问题描述:
小明有 n 个作业,每个作业都有自己的 DDL,如果小明没有在 DDL 前做完这个作业,那么老师会扣掉这个作业的全部平时分。
所以小明想知道如何安排做作业的顺序,才能尽可能少扣一点分。
input:
输入包含T个测试用例。输入的第一行是单个整数T,为测试用例的数量。
每个测试用例以一个正整数N开头(1<=N<=1000),表示作业的数量。
然后两行。第一行包含N个整数,表示DDL,下一行包含N个整数,表示扣的分。
output:
对于每个测试用例,您应该输出最小的总降低分数,每个测试用例一行。
样例输入:
3
3
3 3 3
10 5 1
3
1 3 1
6 2 3
7
1 4 6 4 2 4 3
3 2 1 7 6 5 4
样例输出:
0
3
5
Hint
上方有三组样例。
对于第一组样例,有三个作业它们的DDL均为第三天,小明每天做一个正好在DDL前全部做完,所以没有扣分,输出0。
对于第二组样例,有三个作业,它们的DDL分别为第一天,第三天、第一天。小明在第一天做了第一个作业,第二天做了第二个作业,共扣了3分,输出3。
解题思路:
首先这明显是一个贪心问题,我们首先要确定一个贪心策略。我们通过分析题目,了解到目的是尽可能少的扣分,那么我们就想到优先把分值高的题目完成,而不是先完成ddl靠前的,这里我们可以举一个反例:
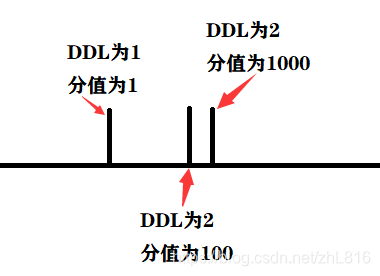
如果我们优先完成ddl靠前的题目的话,并且对于ddl相同是优先完成分值大的题目,那么对于上图,我们最终扣的分数为100,如果完成分值高的题目,那么我们最终扣的分数为1,这样就说明我们优先完成分值高的题目的贪心策略是可行的。
对于算法实现,我们课以用一个结构体才存储一个题目的信息,在输入信息的同时,记录所有题目分数之和,如果我们完成某个题目,就可以将该题目的分数从分数和中减去,这样剩余的分数就是我们扣的分。
在我们输入结束后,按题目的分值进行降序排序,之后我们就优先给分值最高的题目去找完成时间,在寻找时间是,应该从该题目的ddl开始向前遍历,因为这样才能对其他的题目影响最小。
Ps:
这种方法只适合数据范围比较小的题目,如果数据范围较大,肯定会超时,那么我们可以采用大根堆的方法,将复杂度降到
。
代码:
#include<iostream>
#include <algorithm>
#include<string.h>
using namespace std;
struct info { //题目信息结构体
int ddl;
int point;
bool operator < (const info f)const { //重载小于号
return point > f.point;
}
};
info all[1001];
int theday[1001]; //当前有没有完成题目
int main()
{
int n;
cin >> n;
for (int i = 0; i < n; i++)
{
memset(theday, 0, sizeof(theday));
int score = 0;
int number;
cin >> number;
for (int i = 0; i < number; i++)
{
int DDL;
cin >> DDL;
all[i].ddl = DDL;
}
for (int i = 0; i < number; i++)
{
int p;
cin >> p;
all[i].point = p;
score += p;//存储所有题目的分数和
}
sort(all, all + number); //按分数由大到小排序
for (int i = 0; i < number; i++)
{
for (int j = all[i].ddl; j > 0; j--) //从ddl开始向前遍历
{
if (theday[j] == 0) //如果有一天没有完成题目
{
theday[j] = 1; //可以在该天完成
score = score - all[i].point;
//将相应的题目在总分中减去
break;
}
}
}
cout << score << endl;
}
}
