- 全称:Structured Query Language(结构化查询语言)
- 不区分大小写
【】为必填
《》为选填
更新
| 语句 | 作用 |
|---|---|
| create database【D】 | 建立一个名为D的数据库 |
| create table【T】(【C】【int/char(n)/double/Date…】《not null/primary key/default…》【C1】…,【C2】…) | 建立一个名为T的表,列名分别为C,C1,C2,数据类型选一个,约束条件可有可无 |
| alter table【T】add 【C】【int/char(n)/double/Date…】《not null/primary key/default…》 | 给表T添加一列C |
| alter table【T】drop《not null/primary key/default…》 | 在表T中删除完整性约束条件 |
| alter table【T】alter column【C】【int/char(n)/double/Date…】 | 在表T中修改原有列C |
| alter table【T】drop column【C】 | 在表T中删除列C |
| sp_rename【T.C1】【C2】column | 将列C1重命名为C2 |
| sp_rename【T1】,【T2】 | 将表T1重命名为T2 |
| drop table【T】《restrict/cascade》 | 删除表T,restrict当表T有依赖关系不可删除,cascade无限制删除 |
| create《unique/clustered》index【i】on【T】(【C】《asc/desc》) | 给表T的列C建立名为i的索引,unique表示非聚簇索引,clustered表示聚簇索引,区别在于效率,后者高,适用于不经常更新的列。asc代表升序,desc代表降序 |
| drop index【T.i】 | 删除表T的索引i |
查询
【B】对列名使用的表达式
| 表达式 | 含义 |
|---|---|
| 2020-Age | 2020减age的值 |
| UPPER(name) | 将name的值大写输出 |
| LOWER(dep) | 将dep的值小写输出 |
【F】对列名使用的条件
| 条件 | 含义 |
|---|---|
| grade between 65 and 75 | grade列中值在65至75之间 |
| sex!=‘女’ | sex列中值不为女 |
| age=‘20’ or age=‘21’ | age列中值为20或21 |
| Cno in (‘001’,‘002’) | Cno列中值在集合{001,002}中 |
| Sdep not in (‘5’,‘6’) | Sdep列中值不在集合{5,6}中 |
| Grade is null | Grade列的值是空 |
| Grade is not null | Grade列的值不空 |
【M】模糊查询
| 表达式 | 含义 |
|---|---|
| 梁% | 值的开头第一字必须是梁 |
| 梁_ | 值必须是两个字,第一个字是梁 |
| %梁% | 值里有梁字 |
| _梁_ | 值必须是三个字,第二个字是梁 |
| _梁% | 值的第二个字是梁 |
| %梁_ | 值的倒数第二个字是梁 |
【H】库函数查询
| 函数名 | 功能 |
|---|---|
| SUM(《all/distinct》【C】/【B】) | 返回列C或表达式B的值的总和,distinct代表消除重复组 |
| AVG(《all/distinct》【C】/【B】) | 返回列C或表达式B的值的平均值 |
| MIN(【C】/【B】) | 返回列C或表达式B的值的最小值 |
| MAX(【C】/【B】) | 返回列C或表达式B的值的最大值 |
| COUNT(*) | 返回行数 |
| COUNT(《all/distinct》【C】) | 返回列C的记录数 |
单表查询
| 语句 | 作用 |
|---|---|
| select【C】,【C1】…from【T】 | 在表T中展示列C,C1的信息 |
| select * from【T】 | 在表T中展示所有列的信息 |
| select【B】《as/空格》【N】from【T】 | 在表T中展示对列使用表达式B之后的信息,得到新列的名字为N |
| select《distinct》【C】from【T】 | 在表T中展示列C的信息,并消除重复行 |
| select【C】from【T】where【F】 | 查询表T中满足条件F的行,并展示对应列C的信息 |
| select【C】from【T】where【C1】《like/not like》【M】 | 在表T中模糊查询列C1的值《满足/不满足》M的行,并展示对应列C的信息 |
| select【C】from【T】where【F】order by【C1】《asc/desc》 | 在表T中查询满足条件F的行,并将结果按列C1值的《升序/降序》排列,最后展示对应列C的信息 |
| select【H】from【T】where【F】 | 在表T中查询满足条件F的行,使用函数H处理对应的列得到新列。 |
| select【C】from【T】group by【C1】having【F】 | 将表T中列C1的值相同的行进行分组,从所有组中查询符合条件F的组,并展示对应列C的信息 |
技巧
- 所有的名字不得冲突,即名字唯一,不能使用关键字
- 名字与大小写无关,名字以字母开头
- 一表中最多有254个列
- 一表最多有249个索引
- group by常和库函数结合做统计
实战模拟:
表名:Student
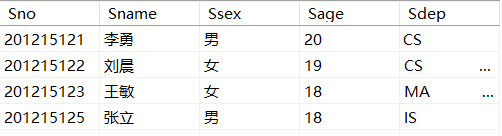
- 统计男生中年龄大于18岁的人的个数?
select COUNT(Sno) as "大于18岁的男生人数" from Student where Sage>18

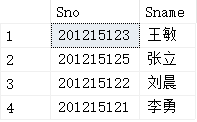
2. 将学生按年龄升序排列,得到对应的姓名学号?
select Sno,Sname from Student order by Sage asc
3.查询所有不姓李的同学学号和系部,要求系部小写输出?
select Sno, LOWER(Sdep) 小写系部 from Student where Sname not like '李%'

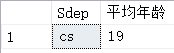
4.查询每个系人数大于1人的平均年龄?
select Sdep,AVG(Sage) as "平均年龄" from Student group by Sdep having COUNT(Sno)>1