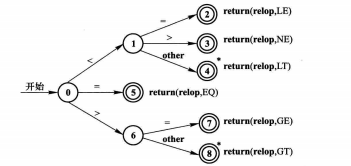
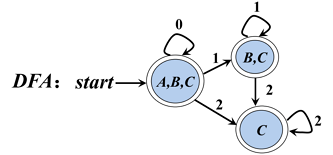
状态转化图,就是用深度优先的树形结构,表现扫描器的识别状态与识别路径。两个圈代表识别完成返回识别值,线段上字符,是识别的下一个值,作为路径选择的条件。*代表回退扫描的指针。相应的有状态转换表。
确定(NFA)与不确定的有限自动机(DFA),其实就是上面的状态转换图。确定有限自动机就是从一个状态的出发的边都各不相同,而不确定有限自动机则是从一个状态出发的边有可能相同。
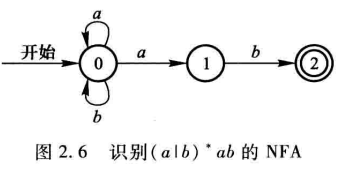
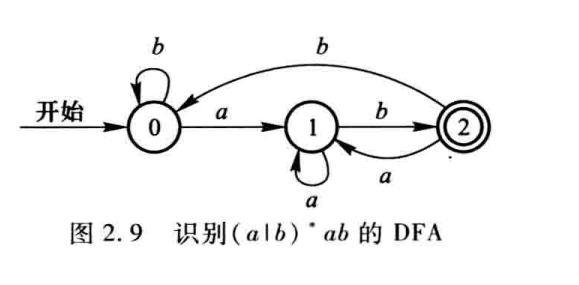
其中不确定自动机还有两种,有ε的和没ε的。

※将不确定自动机变换到确定自动机
其实就是把一个状态能通过相同条件到达的状态合并为一个路径。
将以下NFA转换为DFA


按下表不断构建,到Ia,Ib中出现的集合,全部都出现在I中。并且将他们重新编号
(终态是那些有Y的集合,Y为原先NFA的终态)


转成DFA的结果:


※DFA化简成最简DFA:
直接看例子理解更简单到位。
参考: https://www.jianshu.com/p/c779953434ac
预备
- 最简化的DFA:这个DFA没有多余状态、也没有两个相互等价的状态。一个DFA可以通过消除无用状态、合并等价状态而转换成一个与之等价的最小状态的有穷自动机。
- 无用状态:从自动机开始状态出发,任何输入串也发到达的那个状态,或者这个状态没有通路可达终态。
- 等价转态:两个状态,识别相同的串,结果都同为正确或错误,这两个状态就是等价的。
- 区别状态:不是等价状态。
化简DFA
-
分割法:把一个DFA(不含多余状态)的状态分割成一些不相交的子集,并且任意两个子集之间的状态都是可区别状态,同一子集内部的状态都是等价状态。
-
步骤(按分割法)
- I0 = 非状态元素构成的集合,I1 = 终态元素构成的集合
- 经过多次划分后,要保证,任意一个Ik中的元素通过move(Ik,某个字符)的结果都同属于一个Iz,这时候划分完成。否则把状态不同的单独划分出去。
- 重复上一步,直至没有新的I子集增加。
- 从子集中任选一个代替整体,画出最简DFA。
例子
- 题目:将下图DFA M最小化
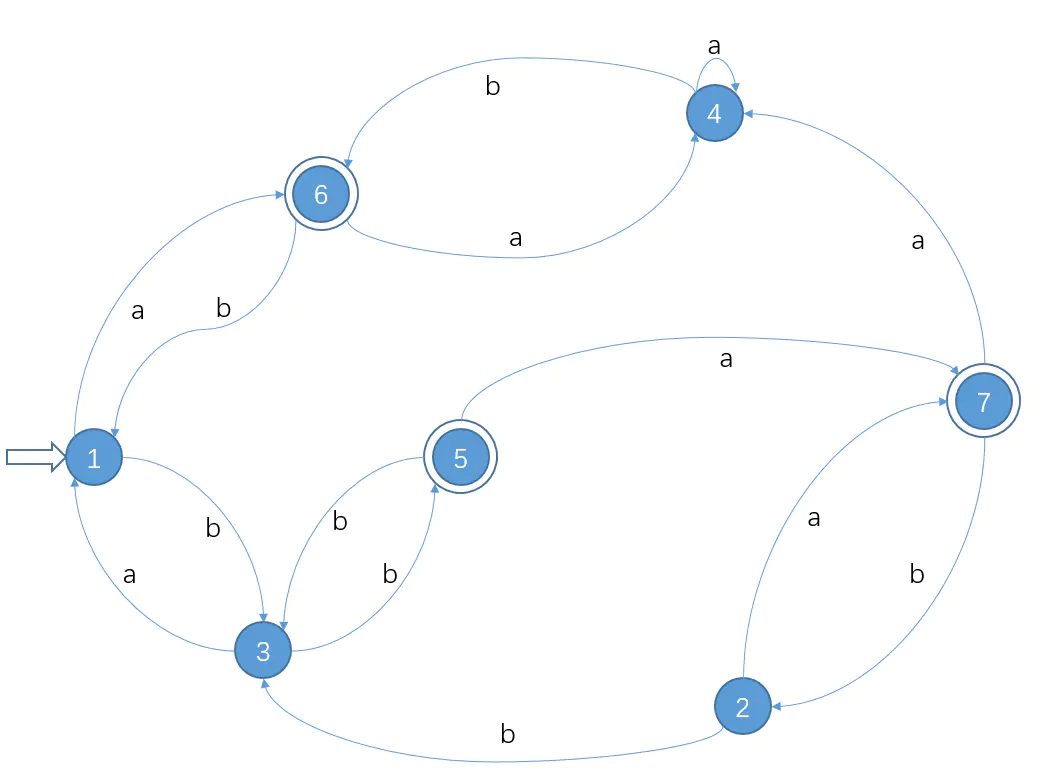
分割成I0,I1
-----------------I0、I1分割-------------------
I0 = {1,2,3,4} ; 非终态
I1 = {5,6,7} ; 终态
检验I0中元素的等价性,不等价就分割
move(1,a) = 6 ∈I1
move(1,b) = 3 ∈I0
move(2,a) = 7 ∈I1
move(2,b) = 3 ∈I0
move(3,a) = 1 ∈I0
move(3,b) = 5 ∈I1
move(4,a) = 4 ∈I0
move(4,b) = 6 ∈I1
可以发现,{1,2}是等价的,{3,4}是等价的
所以现在分割成了:I2 = {1,2}, I1 = {5,6,7}, I3 = {3,4}
检测I2中元素的等价性,不等价就分割
move(1,a) = 6 ∈I1
move(1,b) = 3 ∈I3
move(2,a) = 7 ∈I1
move(2,b) = 3 ∈I3
可以发现,是等价的,不用分割
检测I3中元素的等价性,不等价就分割
move(3,a) = 1 ∈I2
move(3,b) = 5 ∈I1
move(4,a) = 4 ∈I3
move(4,b) = 6 ∈I1
可以发现,不是等价的,分割成{3},{4}
所以现在分割成了:I2 = {1,2}, I1 = {5,6,7}, I4 = {3}, I5 = {4}
检测I1中元素的等价性,不等价就分割
















move(5,a) = 7 ∈ I1
move(5,b) = 3 ∈ I4
move(6,a) = 4 ∈ I5
move(6,b) = 1 ∈ I2
move(7,a) = 4 ∈ I5
move(7,b) = 2 ∈ I2
可以发现,不是等价的,分割成{6,7}, {5}
所以现在分割成了:I2 = {1,2}, I4 = {3}, I5 = {4}, I6 = {5},I7 = {6,7}
检测后发现,不可再分割,所以最终分割结果就是:I2 = {1,2}, I4 = {3}, I5 = {4}, I6 = {5},I7 = {6,7}
※从正规式到有限自动机。
参考: https://blog.csdn.net/starter_____/article/details/86661819
要将正则表达式RE转换到DFA比较困难,因此,我们往往先将正则表达式RE转换为NFA,再将NFA转换为DFA
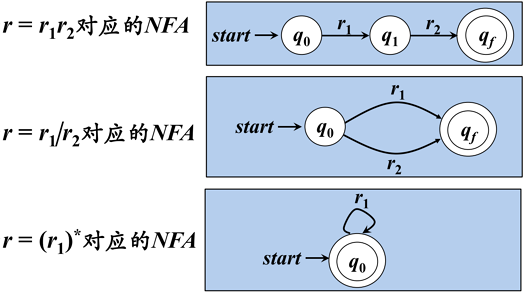
根据RE构造NFA
RE: r=(alb)*abb
(1)求NFA:
※从NFA到DFA的转换
DFA的每个状态都是一个由NFA中的状态构成的集合,即NFA状态集合的一个子集。
(2)求转换表:
(3)求DFA:
(1)以0为初始态 (2)当状态为0,输入为a时,会进入状态{0,1} (3)当状态为0,输入为b时,继续进入状态0 (4)当状态为0,输入为a时,会进入状态{0,1};当状态为1,输入为a时,不进入任何状态。{0,1}∪Ф={0,1},故当状态为{0,1},输入为a时,进入状态{0,1} (5)当状态为0,输入为b时,会进入状态0;当状态为1,输入为b时,会进入状态2。{0}∪{2}={0,2},构建新状态{0,2},故当状态为{0,1},输入为a时,进入状态{0,2} (6)当状态为0,输入为a时,会进入状态{0,1};当状态为2,输入为a时,不进入任何状态。{0,1}∪Ф={0,1},故当状态为{0,2},输入为a时,进入状态{0,1} (7)当状态为0,输入为b时,会进入状态0;当状态为2,输入为b时,会进入状态3。{0}∪{3}={0,3},构建新状态{0,3},故当状态为{0,2},输入为b时,进入状态{0,3} (8)当状态为0,输入为a时,会进入状态{0,1};当状态为3,输入为a时,不进入任何状态。{0,1}∪Ф={0,1},故当状态为{0,3},输入为a时,进入状态{0,1}
其它示例
示例1:(不带ε边的NFA)
RE: r=a* a b* b c* c
(1)求NFA:
(2)求转换表:
(3)求DFA:
示例2:(带ε边的NFA)
RE: r=0* 1* 2*
(1)求NFA
(2)求转换表
(3)求DFA
※词法分析器的生成器——Lex
主要看图2.21,简而言之,就是Lex语言——>C语言——>词法分析器程序。这就是一个词法分析器的生成过程了。有这句话可以不看下面这一长串了。
Lex通常按图2.21描绘的方式使用。首先,词法分析器的说明用Lex语言表达在程序lex.1中,然后lex.l通过Lex编译器,产生C语言程序lex.yy.c。程序lex.yy.c包括从lex.1的正规式构造出的转换图(用表格形式表示)和使用这张转换图识别词法单元的标准子程序。在lex.1中,和正规式相关联的动作是用C语言代码表示的,它们被直接复制到lex.yy.c中。最后,lex.yy.c被编译成目标程序a.out,它就是把输入串识别成记号序列的词法分析器。
词法分析器可以当作语法分析器的一个子程序,它最终的任务是两个,一个是执行一个动作A (这个动作可能是对扫描指针的移动,继续往后读或者是回退,或者是把控制权交给语法控制器),还有一个就是向语法分析器返回值(记号名和相应的属性)。
下面的作为补充,感觉也不是太重要,比较很少接触也不知道以后接不接触得到,就是Lex语言的程序组成。
有以下三个部分:
其中每条翻译规则的形式如下:
![]()
其中的每一个模式都代表一个正规式,意思就是不会多个模式来拼凑起来表达一个正规式。
动作由C语言编写。