目录
C++基本数据类型中表示字符的有两种:char、wchar_t。
1.char
一个char占一个字节。中文字符占用的是2个字节,即2个char。英文字符,占用的是1个字节,即1个char。
下面定义的“str” 为4个字节的char数组。
等号右边“中”是字符常量,const char [3],本身“中”字占用2个字节,加上字符常量末尾自动添加的0。
所以如果等号左边 str 定义的是 < 3 的数组长度就会提示编译不通过了。
中文字符占用的是2个字节,即2个char。英文字符,占用的是1个字节,即1个char。
为什么中文字符占用两个字节,因为用的是GBK编码方式。

比如上述的存的是 -42 和 -48 的原因就是 “中”的GBK编码的码值为 D6D0。
D6,也就是用有符号的一个字节表示的 -42。
D0,也就是用有符号的一个字节表示的 -48。

2.wchar_t
一个wchar_t占2个字节。一个字符 占用一个 wchar_t,不管是中文字符还是英文字符。
下面定义的“str” 为2个字节的wchar_t数组。
等号右边L“中”是宽字符常量,const wchar_t[2],本身“中”字占用一个wchar_t(2个字节),加上字符常量末尾自动添加的0。
所以如果等号左边 str 定义的是 < 2 的数组长度就会提示编译不通过了。
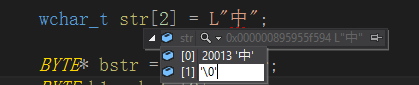
为什么是20013。因为宽字符用的是unicode编码,utf16,是4E2D。
wchar_t 是 unsigned short,那么就是4E2D就是20013。
3.TCHAR
当配置选择 使用多字节字符集的时候 TCHAR 为 char
当配置选择 使用Unicode字符集的时候 TCHAR 为 wchar_t
通过是否定义了_UNICODE宏,对TCHAR进行设置为不同的类型。
而 char 和 wchar_t 的区别就是对字符的编码方式不同,一个是GBK,一个是Unicode。

4.一些函数
1.char 转化为 16进制字符串
比如传进行的char* 是utf8编码的字符,那输出char*显示肯定是乱码,因为char是用GBK编码的。
通过下面的函数输出原始的utf8编码的16进制值。
#include <iostream>
#include <stdlib.h>
#include <string.h>
using namespace std;
char buffer[9]; //用于存放转换好的十六进制字符串,可根据需要定义长度
char * inttohex(int aa)
{
_itoa_s(aa, buffer, 16);
if (aa < 0)
{
// 取 buff 的最后三位
return &buffer[6];
}
else
{
// 取 buff 的前三位
return buffer;
}
return (buffer);
}
void main(void)
{
// 这里没有模拟utf8编码的字符,只是举例转为16进制的过程
char str[15] = "假如是一堆乱码";
char hex_final[100] = "";
// 最后一个str[14] = 0 就不翻译为hex了
for (int i = 0; i < 14; ++i)
{
char* hex_tmp = inttohex(str[i]);
strcat_s(hex_final, hex_tmp);
}
cout << hex_final << endl;
}2.字符串的UTF-8与GBK(或GB2312)编码转换
https://blog.csdn.net/xiaohu_2012/article/details/14454299
https://blog.csdn.net/u012234115/article/details/42292035
UE里面自带的字符转换函数
// Conversion typedefs
typedef TStringConversion<TCHAR,ANSICHAR,FANSIToTCHAR_Convert> FANSIToTCHAR;
typedef TStringConversion<ANSICHAR,TCHAR,FTCHARToANSI_Convert> FTCHARToANSI;
typedef TStringConversion<ANSICHAR,TCHAR,FTCHARToOEM_Convert> FTCHARToOEM;
typedef TStringConversion<ANSICHAR,TCHAR,FTCHARToUTF8_Convert> FTCHARToUTF8;
typedef TStringConversion<TCHAR,ANSICHAR,FUTF8ToTCHAR_Convert> FUTF8ToTCHAR;
