hbase(coprocessor)整合es构建二级索引
一.简介
HBase包含两种协处理器:Observers和Endpoint
1.RegionObserver:
eg:可以在客户端进行get操作时,通过preGet进行权限控制
//主要方法:
preOpen, postOpen: Called before and after the region is reported as online to the master.
preFlush, postFlush: Called before and after the memstore is flushed into a new store file.
preGet, postGet: Called before and after a client makes a Get request.
preExists, postExists: Called before and after the client tests for existence using a Get.
prePut and postPut: Called before and after the client stores a value.
preDelete and postDelete: Called before and after the client deletes a value.
2.WALObserver
提供基于WAL的写和刷新WAL文件的操作,一个regionserver上只有一个WAL的上下文。
preWALWrite/postWALWrite: called before and after a WALEdit written to WAL.
3.MasterObserver:
提供基于诸如ddl的的操作检查,如create, delete, modify table等,同样的当客户端delete表的时候通过逻辑检查时候具有此权限场景等。其运行于Master进程中。
preCreateTable/postCreateTable: Called before and after the region is reported as online to the master.
preDeleteTable/postDeleteTable
4.Endpoint Coprocessor:
Endpoint processors allow you to perform computation at the location of the data. An example is the need to calculate a running average or summation for an entire table which spans hundreds of regions.
In contrast to observer coprocessors, where your code is run transparently, endpoint coprocessors must be explicitly invoked using the CoprocessorService() method available in Table or HTable.
Endpoint Coprocessor需要结合客户端代码进行rpc通信来实现数据的搜集归并。而observer coprocessor只会在server端运行,且仅在特定操作后触发相应的代码。
Starting with HBase 0.96, endpoint coprocessors are implemented using Google Protocol Buffers (protobuf). For more details on protobuf, see Google’s Protocol Buffer Guide. Endpoints Coprocessor written in version 0.94 are not compatible with version 0.96 or later. See HBASE-5448). To upgrade your HBase cluster from 0.94 or earlier to 0.96 or later, you need to reimplement your coprocessor.
HBase 0.94更新到0.96之后的版本,coprocessor也发生了改变(0.96采用了protobuf)。
思考:10亿数据求top10000
二.RegionObserver的代码实现:
package myAPI3;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.CoprocessorEnvironment;
import org.apache.hadoop.hbase.client.Delete;
import org.apache.hadoop.hbase.client.Durability;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.coprocessor.BaseRegionObserver;
import org.apache.hadoop.hbase.coprocessor.ObserverContext;
import org.apache.hadoop.hbase.coprocessor.RegionCoprocessorEnvironment;
import org.apache.hadoop.hbase.regionserver.wal.WALEdit;
import org.apache.hadoop.hbase.util.Bytes;
import org.elasticsearch.client.Client;
import java.io.IOException;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class DataSyncObserver extends BaseRegionObserver {
private static Client client = null;
private static final Log LOG = LogFactory.getLog(DataSyncObserver.class);
/**
* 读取HBase Shell的指令参数
*
* @param env
*/
private void readConfiguration(CoprocessorEnvironment env) {
Configuration conf = env.getConfiguration();
Config.clusterName = conf.get("es_cluster");
Config.nodeHost = conf.get("es_host");
Config.nodePort = conf.getInt("es_port", -1);
Config.indexName = conf.get("es_index");
Config.typeName = conf.get("es_type");
//LOG.info("observer -- started with config: " + Config.getInfo());
}
@Override
public void start(CoprocessorEnvironment env) throws IOException {
LOG.info("-----------------------------------starting-------------------------------------------------------------------------------------");
readConfiguration(env);
client = MyTransportClient.client;
}
@Override
public void postPut(ObserverContext<RegionCoprocessorEnvironment> e, Put put, WALEdit edit, Durability durability) throws IOException {
try {
String indexId = new String(put.getRow());
Map<byte[], List<Cell>> familyMap = put.getFamilyCellMap();
Map<String, Object> json = new HashMap();
for (Map.Entry<byte[], List<Cell>> entry : familyMap.entrySet()) {
for (Cell cell : entry.getValue()) {
String key = Bytes.toString(CellUtil.cloneQualifier(cell));
String value = Bytes.toString(CellUtil.cloneValue(cell));
json.put(key, value);
LOG.info("key---->>"+key+"value---->>"+value);
}
}
System.out.println();
ElasticSearchOperator.addUpdateBuilderToBulk(client.prepareUpdate(Config.indexName, Config.typeName, indexId).setDoc(json).setUpsert(json));
LOG.info("observer -- add new doc: " + indexId + " to type: " + Config.typeName);
} catch (Exception ex) {
LOG.error(ex);
}
}
@Override
public void postDelete(final ObserverContext<RegionCoprocessorEnvironment> e, final Delete delete, final WALEdit edit, final Durability durability) throws IOException {
try {
String indexId = new String(delete.getRow());
ElasticSearchOperator.addDeleteBuilderToBulk(client.prepareDelete(Config.indexName, Config.typeName, indexId));
LOG.info("observer -- delete a doc: " + indexId);
} catch (Exception ex) {
LOG.error(ex);
}
}
}
package myAPI3;
import org.elasticsearch.action.bulk.BulkRequestBuilder;
import org.elasticsearch.action.bulk.BulkResponse;
import org.elasticsearch.action.delete.DeleteRequestBuilder;
import org.elasticsearch.action.update.UpdateRequestBuilder;
import org.elasticsearch.client.Client;
import java.util.Timer;
import java.util.TimerTask;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
public class ElasticSearchOperator {
// 缓冲池容量
private static final int MAX_BULK_COUNT = 10;
// 最大提交间隔(秒),注意,测试时,适当改小
private static final int MAX_COMMIT_INTERVAL = 5*60;
private static Client client = null;
private static BulkRequestBuilder bulkRequestBuilder = null;
private static Lock commitLock = new ReentrantLock();
static {
client = MyTransportClient.client;
bulkRequestBuilder = client.prepareBulk();
bulkRequestBuilder.setRefresh(true);
Timer timer = new Timer();
timer.schedule(new CommitTimer(), 10 * 1000, MAX_COMMIT_INTERVAL * 1000);
}
/**
* 判断缓存池是否已满,批量提交
*
* @param threshold
*/
private static void bulkRequest(int threshold) {
if (bulkRequestBuilder.numberOfActions() > threshold) {
BulkResponse bulkResponse = bulkRequestBuilder.execute().actionGet();
if (!bulkResponse.hasFailures()) {
bulkRequestBuilder = client.prepareBulk();
}
}
}
/**
* 加入索引请求到缓冲池
*
* @param builder
*/
public static void addUpdateBuilderToBulk(UpdateRequestBuilder builder) {
commitLock.lock();
try {
bulkRequestBuilder.add(builder);
bulkRequest(MAX_BULK_COUNT);
} catch (Exception ex) {
ex.printStackTrace();
} finally {
commitLock.unlock();
}
}
/**
* 加入删除请求到缓冲池
*
* @param builder
*/
public static void addDeleteBuilderToBulk(DeleteRequestBuilder builder) {
commitLock.lock();
try {
bulkRequestBuilder.add(builder);
bulkRequest(MAX_BULK_COUNT);
} catch (Exception ex) {
ex.printStackTrace();
} finally {
commitLock.unlock();
}
}
/**
* 定时任务,避免RegionServer迟迟无数据更新,导致ElasticSearch没有与HBase同步
*/
static class CommitTimer extends TimerTask {
@Override
public void run() {
commitLock.lock();
try {
bulkRequest(0);
} catch (Exception ex) {
ex.printStackTrace();
} finally {
commitLock.unlock();
}
}
}
}
package myAPI3;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.transport.InetSocketTransportAddress;
import java.net.InetAddress;
import java.net.UnknownHostException;
import java.util.HashMap;
import java.util.Map;
public class MyTransportClient {
static TransportClient client = null;
static{
//初始化配置信息
Map<String, String> map = new HashMap<String, String>();
map.put("cluster.name", "myEs");
//配置信息对象
Settings.Builder settings = Settings.builder().put(map);
//创建客户端连接
client = TransportClient.builder().settings(settings).build();
//创建连接
try {
client.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("192.168.183.21"), 9300));
client.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("192.168.183.22"), 9300));
client.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("192.168.183.23"), 9300));
} catch (UnknownHostException e) {
e.printStackTrace();
}
}
}
package myAPI3;
//结合需求完善
public class Config {
public static String clusterName;
public static String nodeHost;
public static int nodePort;
public static String indexName;
public static String typeName;
}
我的依赖:(我提供了一些版本的es与hbase的依赖jar包,可以去我的个人中心的资源中免费下载)
<dependencies>
<-- 版本号一定要与集群中hbase ,es版本一致-->
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>2.4.5</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.plugin</groupId>
<artifactId>delete-by-query</artifactId>
<version>2.4.5</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>0.98.12.1-hadoop2</version>
<exclusions>
<exclusion>
<artifactId>jetty-servlet</artifactId>
<groupId>org.eclipse.jetty</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs-client</artifactId>
<version>2.10.0</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>0.98.12.1-hadoop2</version>
<exclusions>
<exclusion>
<artifactId>javax.servlet.jsp</artifactId>
<groupId>org.glassfish.web</groupId>
</exclusion>
</exclusions>
</dependency>
</dependencies>
三.协处理器加载:
完成实现后需要将协处理器打包,对于协处理器的加载通常有三种方法:
1.配置文件加载:即通过hbase-site.xml文件配置加载,一般这样的协处理器是系统级别的,全局的协处理器,如权限控制等检查。
2.shell加载:可以通过alter命令来对表进行scheme进行修改来加载协处理器。
3.通过API代码实现:即通过API的方式来加载协处理器。
上述加载方法中,1,3都需要将协处理器jar文件放到集群的hbase的classpath中。而2方法只需要将jar文件上传至集群环境的hdfs即可。
下面我们只介绍如何通过2方法进行加载。
步骤1:创建表
步骤2:通过alter命令将协处理器加载到表中
先disable指定表,并且卸载之前安装的协处理器。
步骤3:检查协处理器的加载
#详细操作,以下均在hbase客户端操作
create 'poem','cf'
disable 'poem'
desc 'poem'
#卸载之前安装的协处理器
alter 'poem', METHOD => 'table_att_unset',NAME => 'coprocessor$1'
#将jar上传至hdfs并加载到HBase
alter 'poem', METHOD => 'table_att', 'coprocessor' => 'hdfs:///hbase2es-final.jar|myAPI3.DataSyncObserver|1001|es_cluster=myEs,es_host=hdp-01,es_port=9300,es_index=my_poem,es_type=poem'
enable 'poem'
# 理解 coprocessor 的四个参数,分别用'|'隔开的
1、 协处理器 jar 包所在 hdfs 上的路径
2、 协处理器类全限定名
3、 协处理器加载顺序
4、 传参
#检查加载
desc 'poem'
Table poem is ENABLED
poem, {TABLE_ATTRIBUTES => {coprocessor$1 => 'hdfs:///hbase2es-final.jar|myAPI3.DataSyn
cObserver|1001|es_cluster=myEs,es_host=hdp-01,es_port=9300,es_index=my_poem,es_type=poe
m'}
四.协处理器加载失败情况处理:
协处理器被表成功加载后,会update所有此表的region去加载协处理器的。
但如果之前jar包中的hbase或es的版本与集群中不一致,很有可能会加载失败,从而导致hbase宕机,表现为所有的regionServer都会下线。此时,hbase客户端会反复连接regionserver的rpc端口,但一直连不上。
此时,有两种解决办法:
1.在hbase-site.xml文件中设置参数:
hbase.coprocessor.abortonerror //name
false //value
并启动region server可以解决,这样就忽略了协处理器出现的错误,保证集群高可用。
2.卸载协处理器,并重启hbase
五.创建es索引库
也可以根据需求,在协处理器中创建所需的索引库
curl -XPOST '192.168.183.21:9200/my_poem' -d '{
"settings":{
"number_of_replicas": "1",
"number_of_shards": "3"
},
"mappings":{
"poem":{
"dynamic":"strict",
"properties":{
"tt":{"type":"string","index":"analyzed","analyzer": "ik_max_word","search_analyzer": "ik_max_word"},
"at":{"type":"string","index":"not_analyzed"},
"ct":{"type":"string","index":"analyzed","analyzer": "ik_max_word","search_analyzer": "ik_max_word"}
}
}
}
}'
#其中,tt为诗歌的title,ct为content,at为author
#id中传入了hbase的rowkey
#总之,根据需求将需要构建索引的cell写到es中
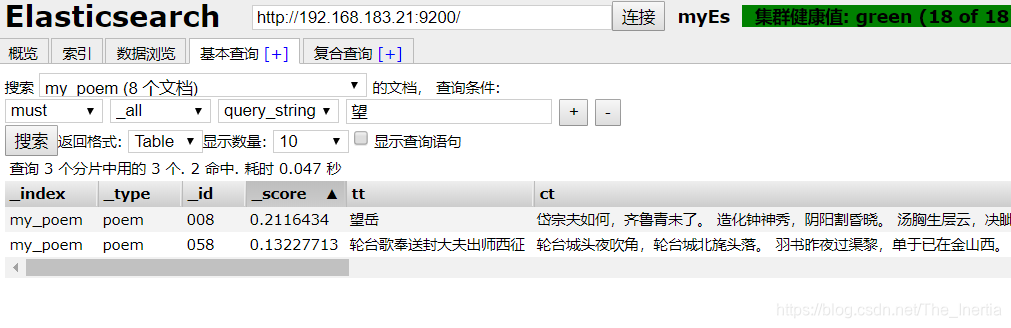
向hbase中插入数据测试成功:
六.报错处理:
参考博客:
