前言:
ONE中了解了爬虫和requests模块的基本使用,这次就来跟着老师来做一个综合性的案例
0x00:案例说明
这次要爬取的是化妆品企业具体的生产许可信息
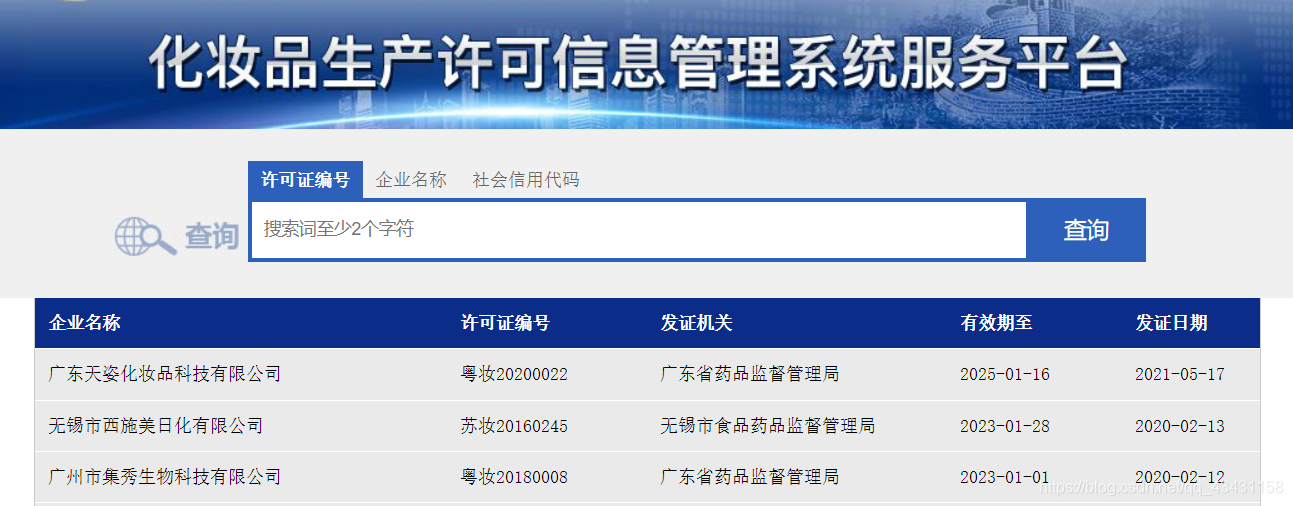

0x01:进行分析
首先要判断这个页面出现的企业的信息是否是动态加载出来的还是随着该url直接出现的
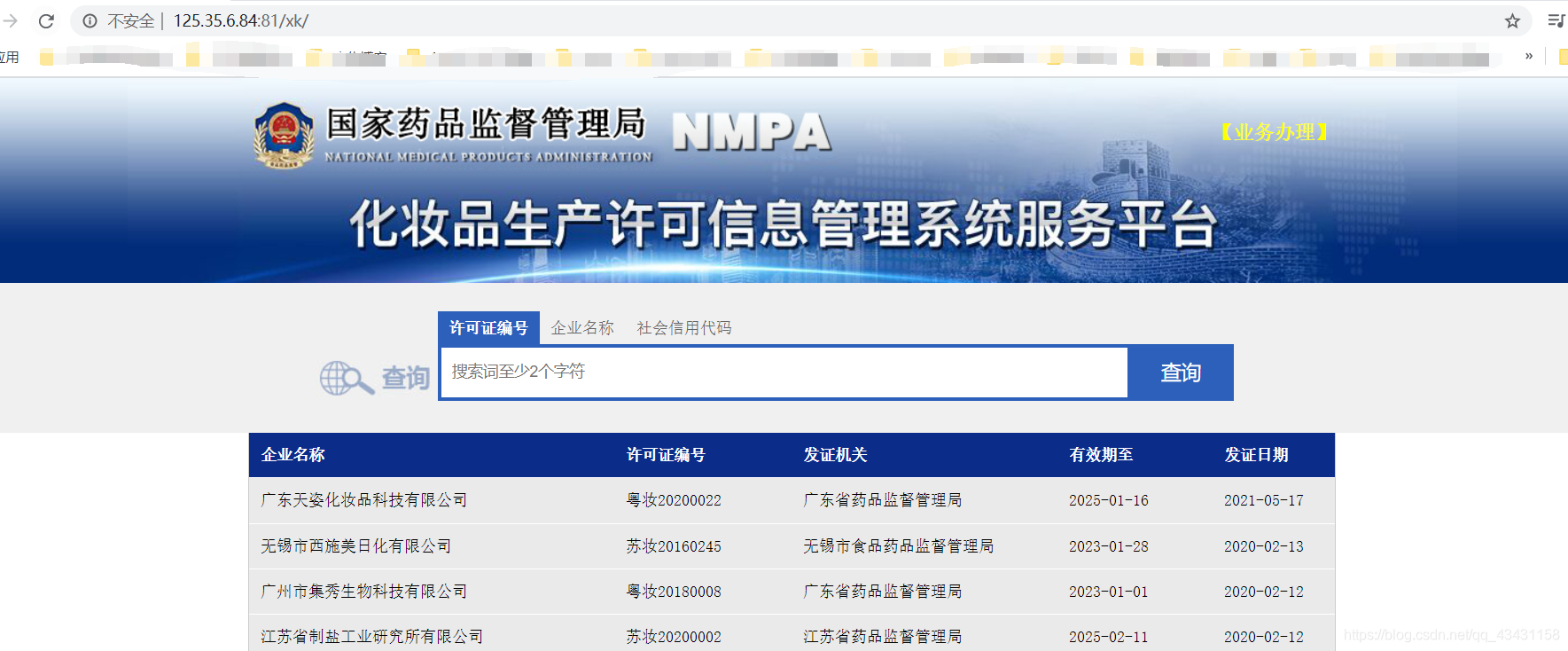
可以F12查看一下也可以写一个py脚本爬取一下
捕获到了该页面的数据,可以查询一下企业名称是否在该数据中即可验证信息是通过何种方式加载的

查询企业名称是没有的,说明该页面的信息数据是通过动态加载出来即(Ajax)

那我们就捕获一下Ajax请求
 果然是动态加载出来的
果然是动态加载出来的
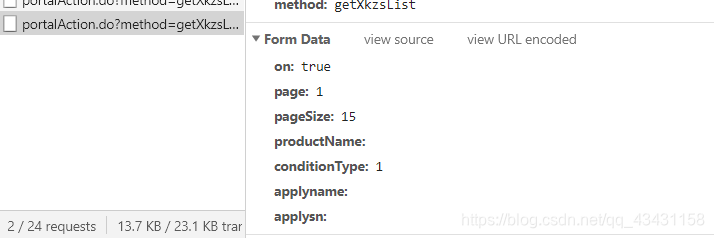
可以看到参数等,这里就先总结一下查到的信息
#页面信息通过动态加载出来
Request URL: http://125.35.6.84:81/xk/itownet/portalAction.do?method=getXkzsList
Request Method: POST
Content-Type: application/json;charset=UTF-8
既然这个页面信息我们已经分析好了,那接下来就看公司的具体许可信息,随便点进去一个,看到有如下信息
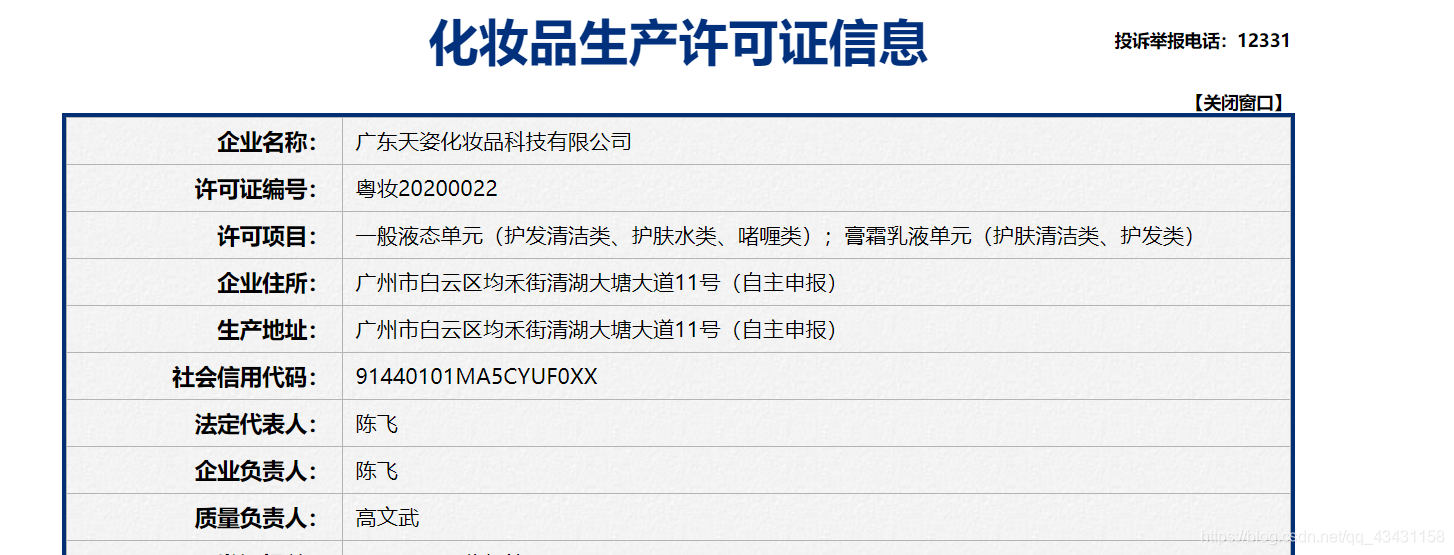
这里还需要进行分析一下,信息是通过该链接直接呈现出来了还是通过动态加载出来的,方法和刚才分析首页一样,我这里就直接查看Ajax请求,发现确实有

查看一下,参数只有id一个

多试几个企业便会发现这个url是不变的,唯一变的便是参数id

到这里为止,再统计一下该页面查到的信息
#信息也是通过动态加载出来的
Request URL: http://125.35.6.84:81/xk/itownet/portalAction.do?method=getXkzsById
Request Method: POST
Content-Type: application/json;charset=UTF-8
分析过后,就来写出爬取代码
0x02:进行爬取
先将首页的json串格式化一下,便于观看

格式化后,发现是一个字典,llist是一个列表,列表中又包含字典,便可以遍历value值,从而可以得到ID值
这个时候我们收集的信息就要用到了
import requests
if __name__ == '__main__':
#首页url,用于获取企业ID号
url = 'http://125.35.6.84:81/xk/itownet/portalAction.do?method=getXkzsList'
#UA伪装
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36'
}
#导入参数
data = {
'on': 'true',
'page': '1',
'pageSize': '15',
'productName':'',
'conditionType': '1',
'applyname':'',
'applysn':'',
}
#建立一个空列表永远存储ID值
id_message = []
#发起请求
message = requests.post(url=url,data=data,headers=headers).json()
#数据是一个字典,而list的value值中包含ID值,所以需要从value值中取出ID值
for dict in message['list']:
id_message.append(dict['ID'])
print(id_message)
爬取后就会发现这样就可以得到这一页所有企业的ID

那么ID拿到了,企业的具体许可信息便可以通过ID的来展示出来
import requests
import json
if __name__ == '__main__':
url = 'http://125.35.6.84:81/xk/itownet/portalAction.do?method=getXkzsList'
#UA伪装
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36'
}
#导入参数
data = {
'on': 'true',
'page': '1',
'pageSize': '15',
'productName':'',
'conditionType': '1',
'applyname':'',
'applysn':'',
}
#建立一个空列表永远存储ID值
id_message = []
#建立一个存储企业详细信息的列表
all_date = []
#发起请求
message = requests.post(url=url,data=data,headers=headers).json()
#数据是一个字典,而list的value值中包含ID值,所以需要从value值中取出ID值
for dict in message['list']:
id_message.append(dict['ID'])
#根据ID号获得企业的详细数据
date_url = 'http://125.35.6.84:81/xk/itownet/portalAction.do?method=getXkzsById'
#遍历ID列表
for id in id_message:
datas = {
'id': id
}
detail_message = requests.post(url=date_url,data=datas,headers=headers).json()
# print(detail_message)
#列表中存储
all_date.append(detail_message)
#存储到本地
fp = open('message.txt','w',encoding='utf-8')
json.dump(all_date,fp=fp,ensure_ascii=False,indent=4)
print("爬取成功咯")
这样就爬取成功了,如果想要爬取更多页面也不麻烦只需将'page': '1'这个参数设置为动态即可
0x03:最终代码
import requests
import json
if __name__ == '__main__':
url = 'http://125.35.6.84:81/xk/itownet/portalAction.do?method=getXkzsList'
#UA伪装
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36'
}
# 建立一个空列表永远存储ID值
id_message = []
# 建立一个存储企业详细信息的列表
all_date = []
#查询多页数据,添加一个循环即可
for page in range(1,3):
#转换为字符类型
page = str(page)
#导入参数
data = {
'on': 'true',
'page': page,
'pageSize': '15',
'productName':'',
'conditionType': '1',
'applyname':'',
'applysn':'',
}
#发起请求
message = requests.post(url=url,data=data,headers=headers).json()
#数据是一个字典,而list的value值中包含ID值,所以需要从value值中取出ID值
for dict in message['list']:
id_message.append(dict['ID'])
#根据ID号获得企业的详细数据
date_url = 'http://125.35.6.84:81/xk/itownet/portalAction.do?method=getXkzsById'
#遍历ID列表
for id in id_message:
datas = {
'id': id
}
detail_message = requests.post(url=date_url,data=datas,headers=headers).json()
# print(detail_message)
#列表中存储
all_date.append(detail_message)
#存储到本地
fp = open('message.txt','w',encoding='utf-8')
json.dump(all_date,fp=fp,ensure_ascii=False,indent=4)
print("爬取成功咯")
爬取的信息

总结:
这次通过案例的训练,掌握了分析方法,接下来学习数据解析!
继续加油,向着优秀的方向前进!!
