布林带
布林带由三条线组成:
中轨:移动平均线
上轨:中轨+2x5日收盘价标准差 (顶部的压力)
下轨:中轨-2x5日收盘价标准差 (底部的支撑力)
布林带收窄代表稳定的趋势,布林带张开代表有较大的波动空间的趋势。
绘制5日均线的布林带
weights = np.exp(np.linspace(-1, 0, 5))
weights /= weights.sum()
em5 = np.convolve(closing_prices, weights[::-1], 'valid')
stds = np.zeros(em5.size)
for i in range(stds.size):
stds[i] = closing_prices[i:i + 5].std()
stds *= 2
lowers = medios - stds
uppers = medios + stds
mp.plot(dates, closing_prices, c='lightgray', label='Closing Price')
mp.plot(dates[4:], medios, c='dodgerblue', label='Medio')
mp.plot(dates[4:], lowers, c='limegreen', label='Lower')
mp.plot(dates[4:], uppers, c='orangered', label='Upper')
线性模型
什么是线性关系?
1 2 3 4 5
60 65 70 75 ?
线性预测
假设一组数据符合一种线型规律,那么就可以预测未来将会出现的数据。
a b c d e f ?
ax + by + cz = d
bx + cy + dz = e
cx + dy + ez = f
a b c d e f g ?
x = np.linalg.lstsq(A, B)[0]
根据线性模型的特点可以通过一组历史数据求出线性关系系数x, y, z,从而预测d、e、f下的一个数据是多少。
线性预测需要使用历史数据进行检验,让预测结果可信度更高
案例:使用线性预测,预测下一天的收盘价。
# 整理五元一次方程组 最终获取一组股票走势预测值
N = 5
pred_prices = np.zeros(closing_prices.size - 2 * N + 1)
for i in range(pred_prices.size):
a = np.zeros((N, N))
for j in range(N):
a[j, ] = closing_prices[i + j:i + j + N]
b = closing_prices[i + N:i + N * 2]
x = np.linalg.lstsq(a, b)[0]
pred_prices[i] = b.dot(x)
# 由于预测的是下一天的收盘价,所以想日期数组中追加一个元素,为下一个工作日的日期
dates = dates.astype(md.datetime.datetime)
mp.plot(dates, closing_prices, 'o-', c='lightgray', label='Closing Price')
dates = np.append(dates, dates[-1] + pd.tseries.offsets.BDay())
mp.plot(dates[2 * N:], pred_prices, 'o-',c='orangered',
linewidth=3,label='Predicted Price')
mp.legend()
mp.gcf().autofmt_xdate()
mp.show()
线性拟合
线性拟合可以寻求与一组散点走向趋势规律相适应的线型表达式方程。
有一组散点描述时间序列下的股价:
[x1, y1], [x2, y2], [x3, y3],
...
[xn, yn]
根据线型 y=kx + b 方程可得:
kx1 + b = y1
kx2 + b = y2
kx3 + b = y3
...
kxn + b = yn
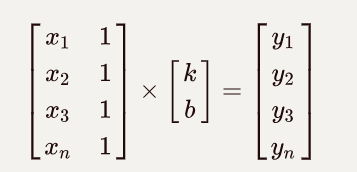
样本过多,每两组方程即可求得一组k与b的值。np.linalg.lstsq(a, b) 可以通过最小二乘法求出所有结果中拟合误差最小的k与b的值。
案例:利用线型拟合画出股价的趋势线
- 绘制趋势线(趋势可以表示为最高价、最低价、收盘价的均值):
dates, opening_prices, highest_prices, \
lowest_prices, closing_prices = np.loadtxt('../data/aapl.csv', delimiter=',',
usecols=(1, 3, 4, 5, 6), unpack=True,dtype='M8[D], f8, f8, f8, f8',
converters={1: dmy2ymd})
trend_points = (highest_prices + lowest_prices + closing_prices) / 3
days = dates.astype(int)
a = np.column_stack((days, np.ones_like(days)))
x = np.linalg.lstsq(a, trend_points)[0]
trend_line = days * x[0] + x[1]
mp.figure('Trend', facecolor='lightgray')
mp.title('Trend', fontsize=20)
mp.xlabel('Date', fontsize=14)
mp.ylabel('Price', fontsize=14)
ax = mp.gca()
ax.xaxis.set_major_locator(md.WeekdayLocator(byweekday=md.MO))
ax.xaxis.set_minor_locator(md.DayLocator())
ax.xaxis.set_major_formatter(md.DateFormatter('%d %b %Y'))
mp.tick_params(labelsize=10)
mp.grid(linestyle=':')
dates = dates.astype(md.datetime.datetime)
rise = closing_prices - opening_prices >= 0.01
fall = opening_prices - closing_prices >= 0.01
fc = np.zeros(dates.size, dtype='3f4')
ec = np.zeros(dates.size, dtype='3f4')
fc[rise], fc[fall] = (1, 1, 1), (0.85, 0.85, 0.85)
ec[rise], ec[fall] = (0.85, 0.85, 0.85), (0.85, 0.85, 0.85)
mp.bar(dates, highest_prices - lowest_prices, 0,lowest_prices, color=fc, edgecolor=ec)
mp.bar(dates, closing_prices - opening_prices, 0.8,opening_prices, color=fc,
edgecolor=ec)
mp.scatter(dates, trend_points, c='dodgerblue',alpha=0.5, s=60, zorder=2)
mp.plot(dates, trend_line, linestyle='o-', c='dodgerblue',linewidth=3, label='Trend')
mp.legend()
mp.gcf().autofmt_xdate()
mp.show()
- 绘制顶部压力线(趋势线+(最高价 - 最低价))
trend_points = (highest_prices + lowest_prices + closing_prices) / 3
spreads = highest_prices - lowest_prices
resistance_points = trend_points + spreads
days = dates.astype(int)
x = np.linalg.lstsq(a, resistance_points)[0]
resistance_line = days * x[0] + x[1]
mp.scatter(dates, resistance_points, c='orangered', alpha=0.5, s=60, zorder=2)
mp.plot(dates, resistance_line, c='orangered', linewidth=3, label='Resistance')
- 绘制底部支撑线(趋势线-(最高价 - 最低价))
trend_points = (highest_prices + lowest_prices + closing_prices) / 3
spreads = highest_prices - lowest_prices
support_points = trend_points - spreads
days = dates.astype(int)
x = np.linalg.lstsq(a, support_points)[0]
support_line = days * x[0] + x[1]
mp.scatter(dates, support_points, c='limegreen', alpha=0.5, s=60, zorder=2)
mp.plot(dates, support_line, c='limegreen', linewidth=3, label='Support')
协方差、相关矩阵、相关系数
通过两组统计数据计算而得的协方差可以评估这两组统计数据的相似程度。
样本:
A = [a1, a2, ..., an]
B = [b1, b2, ..., bn]
平均值:
ave_a = (a1 + a2 +...+ an)/n
ave_b = (b1 + b2 +...+ bn)/n
离差(用样本中的每一个元素减去平均数,求得数据的误差程度):
dev_a = [a1, a2, ..., an] - ave_a
dev_b = [b1, b2, ..., bn] - ave_b
协方差
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-npUt2Hl3-1585032595278)(C:\Users\dell\AppData\Roaming\Typora\typora-user-images\1578208037758.png)]
协方差可以简单反映两组统计样本的相关性,值为正,则为正相关;值为负,则为负相关,绝对值越大相关性越强。
cov_ab = ave(dev_a x dev_b)
cov_ba = ave(dev_b x dev_a)
案例:计算两组数据的协方差,并绘图观察。
import numpy as np
import matplotlib.pyplot as mp
a = np.random.randint(1, 30, 10)
b = np.random.randint(1, 30, 10)
#平均值
ave_a = np.mean(a)
ave_b = np.mean(b)
#离差
dev_a = a - ave_a
dev_b = b - ave_b
#协方差
cov_ab = np.mean(dev_a*dev_b)
cov_ba = np.mean(dev_b*dev_a)
print('a与b数组:', a, b)
print('a与b样本方差:', np.sum(dev_a**2)/(len(dev_a)-1), np.sum(dev_b**2)/(len(dev_b)-1))
print('a与b协方差:',cov_ab, cov_ba)
a与b数组: [25 2 27 15 7 27 24 8 14 23]
[ 7 19 16 9 5 3 18 29 5 14]
a与b样本方差: 75.76 59.45
a与b的协方差: -19.8 -19.8
#绘图,查看两条图线的相关性
mp.figure('COV LINES', facecolor='lightgray')
mp.title('COV LINES', fontsize=16)
mp.xlabel('x', fontsize=14)
mp.ylabel('y', fontsize=14)
x = np.arange(0, 10)
#a,b两条线
mp.plot(x, a, color='dodgerblue', label='Line1')
mp.plot(x, b, color='limegreen', label='Line2')
#a,b两条线的平均线
mp.plot([0, 9], [ave_a, ave_a], color='dodgerblue', linestyle='--', alpha=0.7, linewidth=3)
mp.plot([0, 9], [ave_b, ave_b], color='limegreen', linestyle='--', alpha=0.7, linewidth=3)
mp.grid(linestyle='--', alpha=0.5)
mp.legend()
mp.tight_layout()
mp.show()
相关系数
协方差除去两组统计样本标准差的乘积是一个[-1, 1]之间的数。该结果称为统计样本的相关系数。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Fdb5kE1q-1585032595280)(C:\Users\dell\AppData\Roaming\Typora\typora-user-images\1578208131565.png)]
# a组样本 与 b组样本做对照后的相关系数
cov_ab/(std_a x std_b)
# b组样本 与 a组样本做对照后的相关系数
cov_ba/(std_b x std_a)
# a样本与a样本作对照 b样本与b样本做对照 二者必然相等
cov_ab/(std_a x std_b)=cov_ba/(std_b x std_a)
通过相关系数可以分析两组数据的相关性:
若相关系数越接近于0,越表示两组样本越不相关。
若相关系数越接近于1,越表示两组样本正相关。
若相关系数越接近于-1,越表示两组样本负相关。
案例:输出案例中两组数据的相关系数。
print('相关系数:', cov_ab/(np.std(a)*np.std(b)), cov_ba/(np.std(a)*np.std(b)))
相关系数: -0.09374698532593467 -0.09374698532593467
相关矩阵
矩阵正对角线上的值都为1。(同组样本自己相比绝对正相关)
numpy提供了求得相关矩阵的API:
# 相关矩阵
numpy.corrcoef(a, b)
# 相关矩阵的分子矩阵 (协方差矩阵)
# [[a方差,ab协方差], [ba协方差, b方差]]
numpy.cov(a, b)
多项式拟合
多项式的一般形式:
多项式拟合的目的是为了找到一组p0-pn,使得拟合方程尽可能的与实际样本数据相符合。
假设拟合得到的多项式如下:
则拟合函数与真实结果的差方如下
那么多项式拟合的过程即为求取一组p0-pn,使得loss的值最小。
X = [x1, x2, ..., xn] - 自变量
Y = [y1, y2, ..., yn] - 实际函数值
Y'= [y1',y2',...,yn'] - 拟合函数值
P = [p0, p1, ..., pn] - 多项式函数中的系数
根据一组样本,并给出最高次幂,求出拟合系数
np.polyfit(X, Y, 最高次幂)->P
多项式运算相关API:
根据拟合系数与自变量求出拟合值, 由此可得拟合曲线坐标样本数据 [X, Y']
np.polyval(P, X)->Y'
多项式函数求导,根据拟合系数求出多项式函数导函数的系数
np.polyder(P)->Q
已知多项式系数Q 求多项式函数的根(与x轴交点的横坐标)
xs = np.roots(Q)
两个多项式函数的差函数的系数(可以通过差函数的根求取两个曲线的交点)
Q = np.polysub(P1, P2)
案例:求多项式 y = 4x3 + 3x2 - 1000x + 1曲线驻点的坐标。
'''
1. 求出多项式的导函数
2. 求出导函数的根,若导函数的根为实数,则该点则为曲线拐点。
'''
import numpy as np
import matplotlib.pyplot as mp
x = np.linspace(-20, 20, 1000)
y = 4*x**3 + 3*x**2 - 1000*x + 1
Q = np.polyder([4,3,-1000,1])
xs = np.roots(Q)
ys = 4*xs**3 + 3*xs**2 - 1000*xs + 1
mp.plot(x, y)
mp.scatter(xs, ys, s=80, c='orangered')
mp.show()
案例:使用多项式函数拟合两只股票bhp、vale的差价函数:
'''
1. 计算两只股票的差价
2. 利用多项式拟合求出与两只股票差价相近的多项式系数,最高次为4
3. 把该曲线的拐点都标出来。
'''
dates, bhp_closing_prices = np.loadtxt('../../data/bhp.csv',
delimiter=',',usecols=(1, 6), unpack=True,
dtype='M8[D], f8', conv erters={1: dmy2ymd})
vale_closing_prices = np.loa dtxt('../../data/vale.csv', delimiter=',',
usecols=(6), unpack=True)
diff_closing_prices = bhp_closing_prices - vale_closing_prices
days = dates.astype(int)
p = np.polyfit(days, diff_closing_prices, 4)
poly_closing_prices = np.polyval(p, days)
q = np.polyder(p)
roots_x = np.roots(q)
roots_y = np.polyval(p, roots_x)
mp.figure('Polynomial Fitting', facecolor='lightgray')
mp.title('Polynomial Fitting', fontsize=20)
mp.xlabel('Date', fontsize=14)
mp.ylabel('Difference Price', fontsize=14)
ax = mp.gca()
ax.xaxis.set_major_locator(md.WeekdayLocator(byweekday=md.MO))
ax.xaxis.set_minor_locator(md.DayLocator())
ax.xaxis.set_major_formatter(md.DateFormatter('%d %b %Y'))
mp.tick_params(labelsize=10)
mp.grid(linestyle=':')
dates = dates.astype(md.datetime.datetime)
mp.plot(dates, poly_closing_prices, c='limegreen',
linewidth=3, label='Polynomial Fitting')
mp.scatter(dates, diff_closing_prices, c='dodgerblue',
alpha=0.5, s=60, label='Difference Price')
roots_x = roots_x.astype(int).astype('M8[D]').astype(
md.datetime.datetime)
mp.scatter(roots_x, roots_y, marker='^', s=80,
c='orangered', label='Peek', zorder=4)
mp.legend()
mp.gcf().autofmt_xdate()
mp.show()
数据平滑
数据的平滑处理通常包含有降噪、拟合等操作。降噪的功能意在去除额外的影响因素,拟合的目的意在数学模型化,可以通过更多的数学方法识别曲线特征。
案例:绘制两只股票收益率曲线。收益率 =(后一天收盘价-前一天收盘价) / 前一天收盘价
- 使用卷积完成数据降噪。
dates, bhp_closing_prices = np.loadtxt( '../data/bhp.csv', delimiter=',', usecols=(1,6), dtype='M8[D], f8',converters={1:dmy2ymd}, unpack=True)
vale_closing_prices = np.loadtxt( '../data/vale.csv', delimiter=',', usecols=(6), dtype='f8',converters={1:dmy2ymd}, unpack=True)
bhp_returns = np.diff(bhp_closing_prices) / bhp_closing_prices[:-1]
vale_returns = np.diff(vale_closing_prices) / vale_closing_prices[:-1]
dates = dates[:-1]
#卷积降噪
convolve_core = np.hanning(8)
convolve_core /= convolve_core.sum()
bhp_returns_convolved = np.convolve(bhp_returns, convolve_core, 'valid')
vale_returns_convolved = np.convolve(vale_returns, convolve_core, 'valid')
#绘制这条曲线
mp.figure('BHP VALE RETURNS', facecolor='lightgray')
mp.title('BHP VALE RETURNS', fontsize=20)
mp.xlabel('Date')
mp.ylabel('Price')
ax = mp.gca()
ax.xaxis.set_major_locator(md.WeekdayLocator(byweekday=md.MO))
ax.xaxis.set_minor_locator(md.DayLocator())
ax.xaxis.set_major_formatter(md.DateFormatter('%Y %m %d'))
dates = dates.astype('M8[D]')
#绘制收益线
mp.plot(dates, bhp_returns, color='dodgerblue', linestyle='--', label='bhp_returns', alpha=0.3)
mp.plot(dates, vale_returns, color='orangered', linestyle='--', label='vale_returns', alpha=0.3)
#绘制卷积降噪线
mp.plot(dates[7:], bhp_returns_convolved, color='dodgerblue', label='bhp_returns_convolved', alpha=0.5)
mp.plot(dates[7:], vale_returns_convolved, color='orangered', label='vale_returns_convolved', alpha=0.5)
mp.show()
- 对处理过的股票收益率做多项式拟合。
#拟合这两条曲线,获取两组多项式系数
dates = dates.astype(int)
bhp_p = np.polyfit(dates[7:], bhp_returns_convolved, 3)
bhp_polyfit_y = np.polyval(bhp_p, dates[7:])
vale_p = np.polyfit(dates[7:], vale_returns_convolved, 3)
vale_polyfit_y = np.polyval(vale_p, dates[7:])
#绘制拟合线
mp.plot(dates[7:], bhp_polyfit_y, color='dodgerblue', label='bhp_returns_polyfit')
mp.plot(dates[7:], vale_polyfit_y, color='orangered', label='vale_returns_polyfit')
- 通过获取两个函数的焦点可以分析两只股票的投资收益比。
#求两条曲线的交点 f(bhp) = f(vale)的根
sub_p = np.polysub(bhp_p, vale_p)
roots_x = np.roots(sub_p) # 让f(bhp) - f(vale) = 0 函数的两个根既是两个函数的焦点
roots_x = roots_x.compress( (dates[0] <= roots_x) & (roots_x <= dates[-1]))
roots_y = np.polyval(bhp_p, roots_x)
#绘制这些点
mp.scatter(roots_x, roots_y, marker='D', color='green', s=60, zorder=3)
