There are three general types of parsers for grammars
| universal | top-down | bottom-up |
|---|---|---|
| Cocke-Younger-Kasami algorithm, Earley's algorithm | ||
| parse any grammar, inefficient | work only for subclasses of grammars | work only for subclasses of grammars |
syntactic errors strategies for error recovery:panic-mode,phrase-level recovery,error-productions,global-correction a compiler is expected to assist the programmer in locating and tracking down errors
error handler in a parser has goals:
- Report the presence of errors clearly and accurately.
- Recover from each error quickly enough to detect subsequent errors.
- Add minimal overhead to the processing of correct programs.
###一、context-free grammar 由一系列production组成
- terminal symbols
- nonterminals
- productions
- start symbol ####Derivation sentential form, sentence, left-sentential form, leftmost derivation, rightmost derivation
Every construct that can be described by a regular expression can be described by a grammar, but not vice-versa.
Immediate left recursion can be eliminated by the following technique 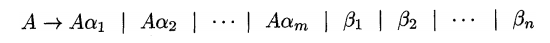
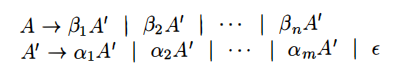
Algorithm 4.19, below, systematically eliminates left recursion from a grammar. 
###二、top-down parsing top-down parsing method 有3种,recursive-descent parsing, predictive parsing 和 nonrecursive predictive parsing,predictive parsing 是一种特殊的 recursive-descent parsing。
有一类 predictive parsing 一定能够解析的 grammar 称为 LL(1) grammar, left-recursive grammar 和 ambiguous grammar 一定不是 LL(1) grammar。
当且仅当一个 grammar \(G\) 满足下列条件时,\(G\) 才能成为一个 LL(1) grammar:
若 \(A \to \alpha | \beta\) 是两个不同的 productions, 则 1)\(FIRST(\alpha) \cap FIRST(\beta) = \emptyset\) 2)若 \(\epsilon \in FIRST(\beta)\), 则 \(FIRST(\alpha) \cap FOLLOW(\beta) = \emptyset\); \(\epsilon \in FIRST(\alpha)\) 同理。
为predictive parsing method 构造 parsing table 的算法: 输入为 grammar \(G\), 输出为 parsing table \(M\)。 对 grammar \(G\) 中的所有 production \(A \to \alpha\) 执行以下两步操作:
- \(\forall a \in FIRST(\alpha)\), 将$A \to \alpha$添加到 \(M[A,a]\) 中
- 若$\epsilon \in FIRST(\alpha)$, 则 \(\forall b \in FOLLOW(\alpha)\), 将 $A \to \alpha$添加到 \(M[A,b]\) 中 若 \(\exists A, a, s.t. M[A, a] = \emptyset\) , 则令$M[A, a] =$ error
注意,对于 LL(1) grammar, table \(M\) 中的每一个 entry 至多包含一条 production。 考虑$A \to \alpha | \beta$,我们来说明它们不可能出现在同一个 entry 中。 LL(1) grammar 的条件 1 说明,这两条 production 经过步骤 1 ,不可能出现在同一个 entry 中 LL(1) grammar 的条件 1 说明$FIRST(\alpha), FIRST(\beta)\(不可能同时包含\)\epsilon$, 所以两条 production 至多只有一条能经过步骤 2 添加到 \(M\) 中, 而LL(1) grammar 的条件 2 又说明,经过步骤 2 添加到 \(M\) 中的那条 production 与另外一条 production 不可能出现在同一个 entry 中。
###三、bottum-up parsing 下面介绍 3 种 bottum-up 方法,SLR, conanical LR (LR for short) 和 LALR, 它们都基于 shift-reduce 方法
我们先看一下 3 种 LR 型 parser 的共同点,然后再看它们之间的差异
####1.LR 型 parser 的构造过程 \(item \to DFA \to parsing\) \(table\) \(DFA\) 的一个 \(state\) 对应一个由若干 \(item\) 构成的一个 \(set\)
####2.LR型 parser 的结构和工作原理  LR 型的 parser 结构如上图所示,有一个存储 state 的栈, 一块存储输入的缓冲区, 还有一张用来做决策的 parsing table。 1)parser 每次都根据栈顶的 state 和缓冲区中下一个输入的 terminal 去查询 parsing table 的 action 区域,决定接下来是 shift, reduce, accept 还是 error。 2)如果是 reduce, 则要弹出栈顶代表 handle 的若干 state, 再根据新的栈顶 state 和用来代替 handle 的 nonterminal 去查询 parsing table 的 goto 区域,并将跳转的下一个 state 压入栈顶或者是 error。 ps:从任意其它 state 进入 state j 一定是通过相同的 grammar symbol X。 pss:所有的 LR 型 grammar 都是 unambiguous 的。
LR 型的 parser 结构如上图所示,有一个存储 state 的栈, 一块存储输入的缓冲区, 还有一张用来做决策的 parsing table。 1)parser 每次都根据栈顶的 state 和缓冲区中下一个输入的 terminal 去查询 parsing table 的 action 区域,决定接下来是 shift, reduce, accept 还是 error。 2)如果是 reduce, 则要弹出栈顶代表 handle 的若干 state, 再根据新的栈顶 state 和用来代替 handle 的 nonterminal 去查询 parsing table 的 goto 区域,并将跳转的下一个 state 压入栈顶或者是 error。 ps:从任意其它 state 进入 state j 一定是通过相同的 grammar symbol X。 pss:所有的 LR 型 grammar 都是 unambiguous 的。
####3.SLR, LR 和 LALR 的区别 三种 paser 使用了不同的 item,
| item | parser | grammar |
|---|---|---|
| LR(0) | SLR | SLR |
| LR(1) | LR | LR |
| LALR(1) | LALR | LALR |