前言
目前使用最广泛的one-shot learning的方法是,先学习一个深度embedding函数,然后再定义一个简单的分类规则,比如在embedding空间中进行最近邻操作。但是,计算embedding和学习适用于新目标的模型还是相去甚远。
本文提出了一种与众不同的方法,仅从一个单一的样本,就能得到一个完整的深度判别模型来识别与该样本属于同一类别的其它目标。而且本文提出的方法并不需要一个冗长的优化过程,而是能够进行实时、高效和一次性的计算。本文的方法就是学习一个深度神经网络,称为learnet,具体来说就是,给定一个新类的样本,预测第二个网络的参数,该网络可以识别属于该新类的其它目标。
本文的模型有以下几个值得关注的地方:
- 如果把学习看作是将一组图像映射到模型参数的过程,那么这可以看作是learning to learn方法。显然,只有在给定充分的先验知识的情况下,才能从一个单一样本中学习。通过处理数百万个one-shot learning任务和端到端的向后传播误差,将这些先验知识在一个off-line阶段整合到learnet中。
- learnet模型提供了一个前馈学习算法,它可以从可用的样本中一次性提取出最终模型的参数,它也证明了深度学习网络能够以元学习的方式预测第二个网络的参数。
- 本文的方法以一种高效、实用的方式来进行one-shot learning
方法实现
由于本文将one-shot learning视为判别任务,因此首先从标准的判别学习开始:在有
个样本
及其对应标签
的数据集上计算一个预测函数:
,需要找到参数矩阵
使得该函数的平均损失
最小:

当从一个类别的单一样本
中学习
时,也就是所谓的one-shot learning,需要将先验知识融入到学习过程中,也就是learning to learn,这是one-shot learning所面对的主要的挑战;除此之外,还要避免如式(1)中冗余的优化过程,这对于one-shot learning的实际应用是非常重要的。
为了解决上面说到的两个问题,本文使用元预测(meta-prediction)过程从单个样本
中学习参数矩阵
,也即用一个无迭代的前馈函数
将
映射到
,称这个函数为learnet,learnet取决于样本
,
就是某个新类中的唯一一个样本,它有一个参数矩阵
。那么learning to learn问题现在就可以被转换成使用目标函数(objective function)来优化learnet的元参数(meta-parameter)
,在这种方式下,larnet前馈网络的速度远大于式(1)中求解优化问题的速度。为了训练learnet,要求能在给定任意样本
的情况下生成良好的预测,最终的结果是在
个样本
上的平均结果:
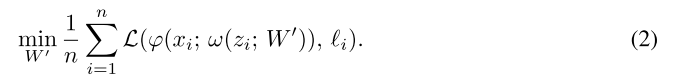
在上式中,用一个验证对儿
来评估learnet从
中提取的预测的性能,训练数据由三元组
构成。在式(1)中
就是
对应的标签,而在这里
还要取决于
:当
和
属于同一类时,
是正样本,否则为负样本,并且式(1)中
的参数现在会根据
的不同发生动态变化。上式就将one-shot learning的优化目标指定为动态参数预测。通过应用chain rule,在反向传播过程中通过
和
来计算导数,可能会比通过其它标准深度网络还要简单一点。
在实现过程中遇到的困难
在实现过程中会发现,输出空间的大小实在是太大了。
为了分析在实现learnet时会遇到哪些困难,接下来会在一个全连接层上进行one-shot预测:

其中输入
,输出
,权重
,偏差
那么现在,用
和
来替代上式中的权重和偏差,它们分别表示在给定输入样本
时learnet
的两个输出:

式(5)虽然看起来只是对线性层的替换,但分析表明它的伸缩性非常差。主要原因在于learnet
的输出空间异常大:
,对于线性层中数量相当的输入和输出单元来说(
约等于
),输出空间会随着单元数量的增加呈平方增长。
这看起来只会发生在大型网络中,但其实只有少量单元的网络中也会出现这样的情况。考虑一个简单的线性learnet ,即使是非常小的全连接层,只有100个单元( ),样本 维数为100,learnet也已经有1000000个参数需要学习了。就算减少样本的维数 ,也只能在参数总数上实现较小的恒定大小缩减。最主要的问题是输出空间 的平方大小,而不是输入空间 的大小。
解决方案
1. 对线性层的因式分解
为了减小输出空间的大小,一种简单的方法是对权重进行因式分解:
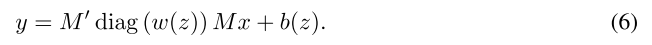
其中
可以看作是权重的因式分解表示,类似于奇异值分解。矩阵
将
投影到另一个空间中,
表示分解的变量;
又将结果映射回当前空间。
和
都包含额外的参数,但与上节讨论的情况相比,它们的大小较小。现在one-shot分支
只需要预测一组对角线元素,因此它的输出空间将随着层中单元数量的增加而线性增长:
2. 对卷积层的因式分解
式(6)的因式分解也可以泛化到卷积层中。给定一个输入张量
,权重
(
是滤波器支持的大小),和偏差
,卷积层的输出
为:

其中
表示卷积操作,偏差
被应用到每个通道中。这里的
和
应该将特征通道分开,允许
选择应用于每个通道的滤波器,因此考虑一下因式分解:
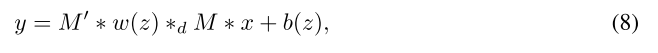
其中
,
,
,下标
表示
个通道的独立滤波,比如,
的每个通道就是
和
中相应通道的卷积。在实际操作中,上式可由在第三和第四维中对角的滤波器张量来实现,或使用
个滤波器组,每组包含一个滤波器。卷积层的因式分解如下图所示:
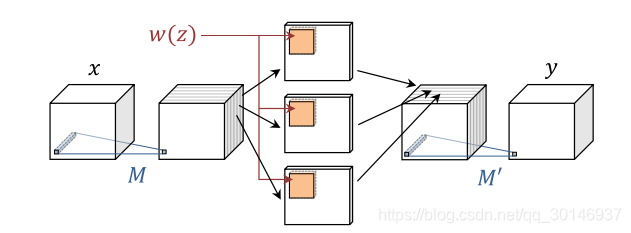
在这种因式分解下,通过one-shot分支
预测的元素数量仅为
,如果没有因式分解,将为
,与全连接层类似,当输入单元近似等于输出单元时,预测的元素的数量并不会呈平方增长,而是线性增长。
网络结构
本文learnet的结构是在孪生网络结构的基础上进行改进。
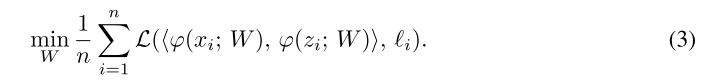
孪生网络(siamese network)包括两个平行流(parallel stream)
和
,它们都包含卷积,池化和ReLU层,并且共享参数
,然后两个流的输出通过层
进行比较,该层计算的是相似性或不相似性的一个度量,如下图所示:
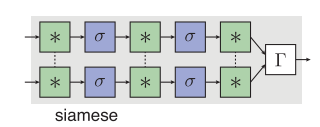
本文特别考虑的是向量
和向量
之间的点积
,欧式距离
,和加权
-norm
,其中
是可学习的权重,
是Hadamard乘积。那么所做的第一个修改就是用learnet来预测两个流共享的一些中间参数。注意孪生网络的参数在两个流中依然是相同的,而learnet是一个新的子网,它的目的是将样本图像映射到共享权重上,这个模型被称为siamese learnet,如下图所示:
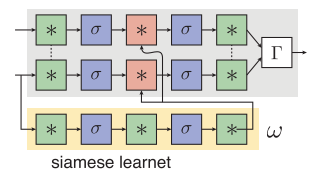
所做的第二个修改是single-stream learnet配置,仅使用siamese结构中的一个流
,然后用learnet
来预测它的参数。在这种情况下,比较模块
被看作是流
的最后一个层。需要注意的是:
- single-stream和learnet是不对称的,并且参数也是不同的;
- learnet不仅预测了最终比较层的参数 ,也预测了中间滤波器的参数;
如下图所示:
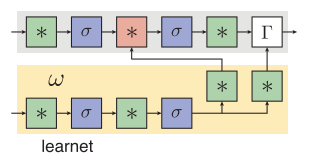
其中single-stream learnet结构,也就是图3,可以被理解为从一个样本中预测一个判别函数,siamese learnet结构,也就是图2,为两个图像的比较预测了一个embedding函数。
