目录
一.Scarpy项目的目录结构
使用Scrapy创建爬虫项目后,默认会有如下的目录结构:
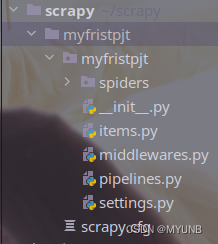
我们创建的项目文件叫myfristpjt,咱们先不谈文件名拼错,先看在这个目录文件下有一个和这个一样的同名文件夹 和一个scrapy.cfg文件,同名文件夹下放的是爬虫项目的核心代码,而scrapy.cfg文件主要是放置爬虫项目的配置文件。同名文件myfristpjt下放置了爬虫项目的核心代码,包括了一个spiders文件,以及_init_.py,itmes.py,pipelines.py,settings等文件,下面我们谈谈这些文件:
(1)_init_.py文件为项目的初始文件,主要写的是项目的一些初始信息
(2)items.py文件为爬虫项目的数据容器文件,主要用来定义我们要获取的数据
(3)piplines.py文件为爬虫项目的管道文件,主要用来对items里的数据进行进一步的加工与处理
(4)setting.py文件为爬虫项目的设置文件,主要是爬虫的一些设置信息
(5)middlewares.py文件放置的是一些中间件的信息
二.Scrapy常用令
Scrapy命令分为两种,一种是全局命令,一种是项目命令,全局命令不需要依靠Scrapy项目就可以使用,而项目命令要在Scrapy目录下才可以使用。
1.全局命令
常见的全局命令有fetch,runspider,settings,shell,startproject,version,view。接下来我们看看这些命令
1.1 fetch命令
fetch主要用来显示爬虫过程爬取的过程,比如我们使用scrapy fetch http://www.baidu.com来显示爬取百度网页的爬取过程,如下:
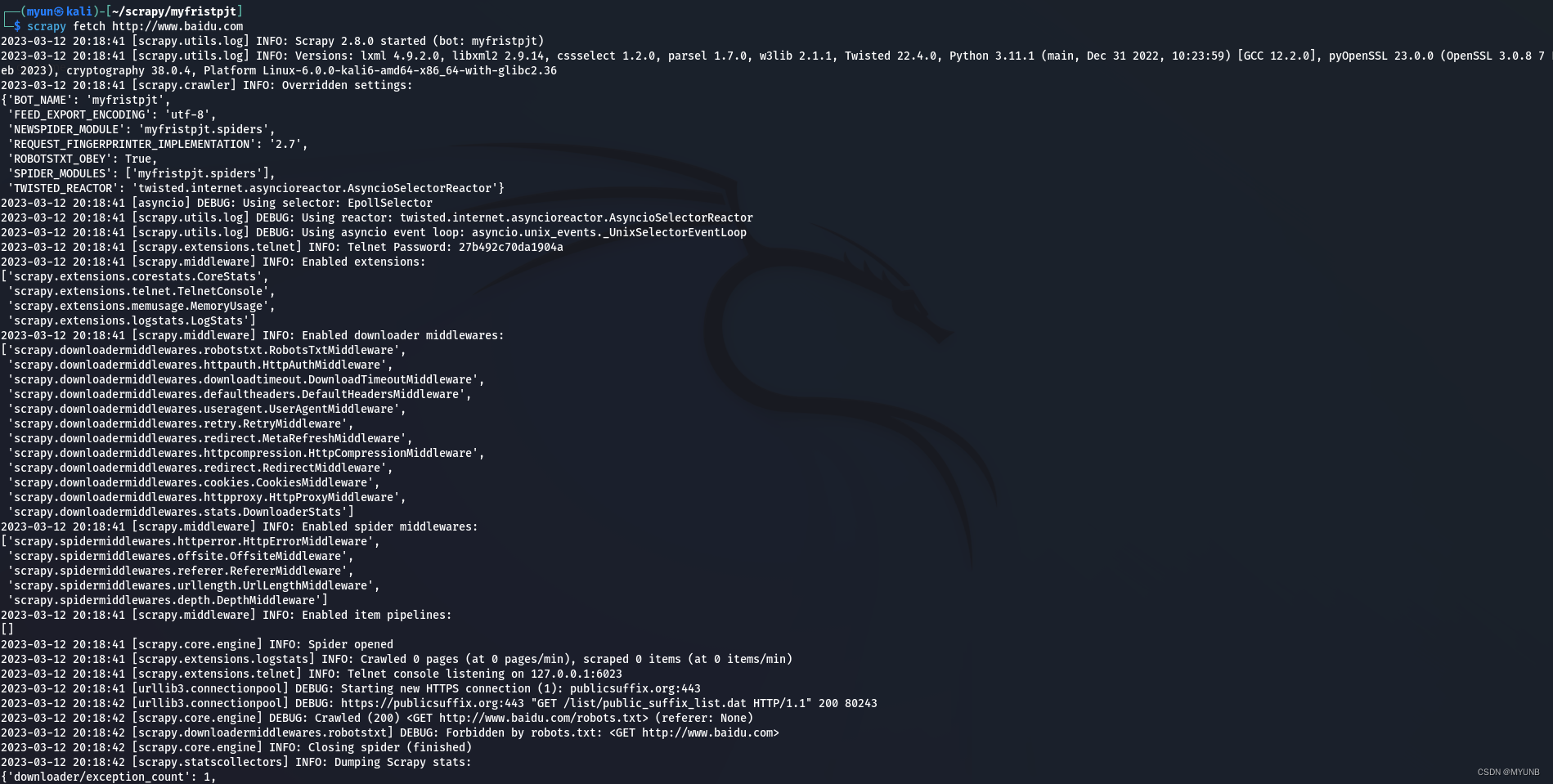
注意,如果在Scrapy项目目录之外使用该命令,则会调用Scrapy默认的爬虫来进行网页爬取,如果在Scrapy每个项目目录中使用该命令,则会调用该项目中的爬虫来进行页面的爬取
1.2 runspider命令
通过Scrapy中的runspider命令我们可以实现不依托Scrapy的爬虫项目,直接运行一个爬虫文件
1.3 settings命令
通过settings命令,可以查看Scrapy对应的配置信息,如果在Scrapy项目下使用settings命令。查看的是对应项目的配置信息,如果在Scrapy项目目录外使用者查看的是Scrapy默认的配置信息
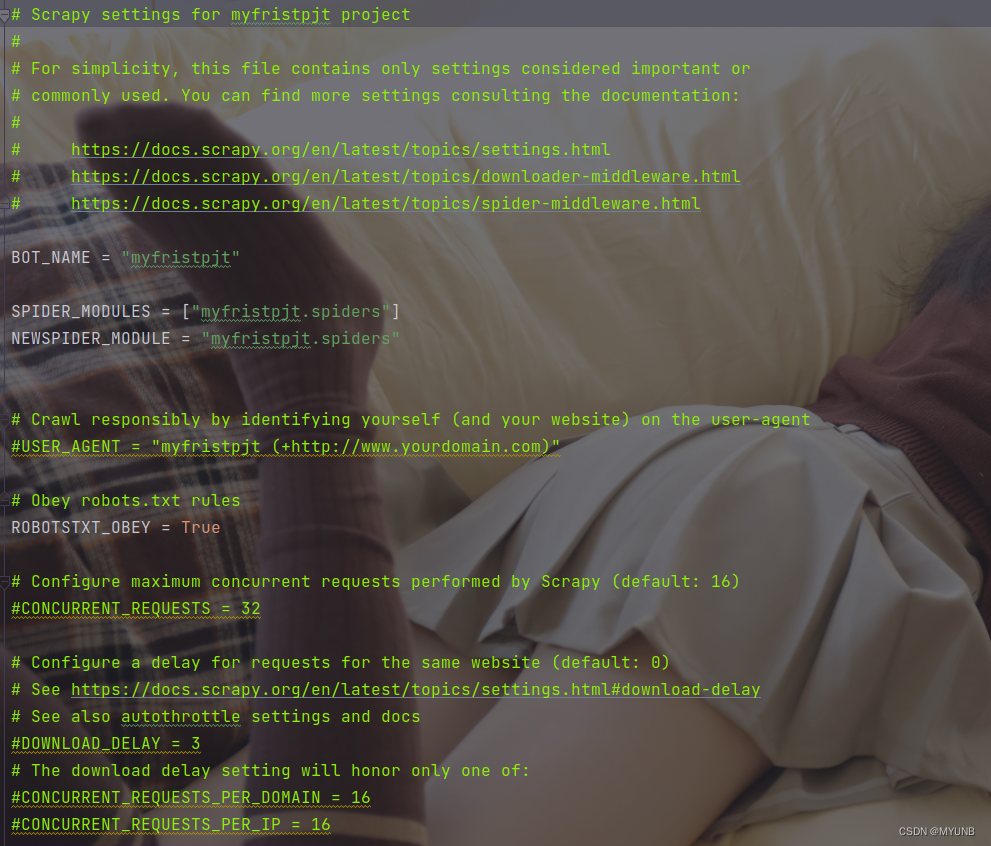
当我们打开目录中的settings.py文件,会看到如下的部分信息,只是爬虫项目的配置信息,当我们在这个爬虫项目下使用settings命令就可以查看该项目的配置信息了
比如我们可以适用scrapy settings --get BOT_NAME来查看配置信息BOT_NAME中对应的值:

显示的结果和settings.py中的配置信息一样
当我们不在爬虫项目下使用命令时,可以看到Scrapy默认的BOT_NAME为scrapybot,如果想查看其他配置信息,只要将settings命令后的参数换成想查看的配置信息即可

1.4 shell命令
通过shell命令可以启动Scrapy的交互终端,使用Scrapy的交互终端可以实现在不启动Scrapy爬虫的情况下对网站响应进行测试或对python代码进行测试
例如:使用shell命令为爬取京东页面常见一个交互终端,并设置不输出日志:
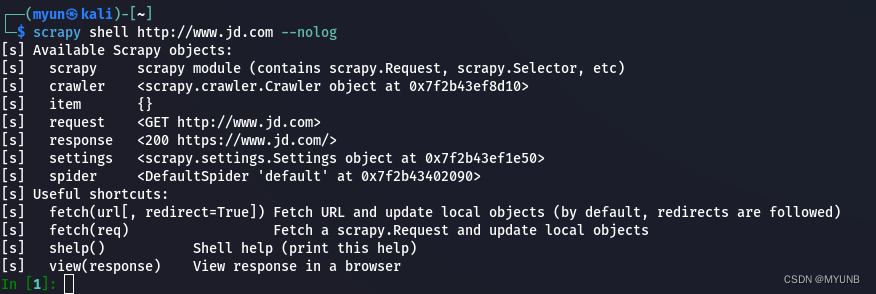
在执行命令后会出现我们可以使用的Scrapy对象即快捷命令,在IN[1]:可以输入交互命令或代码,但想退出交互终端时,可以输入exit()退出
1.5 startproject命令
startproject命令用来常见爬虫项目,命令格式:scrapy startproject 项目名,当执行命令后就会创建爬虫项目,包含了上面我们谈到的文件目录
1.6 version命令
通过version我们可以查看Scrapy的版本命令,如下是我的版本信息:

1.7 view命令
通过view命令,我们可以实现下载某个网页并用浏览器打开的功能,例如我们通过命令下载并打开下载的CSDN网页,注意我们打开的是下载到本地的页面,不在实际页面
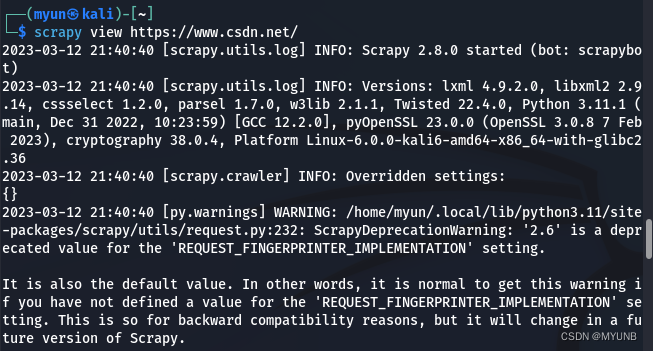
页面已在浏览器中打开
2.项目命令
上面我们已经介绍了常用的全局命令,这里我们介绍一些项目命令,项目命令只能在爬虫项目下使用,在使用项目命令时,我们要进入爬虫项目目录下,Scrapy的项目命令主要有:bench,check,crawl,edit,genspider,list,parse
2.1 Bench命令
适用bench命令可以测试本地的硬件的性能。当我们运行scrapy bench时,会创建一个本地服务器并且以最大的速度爬行来测试本地硬件的性能 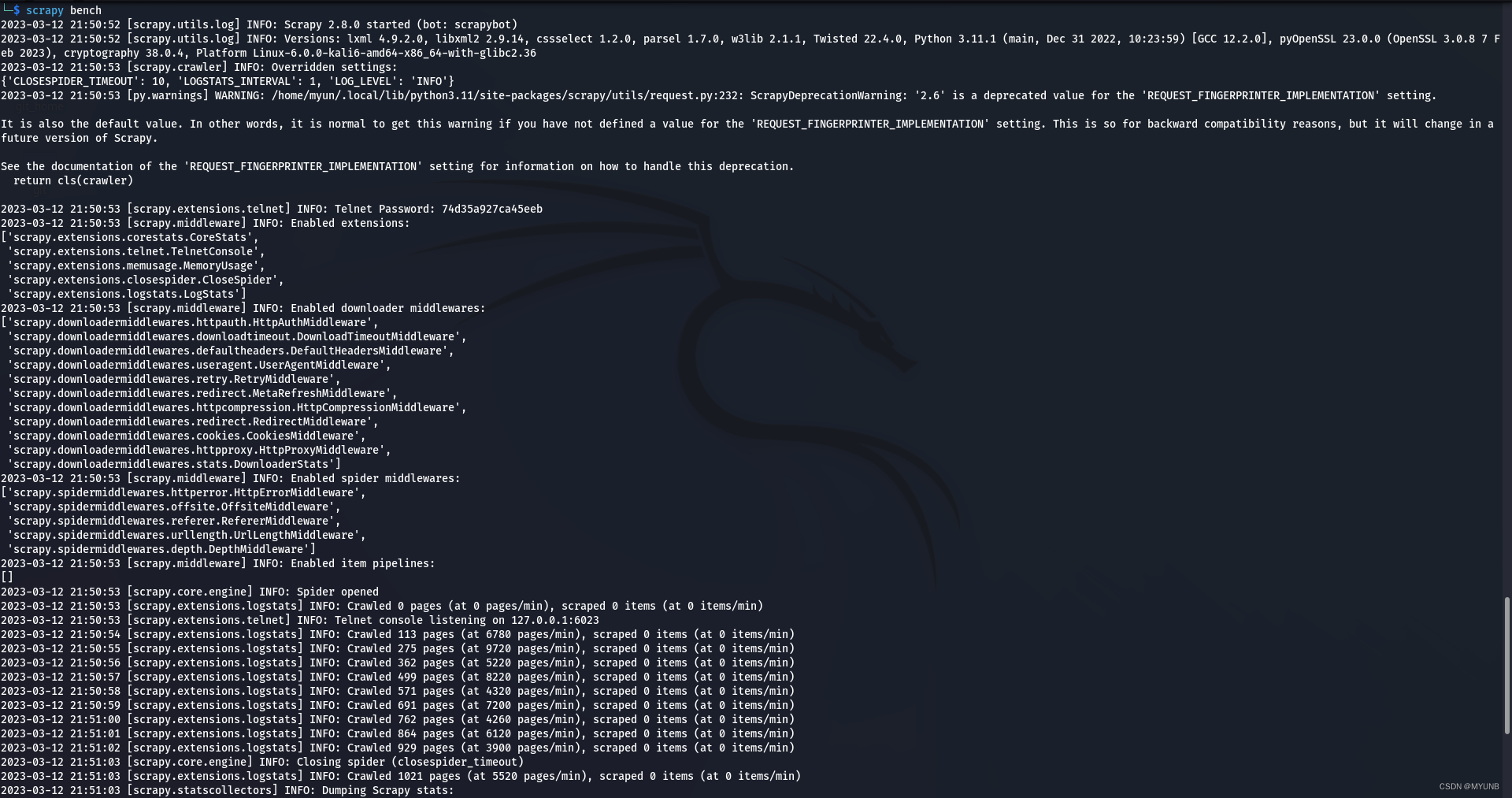 我的硬件性能大约可以下载5520个页面,但时间性能还会因为各种因素有影响
我的硬件性能大约可以下载5520个页面,但时间性能还会因为各种因素有影响
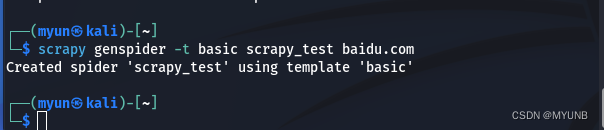
2.2 Genspider命令
genspider命令是创建Scrapy爬虫文件的命令,使用该命令可以基于其中任意的爬虫模板直接生成一个新的爬虫文件
可以使用命令的-l参数查看当前可以使用的爬虫模板:

但我们使用-t参数时可以基于任意一个爬虫模板创建一个爬虫文件,格式为:scrapy genspider -t 模板名 新爬虫名 新爬虫爬取的域名
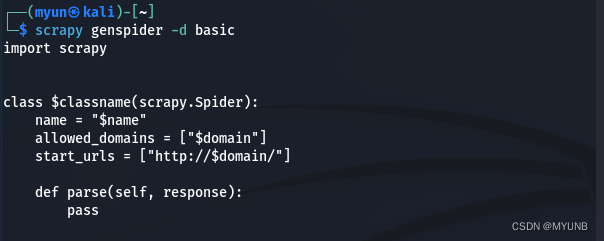
同时,我们也可以使用-d参数查看爬虫模板的内容,例如我们查看basic模块的内容
2.3 Check命令
在Scrapy中使用合同的方式对爬虫进行测试,在Scrapy中使用check命令,可以对某个爬虫文件进行合同检查,比如我们要对某个爬虫文件进行检查,可以使用scrapy check 爬虫名 进行检查
2.4 Crawl命令
通过crawl命令可以启动某个爬虫,启动格式为scrapy crawl 爬虫名
2.5 Edit命令
edit命令用于对爬虫文件进行编辑
2.6 Parse命令
parse命令可以实现获取指定的URL网址,并使用对应的爬虫文件进行处理和分析
三.Item实战编写
在Scrapy中Item对象用来保存爬取到的数据。互联网网页中的信息庞大,基本上都是非结构化的,这样的信息不利于我们管理,所以,我们可以定义我们需要的结构化信息,然后再从互联网中提取我们想要的信息,这些提取的信息就可以保存这写结构化的Item对象中
但我们打开Item.py文件,里面内容如下:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class MyfristpjtItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
可以看到这个文件中在导入了scrapy库后,定义了一个类,这个类用来存放我们想存放的结构化数据,对结构化信息的定义格式为:name=scrapy.Field()。例如,如果我们想对数据网页标题,网页关键词,网页版权信息,网页地址等进行定义,可以讲这个类的代码修改为:
class MyfristscarpyItem(scrapy.item):
#define the fields for your item here like:
#name=scrapy.Field()
urlname=scrapy.Field()
urlkey=scrapy.Field()
urlcr=scrapy.Field()
urladder=scrapy.Field()
如上,我们定义了一个保护网页几个要爬取数据的结构化数据,如果我们想知道爬取后的信息,就只要实例化这个类,然后通过.key()提取数据,也可以用.items()提取键和值
四.Spider实战编程
Spider类是Scrapy中和爬虫相关的一个类,所有的爬虫文件必须继承该类。而该类也挺重要的,爬虫进行的动作以及数据的爬取等操作都在该类中进行定义和编写。例如,通过genspider命令创建一个名为爬虫文件,然后进行相应的编写和操作,打开创建的文件内容如下:
import scrapy
class WeisuenSpider(scrapy.Spider):
name = "weisuen"
allowed_domains = ["iqianyue.com"]
start_urls = ["http://iqianyue.com/"]
def parse(self, response):
pass文件先导入了scrapy模块,如果定义了WeisuenSpider的类,该类继承了scrapy.Spider类。其中,name熟悉表示爬虫的名称,allowed_domains属性代表允许爬虫的域名,如果启动OffsiteMiddleware,非允许的域名对于的网页则会自动过滤掉,start_urls属性代表爬行的起始网页,如果没有定义指定的网页则会从该属性中定义的网页开始爬行,在这个属性中,我们可以定义多个网站,用逗号隔开。这里的parse方法如果没有特意指定回调函数,该方法是处理Scrapy爬虫爬行的网页响应的默认方法,通过该方法可以对响应进行处理并返回处理后的数据,同时负责链接的跟进
除了这些方法和属性外,spider还有一些常用的方法:
| 名称 | 方法 | 含义 |
| start_requests() | 方法 | 该方法会默认读取start_url属性中的网址,然后为每一个网址生成一个Request请求对象,并返回可迭代对象 |
| make_requests_from_url(url) | 方法 | 该方法会被start_requests()调用,该方法负责实现生成Request请求对象 |
| closed(reason) | 方法 | 关闭Spider时,该方法会被调用 |
| log(message[,level,component]) | 方法 | 使用该方法可以实现在Spider添加log |
| __init__() | 方法 | 该方法是构造函数,负责爬虫的初始化 |
如果我们将爬虫文件weisuen.py进行相应的修改,如下:
import scrapy
from lxml import html
from myfristscrapy.items import MyfristscrapyItem
class WeisuenSpider(scrapy.Spider):
name = "weisuen"
allowed_domains = ["sina.com.cn"]
start_urls = ['https://video.sina.cn/mil/2023-03-12/detail-imykrhzx5935579.d.html',
'https://finance.sina.com.cn/tech/csj/2023-03-14/doc-imykutuc6717695.shtml',
]
def parse(self, response):
item=MyfristscrapyItem()
item['urlname']=response.xpath("/html/head/title/text()")
print(item['urlname'])运行后爬取页面标题