任务:
探索性数据分析(EDA). 挑战目标: 这些裁判在给红牌的时候咋想的呢,会不会被跟球员的肤色有关?
%matplotlib inline
%config InlineBackend.figure_format='retina'
from __future__ import absolute_import, division, print_function
import matplotlib as mpl
from matplotlib import pyplot as plt
from matplotlib.pyplot import GridSpec
import seaborn as sns
import numpy as np
import pandas as pd
import os, sys
from tqdm import tqdm
import warnings
warnings.filterwarnings('ignore')
sns.set_context("poster", font_scale=1.3)
import missingno as msno
import pandas_profiling
from sklearn.datasets import make_blobs
import time
数据简介:
数据包含球员和裁判的信息,2012-2013年的比赛数据,总共设计球员2053名,裁判3147名,特征列表如下:
https://docs.google.com/document/d/1uCF5wmbcL90qvrk_J27fWAvDcDNrO9o_APkicwRkOKc/edit
| Variable Name: | Variable Description: |
|---|---|
| playerShort | short player ID |
| player | player name |
| club | player club |
| leagueCountry | country of player club (England, Germany, France, and Spain) |
| height | player height (in cm) |
| weight | player weight (in kg) |
| position | player position |
| games | number of games in the player-referee dyad |
| goals | number of goals in the player-referee dyad |
| yellowCards | number of yellow cards player received from the referee |
| yellowReds | number of yellow-red cards player received from the referee |
| redCards | number of red cards player received from the referee |
| photoID | ID of player photo (if available) |
| rater1 | skin rating of photo by rater 1 |
| rater2 | skin rating of photo by rater 2 |
| refNum | unique referee ID number (referee name removed for anonymizing purposes) |
| refCountry | unique referee country ID number |
| meanIAT | mean implicit bias score (using the race IAT) for referee country |
| nIAT | sample size for race IAT in that particular country |
| seIAT | standard error for mean estimate of race IAT |
| meanExp | mean explicit bias score (using a racial thermometer task) for referee country |
| nExp | sample size for explicit bias in that particular country |
| seExp | standard error for mean estimate of explicit bias measure |
df = pd.read_csv("redcard.csv.gz", compression='gzip')
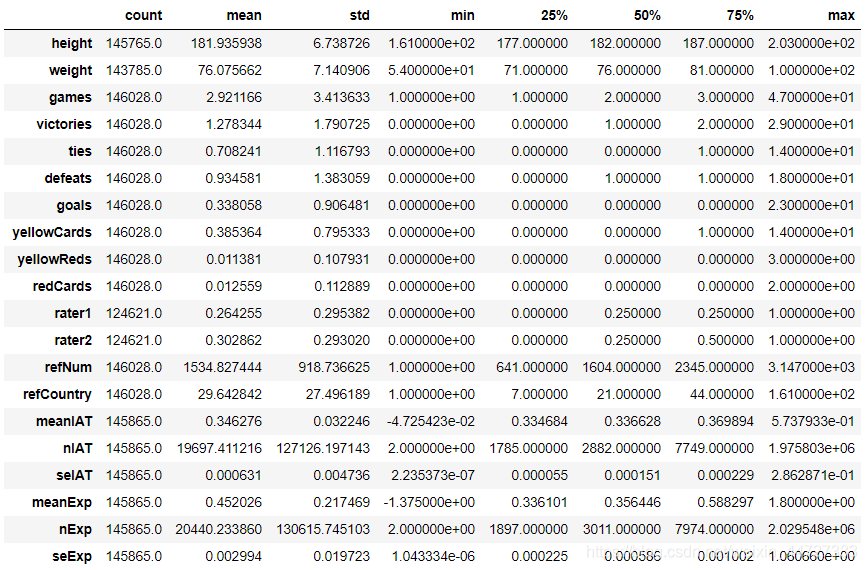
df.describe().T
all_columns = df.columns.tolist()
Create Tidy Players Table
player_index = 'playerShort'
player_cols = [#'player', # drop player name, we have unique identifier
'birthday',
'height',
'weight',
'position',
'photoID',
'rater1',
'rater2',
]
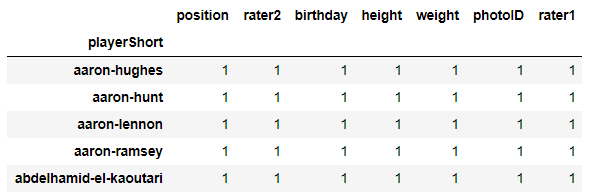
all_cols_unique_players = df.groupby('playerShort').agg({col:'nunique' for col in player_cols})
all_cols_unique_players.head()
all_cols_unique_players[all_cols_unique_players > 1].dropna().shape[0] == 0
def get_subgroup(dataframe, g_index, g_columns):
"""Helper function that creates a sub-table from the columns and runs a quick uniqueness test."""
g = dataframe.groupby(g_index).agg({col:'nunique' for col in g_columns})
if g[g > 1].dropna().shape[0] != 0:
print("Warning: you probably assumed this had all unique values but it doesn't.")
return dataframe.groupby(g_index).agg({col:'max' for col in g_columns})
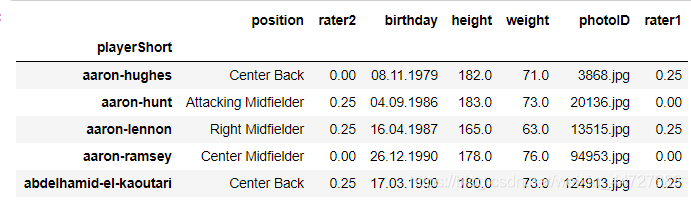
players = get_subgroup(df, player_index, player_cols)
players.head()
def save_subgroup(dataframe, g_index, subgroup_name, prefix='raw_'):
save_subgroup_filename = "".join([prefix, subgroup_name, ".csv.gz"])
dataframe.to_csv(save_subgroup_filename, compression='gzip', encoding='UTF-8')
test_df = pd.read_csv(save_subgroup_filename, compression='gzip', index_col=g_index, encoding='UTF-8')
# Test that we recover what we send in
if dataframe.equals(test_df):
print("Test-passed: we recover the equivalent subgroup dataframe.")
else:
print("Warning -- equivalence test!!! Double-check.")
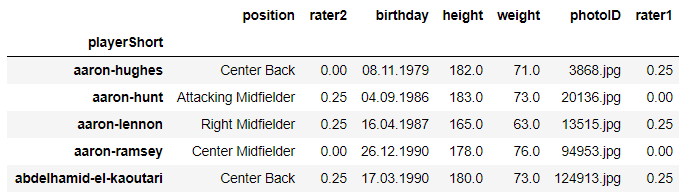
players = get_subgroup(df, player_index, player_cols)
players.head()
save_subgroup(players, player_index, "players")
Create Tidy Clubs Table
club_index = 'club'
club_cols = ['leagueCountry']
clubs = get_subgroup(df, club_index, club_cols)
clubs.head()
clubs['leagueCountry'].value_counts()
England 48
Spain 27
France 22
Germany 21
Name: leagueCountry, dtype: int64
save_subgroup(clubs, club_index, "clubs", )
Create Tidy Referees Table
referee_index = 'refNum'
referee_cols = ['refCountry']
referees = get_subgroup(df, referee_index, referee_cols)
referees.head()

save_subgroup(referees, referee_index, "referees")
Create Tidy Countries Table
country_index = 'refCountry'
country_cols = ['Alpha_3', # rename this name of country
'meanIAT',
'nIAT',
'seIAT',
'meanExp',
'nExp',
'seExp',
]
countries = get_subgroup(df, country_index, country_cols)
countries.head()
rename_columns = {'Alpha_3':'countryName', }
countries = countries.rename(columns=rename_columns)
countries.head()
save_subgroup(countries, country_index, "countries")
Create separate (not yet Tidy) Dyads Table
dyad_index = ['refNum', 'playerShort']
dyad_cols = ['games',
'victories',
'ties',
'defeats',
'goals',
'yellowCards',
'yellowReds',
'redCards',
]
dyads = get_subgroup(df, g_index=dyad_index, g_columns=dyad_cols)
save_subgroup(dyads, dyad_index, "dyads")
