stack、unstack
stack方法和unstack方法都是对数据表重排的方法,unstack是stack方法的逆转。其中stack方法不能对series进行操作,而unstack可以
下面看一下这两个方法都是怎么对数据表格进行重排的。
实验数据:
data = {'date': ['2018-08-01', '2018-08-02', '2018-08-03', '2018-08-01', '2018-08-03', '2018-08-03',
'2018-08-01', '2018-08-02'],
'variable': ['A','A','A','B','B','C','C','C'],
'value': [3.0 ,4.0 ,6.0 ,2.0 ,8.0 ,4.0 ,10.0 ,1.0 ]}
df = pd.DataFrame(data=data, columns=['date', 'variable', 'value'])
print(df)
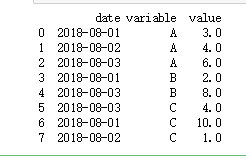
df.stack()

可以看到,使用stack方法后,原本数据表的索引变成了series的新的外层索引,原本的列名变成了二级索引,
它的重排方法依据:
旧表的索引1+列名+值
…
列名+值
…
旧表的索引n+列名+值
…
列名+值
…
unstack方法可以逆转stack的操作,也有自己的重排方法
df.unstack()

df.unstack().unstack()

如果原表只有一级索引,unstack就将每一个列都分出来,然后全部纵向叠加在一起,每一个列名作为新的一级索引,原本的索引作为二级索引
如果原表有二级索引,那么unstack就会将二级索引作为新的列名,一级索引作为新的索引
pivot、melt
-
pivot的主要参数
index: 用于制作新框架索引的标签
columns: 用于制作新框架列的标签
values: 用于填充新框架值的值

df2 = df.pivot(index='date',columns='variable',values='value')
# 将date作为新的索引,将variable的值作为新的列,value的值对应date和variable的值填充新表
df2
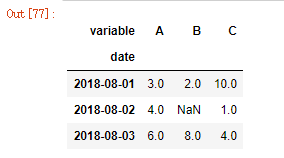
pivot将长表转换为宽表,value没有的值以缺失值填充。
但是pivot的index和columns只能接受一个列作为参数,所以如果有需要可以用pivot_table代替。
melt的作用于pivot相反,它的作用是将宽表转换为长表
-
melt的主要参数
id_vars: 标识列
value_vars: 需要被整合的列
var_name:value_vars列的列名
value_name: value列的名字
col_level: 列索引的级别(如果列是多重索引的话需要)
# 以A这一列作为标识列进行转换,将宽表转换为长表
df2.melt(id_vars=['A'])
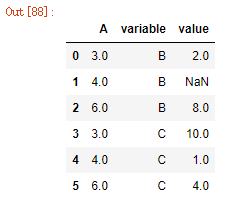
原本跟A(标识列)处于同一行的值出现在value列,并且对应的variable列的值“B”是原本value的列名
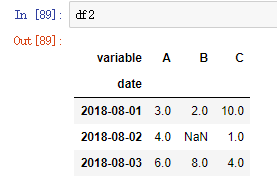
# 重置df2索引值
# 将date从索引位置取消,变成正常的一列
df2.reset_index(inplace=True)
df2
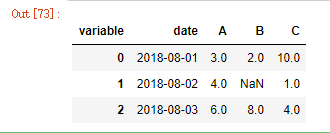
这里我们使用melt将上面的数据表转换为一个长表
# 以date日期作为标识列,将上面的宽表转换为长表
# A,B,C三列作为变量列
# 可以顺便设置变量列和value列的列名
df3 = df2.melt(id_vars='date', value_vars=['A','B','C'], var_name='eng_name', value_name='score')
df3

