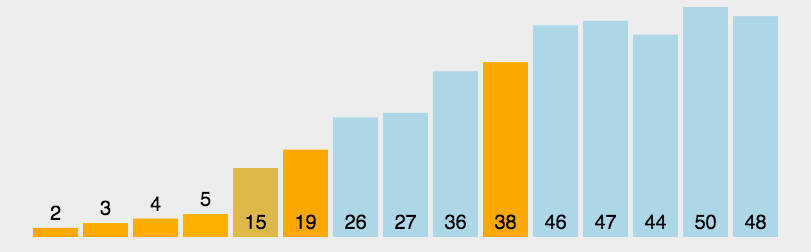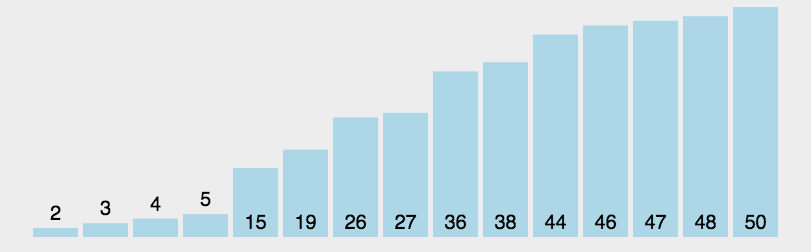
步骤1:从数列中挑出一个元素,称为 “基准”(pivot );
步骤2:重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作;
步骤3:递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序。
动图:
代码:
#include<bits/stdc++.h>
using namespace std;
int n,a[10000];
void Qicksort(int beginn,int endd ){
int index=a[beginn];
int i=beginn;
int j=endd;
if(i>j)
return ;
while(i!=j){
while(a[j]>=index && i<j ){
j--;
}
while(a[i]<=index && i<j){
i++;
}
if(i<j){
swap(a[i],a[j]);
}
}
swap(a[i],a[beginn]);
Qicksort( beginn,i-1 );
Qicksort(i+1,endd);
}
int main()
{
for(int i=1;i<=3;i++){
cin>>a[i];
}
Qicksort(1,3);
for(int i=1;i<=3;i++){
cout<<a[i]<<" ";
}
}
1.2 算法分析
- 最佳情况:T(n) = O(nlogn)
- 最差情况:T(n) = O(n2)
- 平均情况:T(n) = O(nlogn)
- 不稳定!
2.堆排序(Heap Sort)
堆排序(Heapsort) 是指利用堆这种数据结构所设计的一种排序算法。堆积是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。
2.1 算法描述
步骤1:将初始待排序关键字序列(R1,R2….Rn)构建成大顶堆,此堆为初始的无序区;
步骤2:将堆顶元素R[1]与最后一个元素R[n]交换,此时得到新的无序区(R1,R2,……Rn-1)和新的有序区(Rn),且满足R[1,2…n-1]<=R[n];
步骤3:由于交换后新的堆顶R[1]可能违反堆的性质,因此需要对当前无序区(R1,R2,……Rn-1)调整为新堆,然后再次将R[1]与无序区最后一个元素交换,得到新的无序区(R1,R2….Rn-2)和新的有序区(Rn-1,Rn)。不断重复此过程直到有序区的元素个数为n-1,则整个排序过程完成。
2.2 动图演示

代码:
#include<bits/stdc++.h>
using namespace std;
int a[1000],n;
int len;
void swapp(int a[],int x,int y){
int tmp=a[x];
a[x]=a[y];
a[y]=tmp;
}
void adjust(int id,int len){///调整当前以id为根的树
/// cout<<"id: "<<id<<" len:"<<len<<endl;
int maxid=id;
if( (id<<1)<=len && a[maxid]<a[id<<1] ){
maxid=(id<<1);
}
if( (id<<1|1)<=len &&a[maxid]<a[id<<1|1] ){
maxid=(id<<1|1);
}
if(maxid!=id){
swapp(a,maxid,id);
adjust(maxid,len);
}
/* for(int i=1;i<=n;i++){
cout<<"*"<<a[i]<<" ";
}
cout<<endl;*/
}
int main(){
scanf("%d",&n);
for(int i=1;i<=n;i++){
scanf("%d",&a[i]);
}///默认构建完全二叉树
for(int i=n/2;i>=1;i--){
adjust(i,n);
}
for(int i=n;i>=2;i--){
swapp(a,1,i);///此时a[i]便是最大的
///此时排【1~i-1】
for(int j=(i-1)/2;j>=1;j--){
adjust( j , i-1 );
}
}
for(int i=1;i<=n;i++){
printf("%d ",a[i]);
}
}
2.4 算法分析
- 最佳情况:T(n) = O(nlogn)
- 最差情况:T(n) = O(nlogn)
- 平均情况:T(n) = O(nlogn)
