核心数据结构:
核心原理解析:
高级命令使用:
---------------------
核心数据结构:
String:
127.0.0.1:6379> set hello world
OK
127.0.0.1:6379> get hello
"world"
127.0.0.1:6379> del hello
(integer) 1
127.0.0.1:6379> get hello
(nil)
127.0.0.1:6379> get counter
(nil)
127.0.0.1:6379> incr counter
(integer) 1
127.0.0.1:6379> get counter
"1"
127.0.0.1:6379> incrby counter 100
(integer) 101
127.0.0.1:6379> get counter
"101"实战场景:
1.缓存: 经典使用场景,把常用信息,字符串,图片或者视频等信息放到redis中,redis作为缓存层,mysql做持久化层,降低mysql的读写压力。
2.计数器:redis是单线程模型,一个命令执行完才会执行下一个,同时数据可以一步落地到其他的数据源。
3.session:常见方案spring session + redis实现session共享
2.Hash (哈希)
是一个Mapmap,指值本身又是一种键值对结构,如 value={{field1,value1},......fieldN,valueN}}
127.0.0.1:6379> hset user name1 hao
(integer) 1
127.0.0.1:6379> hset user email [email protected]
(integer) 1
127.0.0.1:6379> hgettall
(error) ERR unknown command 'hgettall'
127.0.0.1:6379> hgetall
(error) ERR wrong number of arguments for 'hgetall' c
127.0.0.1:6379> hgetall user
1) "name1"
2) "hao"
3) "email"
4) "[email protected]"
127.0.0.1:6379> hget user user
(nil)
127.0.0.1:6379> hget user name1
"hao"
127.0.0.1:6379> hset user name2 xiaohao
(integer) 1
127.0.0.1:6379> hset user email2 [email protected]
(integer) 1
127.0.0.1:6379> hgetall user
1) "name1"
2) "hao"
3) "email"
4) "[email protected]"
5) "name2"
6) "xiaohao"
7) "email2"
8) "[email protected]"实战场景:
1.缓存: 能直观,相比string更节省空间,的维护缓存信息,如用户信息,视频信息等。
2.电商购物车:
2.1 按照用户ID为key,按照商品id为field,商品数量为value.
3.链表
127.0.0.1:6379> lpush mylist 1 2 ll ls mem
(integer) 5
127.0.0.1:6379> lrange mylist 0 -1
1) "mem"
2) "ls"
3) "ll"
4) "2"
5) "1"
127.0.0.1:6379>1.timeline:例如微博的时间轴,有人发布微博,用lpush加入时间轴,展示新的列表信息。
4.Set 集合
集合类型也是用来保存多个字符串的元素,但和列表不同的是集合中 1. 不允许有重复的元素,2.集合中的元素是无序的,不能通过索引下标获取元素,3.支持集合间的操作,可以取多个集合取交集、并集、差集。
127.0.0.1:6379> sadd myset hao hao1 xiaoha hao
(integer) 3
127.0.0.1:6379> SMEMBERS myset
1) "hao"
2) "xiaoha"
3) "hao1"
127.0.0.1:6379> SISMEMBER myset hao
(integer) 1
127.0.0.1:6379>
实战场景;
1.标签(tag),给用户添加标签,或者用户给消息添加标签,这样有同一标签或者类似标签的可以给推荐关注的事或者关注的人。
2.点赞,或点踩,收藏等,可以放到set中实现
5.zset 有序集合
有序集合和集合有着必然的联系,保留了集合不能有重复成员的特性,区别是,有序集合中的元素是可以排序的,它给每个元素设置一个分数,作为排序的依据。
127.0.0.1:6379> SISMEMBER myset hao
(integer) 1
127.0.0.1:6379> zadd myscoreset 100 hao 90
(integer) 2
127.0.0.1:6379> zrange myscoreset 0 -1
1) "xiaohao"
2) "hao"
127.0.0.1:6379> zscore myscoreset hao
"100"实战场景:
1.排行榜:有序集合经典使用场景。例如小说视频等网站需要对用户上传的小说视频做排行榜,榜单可以按照用户关注数,更新时间,字数等打分,做排行。
核心原理解析:
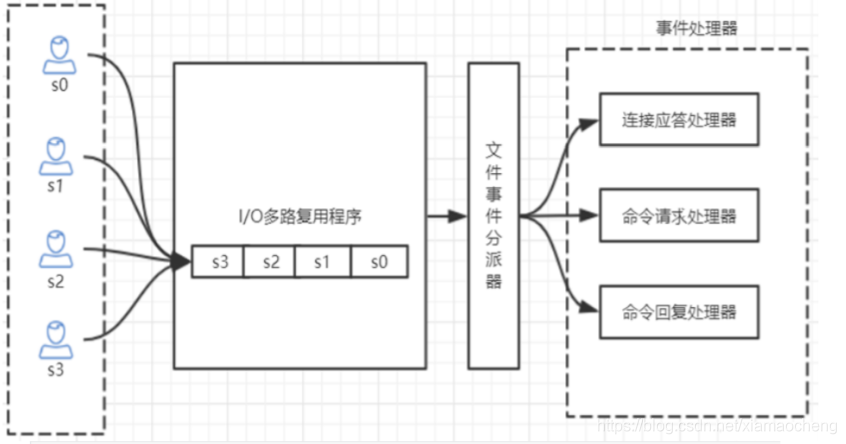
Redis核心原理 Redis的单线程和高性能 Redis 单线程为什么还能这么快? 因为它所有的数据都在内存中,所有的运算都是内存级别的运算,而且单线程避免了多线程的切换性 能损耗问题。正因为 Redis 是单线程,所以要小心使用 Redis 指令,对于那些耗时的指令(比如 keys),一定要谨慎使用,一不小心就可能会导致 Redis 卡顿。 Redis 单线程如何处理那么多的并发客户端连接? Redis的IO多路复用:redis利用epoll来实现IO多路复用,将连接信息和事件放到队列中,依次放到 文件事件分派器,事件分派器将事件分发给事件处理器。 Nginx也是采用IO多路复用原理解决C10K问题:
高级命令使用:
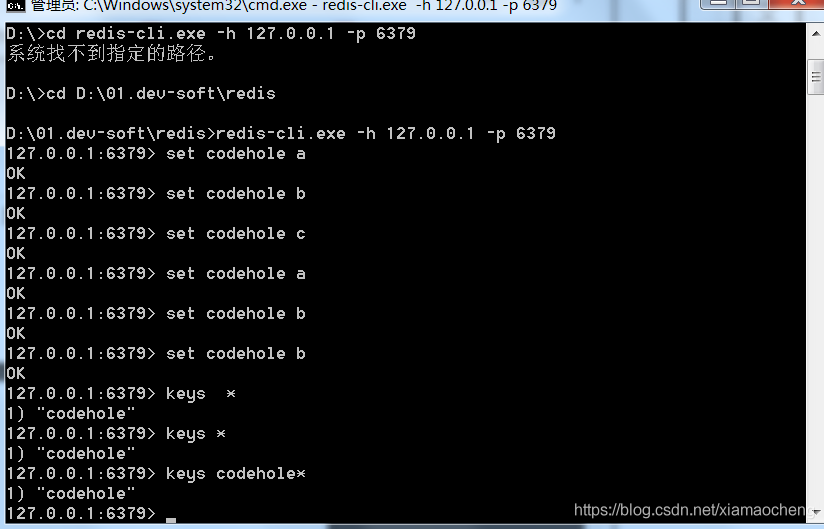
keys:全量遍历键,用来列出所有满足特定正则字符串规则的key,当redis数据量比较大时, 性能比较差,要避免使用
scan:渐进式遍历键 SCAN cursor [MATCH pattern] [COUNT count] scan 参数提供了三个参数,第一个是 cursor 整数值,第二个是 key 的正则模式,第三个是一次遍 历的key的数量,并不是符合条件的结果数量。第一次遍历时,cursor 值为 0,然后将返回结果中第 一个整数值作为下一次遍历的 cursor。一直遍历到返回的 cursor 值为 0 时结束。

相关命令:Info命令:
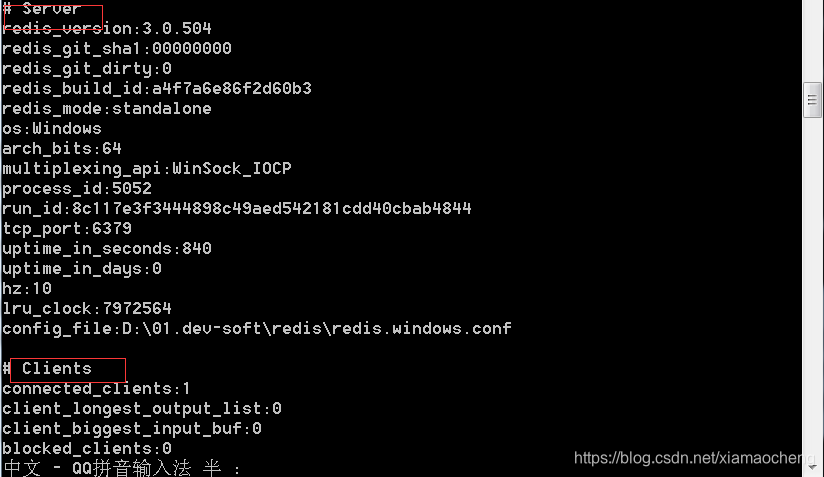
查看redis服务运行信息,分为 9 大块,每个块都有非常多的参数,这 9 个块分别是:
Server 服务器运行的环境参数
Clients 客户端相关信息
Memory 服务器运行内存统计数据
Persistence 持久化信息
Stats 通用统计数据
Replication 主从复制相关信息
CPU CPU 使用情况
Cluster 集群信息
KeySpace 键值对统计数量信息
附录: redis 查询命令,手册
https://www.redis.net.cn/order/
部分参考博文:
