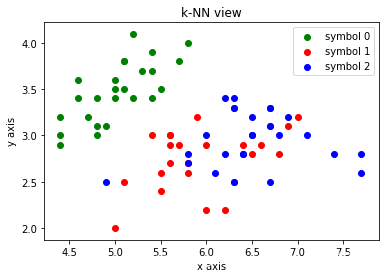
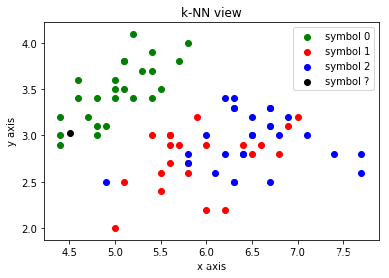
from math import sqrt
distances =[]for x0 in x_train:
d = sqrt(np.sum((x-x0)**2))
distances.append(d)#将距离排序(由大到小)返回的是元素下标
near = np.argsort(distances)
k =3#选择出前5个最近元素的类别
topK_y =[y_train[i]for i in near[:k]]
topK_y
[0, 0, 0]
from collections import Counter
#统计元素出现的个数(即代表这鸢尾花类别的数字的个数)
votes = Counter(topK_y)
votes
Counter({0: 3})
出预测的结果,0代表setosa,1代表versicolor,2代表virginica
#找出票数最多的一个元素,该方法返回的是一个元组,我们只需要key值(也就是类别)
result = votes.most_common(1)[0][0]
result
count =0
index =0for j in x_test:
distance =[]
x = j;#计算距离for x1 in x_train:
t = sqrt(np.sum((x-x1)**2))
distance.append(t)
near = np.argsort(distance)
topK_y =[y_train[i]for i in near[:k]]
votes = Counter(topK_y)
result = votes.most_common(1)[0][0]if y_test[index]==result:
count=count+1
index=index+1else:
index=index+1
score=count/25
score