concat函数
参数说明:
| 参数 | 说明 |
|---|---|
| objs | 接收多个Series、DataFrame、Panel的组合。表示参与连接的pandas对象的列表的组合。无默认 |
| axis | 轴向选择,默认为0 |
| join | 连接方式,inner(交集)和outer(并集),默认为outer |
| join_axes | 接收Index对象。表示用于其他n-1条轴的索引,不执行并集/交集运算 |
| ignore_index | 接收boolean。表示不保留轴上的索引,产生一组新索引range(total_length)。默认为False |
| keys | 接收sequence。表示与连接对象有关的值,用于写成连接轴向上的层次化索引。默认为None |
| levels | 接收包含多个sequence的list。表示在指定keys参数后,指定用作层次化索引各级别上的索引。默认为None |
| names | 接收list。表示在设置了keys和levels参数后,用于创建分层级别的名称。默认为None |
| verify_integrity | 接收boolean。检查新连接的轴是否包含重复项。如果发现重复项,则引发异常。默认为False |
axis、join
df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2'],
'B': ['B0', 'B1', 'B2'],
'C': ['C0', 'C1', 'C2']},
index=[0, 1, 2])
df2 = pd.DataFrame({'A': ['A3', 'A4', 'A5'],
'B': ['B3', 'B4', 'B5'],
'C': ['C3', 'C4', 'C5']},
index=[2,3,4])
df3 = pd.DataFrame({'A': ['A6', 'A7', 'A8'],
'B': ['B6', 'B7', 'B8'],
'C': ['C6', 'C7', 'C8']},
index=[4,5,6])
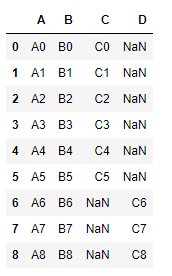
pd.concat([df1,df2,df3],join='outer',axis=0)
这种连接方式会将列名相同的叠加在一起,如果有不同的列名会以NaN补充其他对象在该列的位置,如果join的参数是inner的话,那么合并后的表只会出现大家都有的AB两列,就是交集。

如果是axis=1也就是行连接的话,其实也差不多,只是连接的方向改变了,原理相同,根据行索引来合并,并集取全部,有些对象有的行,其他对象没有的行会填充NaN,交集的话只会去所有对象都有的行来合并。
pd.concat([df1,df2,df3],join='outer',axis=1)

keys
可以连接的对象指定一个键值,这样连接完后我们可以看到每一部分的数据属于哪个对象
pd.concat([df1,df2,df3],join='outer',axis=1,keys=['a','b','c'])

如果keys的值多与连接的对象,那么只会去前面部分的几个值,如果少了,那么确实几个key值,就有几个对象不进行连接
演示一下:
这里值给定了keys两个参数,而连接的是三个对象,最终结果只有前面两个对象进行连接。
pd.concat([df1,df2,df3],join='outer',axis=1,keys=['a','b'])
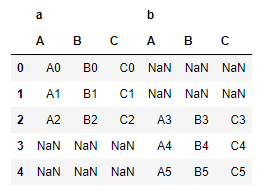
keys还有另外一种用法,就是使用字典来指定,结果是相同的,下面的例子采用的是列连接
pd.concat({'a':df1,'b':df2,'c':df3},join='outer')

ignore_index
这个参数其实很简单,它的意义就是,如果你觉得数据表格的行索引没什么用,是可以忽略的,那么你可以通过设置这个参数为True,得到的结果会自动将行索引变成最简单的序列。
拿上面的例子来看:
这里它的行索引是从原来的对象带来的,如果这些索引没什么用,我们可以使用ignore_index参数忽略它
pd.concat([df1,df2,df3],join='outer',ignore_index=True)
append
参数列表:
| 参数 | 说明 |
|---|---|
| other | 接收DataFrame、series、dict、list这样的数据结构 |
| ignore_index | 默认值为False,如果为True则不使用用来的index标签 |
| verify_integrity | 默认值为False,如果为True且ignore_index为False时,当创建相同的index时会抛出ValueError的异常 |
append方法可以将两个列名相同的表纵向叠加起来,也可以给表添加新的列,功能相当于axis=0,join=outer的concat函数连接两个表,但是append可以添加Series、dict、list成为表的新列
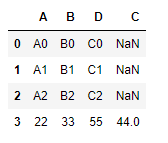
添加series(注意,必须要指定series的name,否则会报错)
df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2'],
'B': ['B0', 'B1', 'B2'],
'D': ['C0', 'C1', 'C2']},
index=[0, 1, 2])、
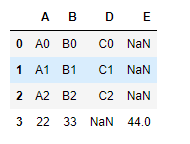
s1 = pd.Series({'A':22,'B':33,'C':44,'D':55},name='a')
df1.append(s1,ignore_index=True)
添加list
如果列表是一维的,那么会以列的形式添加,如果是二维的,那么会以行的形式添加,如果是三维的,那么会以单个元素的形式添加
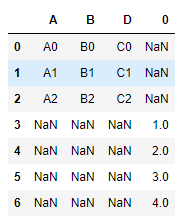
一维list
l1 = [1,2,3,4]
df1.append(l1,ignore_index=True)
二维list
l1 = [[1,2,3,4]]
df1.append(l1,ignore_index=True)
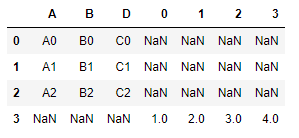
三维list
l1 = [[[1,2,3,4]]]
df1.append(l1,ignore_index=True)
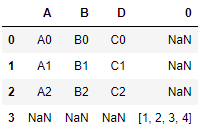
添加字典
d1 = {'A':22,'B':33,'E':44}
df1.append(d1,ignore_index=True)
merge
参数说明:
| 参数 | 说明 |
|---|---|
| left | 接收DataFrame或Series。表示要添加的数据1.无默认 |
| right | 接收DataFrame或Series。表示要添加的数据2.无默认 |
| how | 接收left、right、inner、right。表示数据的连接方式,默认为inner |
| on | 接收string或sequence。表示两个数据合并的主键(必须一致)。默认为None |
| left_on | 接收string或sequence。表示left参数接收数据用于合并的主键。默认为None |
| right_on | 接收string或sequence。表示right参数接收数据用于合并的主键。默认为None |
| left_index | 接收boolean。表示是否将left参数接收数据的index作为连接主键。默认为False |
| right_index | 接收boolean。表示是否将right参数接收数据的index作为连接主键。默认为False |
| sort | 接收boolean。表示是否根据连接键对合并后的数据进行排序。默认为False |
| suffixes | 接收tuple。表示用于追加到left和right参数接收数据列名相同时的后缀。默认为(’_x’,’_y’) |
merge方法与数据库的连表查询很相似,接收两个表的数据,通过各种不同的参数设置查询不同的结果。
实验数据:
df1 = pd.DataFrame({'A': ['a', 'b', 'c'],
'B1': [0,1,2],
'C1': ['C0', 'C1', 'C2']},
index=[0, 1, 2])
df2 = pd.DataFrame({'A': ['a', 'b', 'd'],
'B2': ['B3', 'B4', 'B5'],
'C2': ['C3', 'C4', 'C5']},
index=[2,3,4])
不同的连接方式
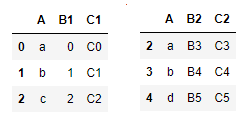
how参数表示两个表的连接方式,
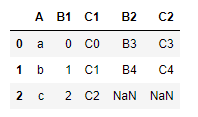
left(左连接),取左表的全部数据,如果没有指定连接键,右表根据和左表相同的字段来匹配进行。否则根据连接键来匹配
pd.merge(left=df1,right=df2,how='left')
right(右连接),与左连接一样,主表不同
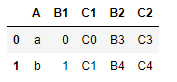
inner(交集),在这种连接模式下,两表只会取在主键中,大家都有的值进行组合
pd.merge(left=df1,right=df2,how='inner',on='A')
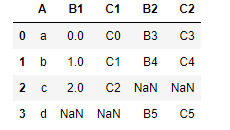
outer(并集),取两表连接键的索引值,没有该值的表的将以NaN填充
pd.merge(left=df1,right=df2,how='outer',on='A')
连接关键字
在默认的情况下会自动将两表相同的字段作为连接关键字,但是如果没有相同的字段或者相同的字段多余一个,那么继续连接会报错,所以我们一般使用的时候都要指定连接关键字。
第一种就是使用on关键字,这个方法只有两表关键字相同的情况下可以使用,
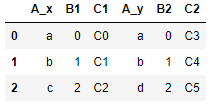
如果我们要通过两个表两个不同的字段名进行连接,那么可以使用left_on和right_on参数来分别指定两个表的关键字是什么,然后就会根据这两个字段的值进行匹配
df1 = pd.DataFrame({'A': ['a', 'b', 'c'],
'B1': [0,1,2],
'C1': ['C0', 'C1', 'C2']},
index=[0, 1, 2])
df2 = pd.DataFrame({'A': ['a', 'b', 'd'],
'B2': [0,1,2],
'C2': ['C3', 'C4', 'C5']},
index=[2,3,4])
pd.merge(left=df1,right=df2,left_on='B1',right_on='B2')
我们不仅仅可以使用字段来进行匹配,还可以使用索引作为关键字
df1
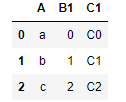
df2
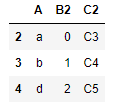
pd.merge(left=df1,right=df2,left_on='B1',right_index=True)

上面这个例子用df2的索引值作为关键字,df1的B1列的值作为关键字进行匹配,可以看到只有2是两者都有的,所以最后结果只有一行。
当两个表有相同的字段名,而又不是作为主键,那么他们合并后会出现_x,_y的默认后缀,suffixes参数可以自定义这个后缀
pd.merge(left=df1,right=df2,left_on='B1',right_index=True,suffixes=['-a','-b'])

join
join的用法与merge有相似之处,这里只提一下
df1.join(df2,rsuffix='a',on='B1',how='outer')
相当于
pd.merge(df1,df2,left_on='B1',right_index=True,how='outer')
on–>接收左表df1的连接键(根据“key”进行左连接),默认是以index为主键,右表df2以index为主键,
rsuffix与lsuffix相当于merge中的suffixes,指定左右表字段重复时的后缀。没有默认值,一般需要自己手动指定。
combine_first
df5=pd.DataFrame({
0:[1,2,np.nan],
1:[4,np.nan,6]
})
df6=pd.DataFrame({
0:[1,2,33],
1:[4,55,np.nan]
})
df5.combine_first(df6)
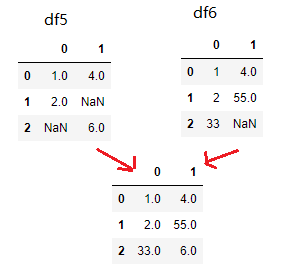
当左表存在空值时,右表对应位置的值会替换左表的空值,但是必须是字段名和索引值相同的位置,如果两个表不是结构相同的,那么就会默认采用全连接(并集)的方式联结两表
