文章目录
URLlib库概述
URLlib是python提供的一个用于操作URL的模块,常用于爬取网页,python3.x中将python2.x中的URLlib和URLlib2合并成为新的URLlib。
使用URLlib爬取网页
-
导入URLlib.request
import urllib.request -
使用urllib.request.urlopen打开需要爬取的网站并用web接收一下
web=urllib.request.urlopen('http://www.baidu.com') -
读取网页内容
data=web.read() #读取网页的全部内容 dataline=web.readline() #读取网页的一行内容 -
查看网页内容

-
将网页存到本地
urlllib.request.urlretrieve(url,filename)- url:网页的网址
- filename:存放文件的地址与名称
urllib.request.urlretrieve('http://www.baidu.com','./baidu. html')
打开文件

全过程import urllib.request web=urllib.request.urlopen('http://www.baidu.com') data=web.read() #读取网页的全部内容 dataline=web.readline() #读取网页的一行内容 print(dataline) print('-------------------') print(data) urllib.request.urlretrieve('http://www.baidu.com','./baidu.html')
urllib常用方法
- urllib.request.urlcleanup()
清除urlretrieve()执行时产生的缓存urllib.request.urlcleanup() - 网页.info()
返回当前环境有关的信息
因为之前将爬取的网页赋值给了web,所以直接使用web.info()即可

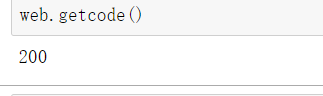
- 网页.getcode()
返回当前爬取网页的状态码,200为正确,其他均为不正确
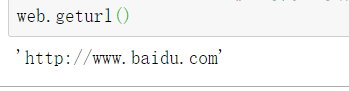
- 网页.geturl()
返回当前爬取的URL地址
- urllib.request.quote()
因为URL标准中不允许汉字、:、&等字符的出现,所以如果我们需要输入这些字符时需要编码
 - urllib.request.unquote()
- urllib.request.unquote()
对编码后的网址解码查看原网址

浏览器伪装
在爬取某些网页时会出现403错误,是因为这些网页设置了反爬虫措施。此时,我们可以设置Headers属性伪装成浏览器去访问这些网站。
获取浏览器Headers属性
打开百度网页→右键检查→上方network→点击左边all→点击百度一下,使网页发生动作→找到左下方最上边的www.baidu.com→点击后找到后边最下方的User-Agent,并将后面的值复制出来
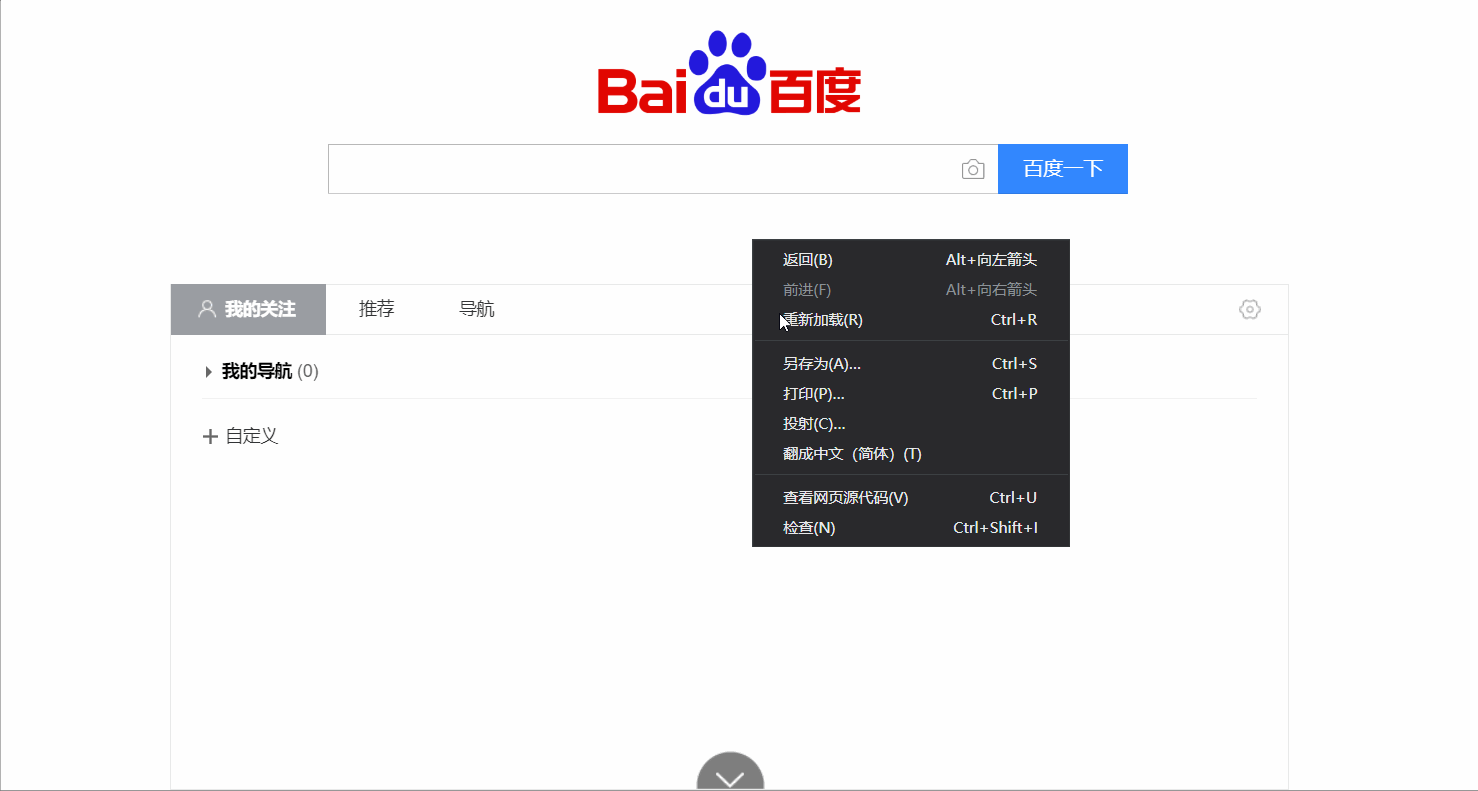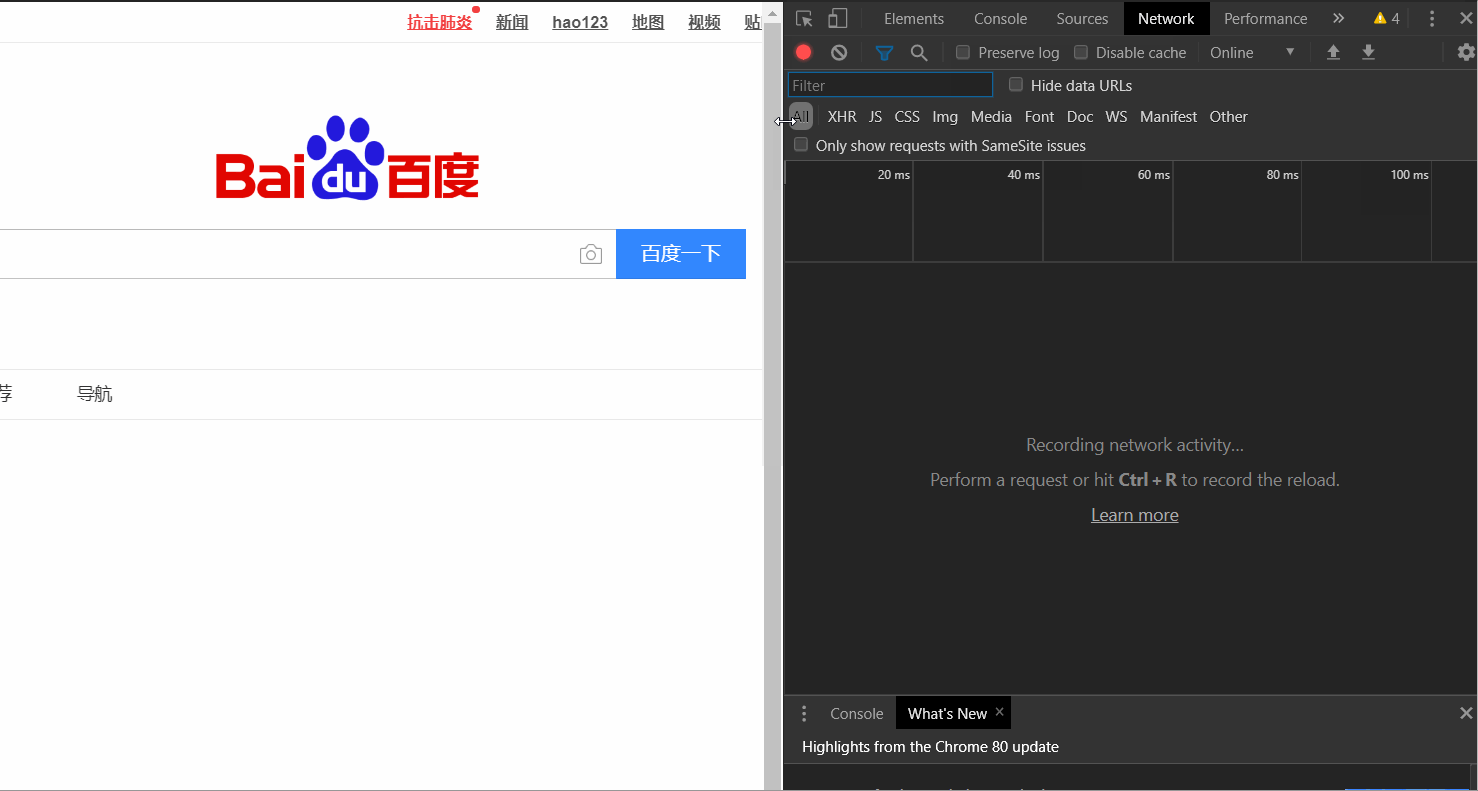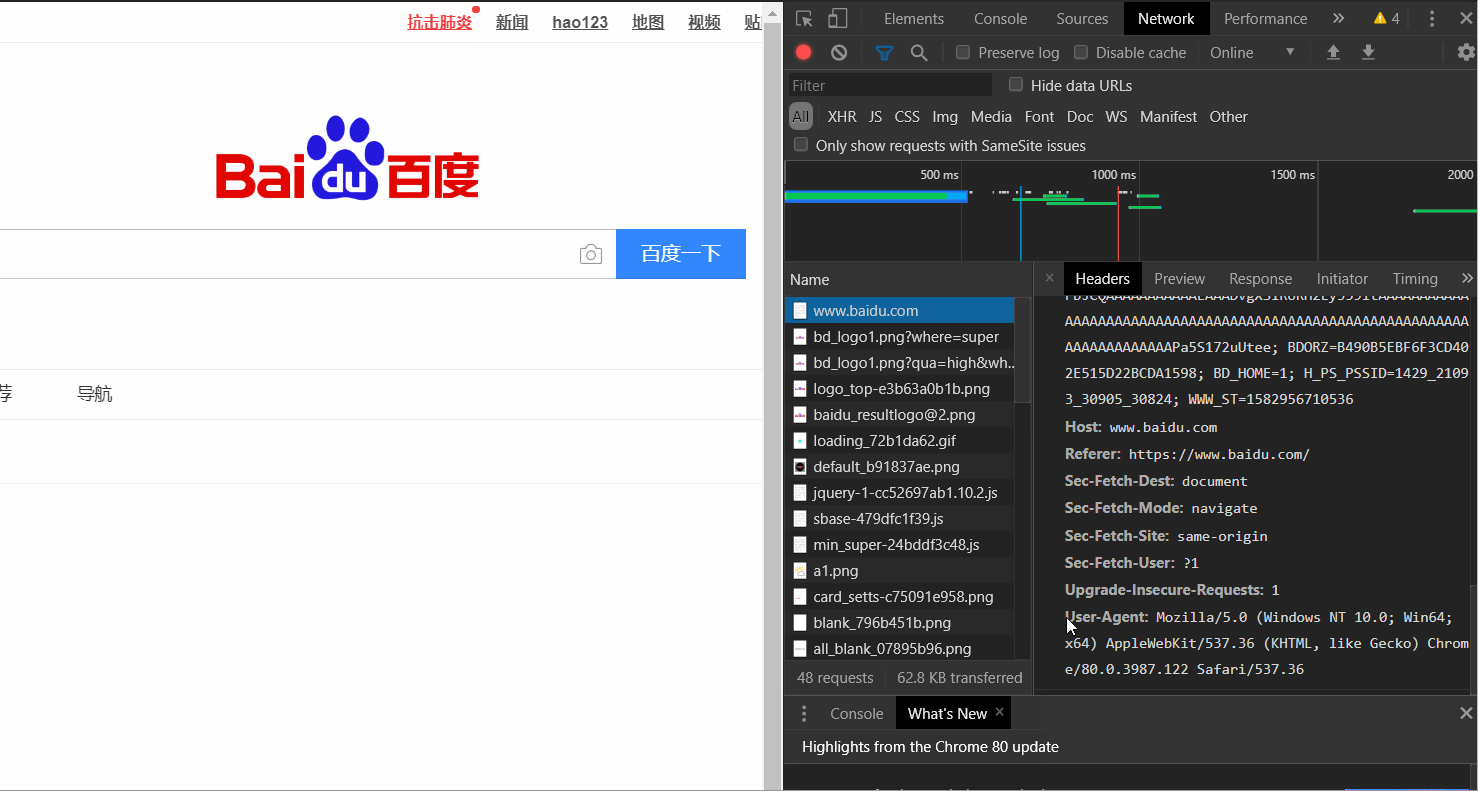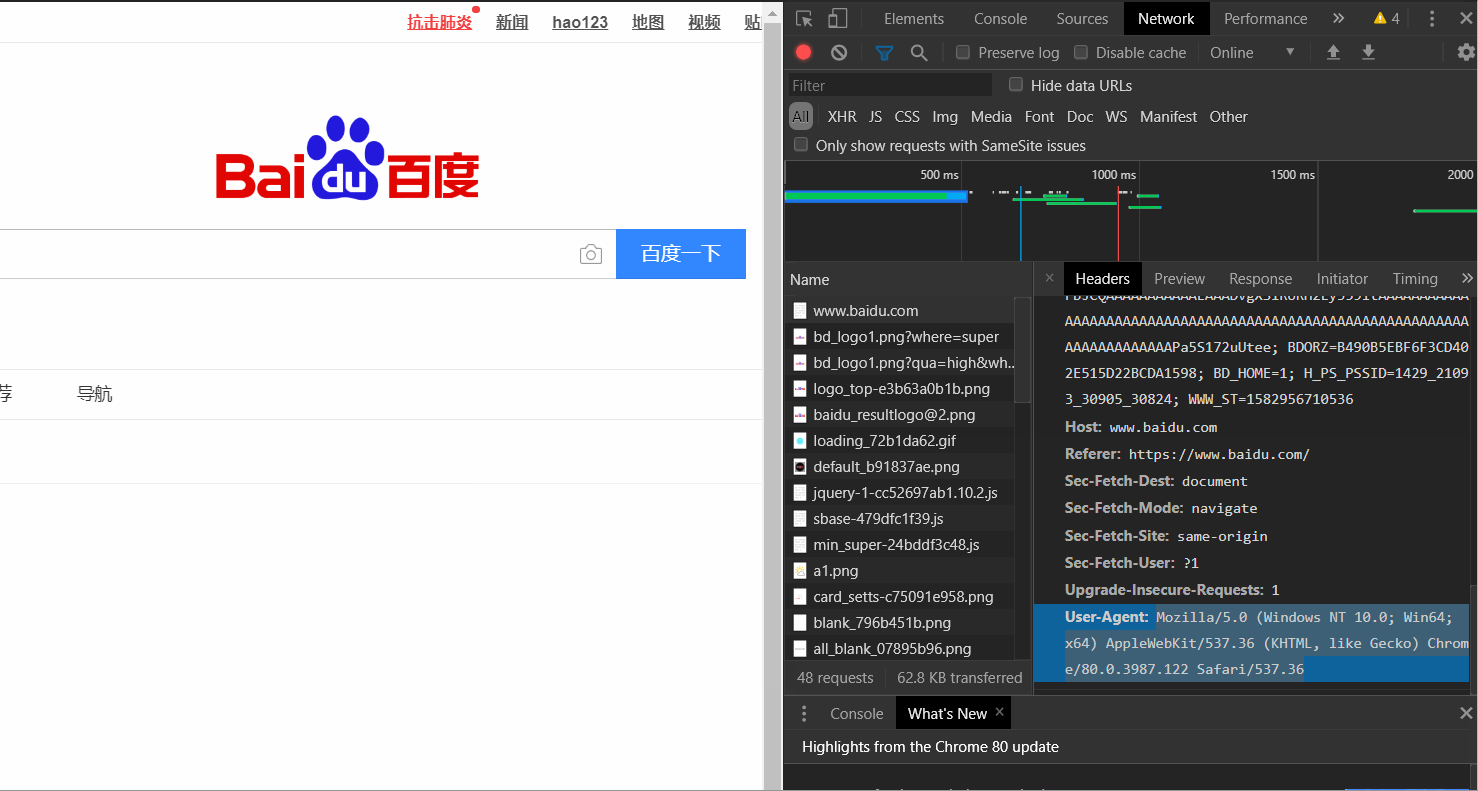
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36
使用build_opener()修改报头
此处以爬取my前一篇博客为例
-
直接使用之前的方法爬取
urllib.request.urlretrieve('https://blog.csdn.net/Late_whale/article/details/104559134','./baidu.html')
查看结果,发现该方法会被重定向到csdn首页

-
导入URLlib.request
import urllib.request -
定义一个url用于存储网址url
url='https://blog.csdn.net/Late_whale/article/details/104559134' -
定义headers用于存储之前的Headers
headers=("User-Agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36") -
定义一个urllib.request.build_opener()对象
opener=urllib.request.build_opener() opener.address=[headers] -
开始爬取数据
data=opener.open(url).read() -
将数据存进html文件
file=open('./test.html','web') file.write(data) file.close() -
爬取完毕后查看结果

爬取成功

使用add_header()添加报头
- urllib.request.Request(url).add_header(‘User-Agent’,value)
- url:需要爬取的网址url
- value:浏览器的headers属性值
import urllib.request
url='https://blog.csdn.net/Late_whale/article/details/104559134'
req=urllib.request.Request(url) #创建Request对象
req.add_header("User-Agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36")# 添加报头信息格式:对象名.add_header()
data=urllib.request.urlopen(req).read()#打开网址
file=open('./test_add.html','wb')
file.write(data)
file.close()


超时设置
在我们访问一个网页时,如果该网页长时间未响应,则系统会判断超时。我们可以根据自己的需求来设置超时的时间值。
设置超时时间值为10秒钟
urllib.request.urlopen('http://www.baidu.com',timeout=10)
http协议请求
http协议用于进行客户端和服务器端之间的消息传递,http协议请求主要分为6类
- get请求:get请求通过URL网址传递信息,可以直接在URL中写上要传递的信息,也可以由表单传递,如果用表单传递信息,表单中的信息会自动转化为URL地址中的数据,通过URL地址传递
- post请求:可以向服务器提交数据,是一种常用也比较安全的数据传递方式,登录时常使用该方式
- put请求:请求服务器存储一个资源,通常要直到存储的位置
- delete请求:请求服务器删除一个资源
- head请求:请求获取http报头信息
- options请求:获取当前URL支持的请求类型
- 另外trace请求和contact请求用得不多就不讲解了
代理服务器设置
用同一个ip地址去爬取同一个网页上时间久了会被屏蔽,我们可以用代理服务器来解决这个问题,这样我们自己爬取是用的就不是自己的IP了
urllib.request.ProxyHandler({‘http’:proxy_add})用于设置代理服务器信息
- proxy_add:代理服务器ip地址:端口
urllib.request.build_opener(proxy,urllib.request.HTTPHandler)
创建一个自定义opener对象
- proxy:代理服务器信息
- urllib.request.HTTPHandler:urllib.request.HTTPHandler类
data=urllib.request.urlopen(url).read().decode(‘utf-8’)
打开url对应的网址并指定编码为utf-8
使用正确的代理ip,爬取成功
def proxy(proxy_add,url):
import urllib.request
proxy=urllib.request.ProxyHandler({'http':proxy_add})
opener=urllib.request.build_opener(proxy,urllib.request.HTTPHandler)
data=urllib.request.urlopen(url).read().decode('utf-8')
return data
proxy_add='194.75.157.1:7777'
data1=proxy(proxy_add,'http://www.baidu.com')
print(data1)

DebugLog
开启DebugLog,即可打印程序运行日志
-
将urllib.request.HTTPHandler(debuglevel=1)和urllib.request.HTTPSHandler(debuglevel=1)里debuglevel设置为1
hh=urllib.request.HTTPHandler(debuglevel=1) hsh=urllib.request.HTTPSHandler(debuglevel=1) -
urllib.request.build_opener(hh,hsh)
用前面设置好的变量做参数定义opener对象opener=urllib.request.build_opener(hh,hsh) -
urllib.request.install_opener(opener)创建全局默认opener对象,在调用urlopen时也会使用我们自定义的opener对象
urllib.request.install_opener(opener) -
访问网页
data=urllib.request.urlopen('http://www.baidu.com')
import urllib.request
hh=urllib.request.HTTPHandler(debuglevel=1)
hsh=urllib.request.HTTPSHandler(debuglevel=1)
opener=urllib.request.build_opener(hh,hsh)
urllib.request.install_opener(opener)
data=urllib.request.urlopen('http://www.baidu.com')

URLRrror
通常情况下,产生URLError的情况如下:
- 连接不上服务器
- URL不存在
- 无网络
- 触发了HTTPRrror(返回状态码)
我们可以导入urllib.error使用try……catch语句对异常进行处理
服务器返回的状态码及其意义
| 状态码 | 意义 |
|---|---|
| 200 | OK,一切正常 |
| 301 | Moved Permanently,永久性地重定向到新URL |
| 302 | Found,暂时地重定向到新URL |
| 304 | Not Modified,请求的资源未更新 |
| 400 | Bad Request,非法请求 |
| 401 | Unauthorized,请求未经允许 |
| 403 | Forbidden,禁止访问 |
| 404 | Not Found,找不到该页面 |
| 500 | Internal Server Error,服务器内部错误 |
| 501 | Not Implemented,服务器不支持请求的操作 |
通常情况下我们都是先用HTTPError进行异常处理,若无法处理在用URLError进行异常处理
该情况下,无论何种异常都可以解决
访问一个不存在的网页
import urllib.request
import urllib.error
try:
urllib.request.urlopen('http://www.aaa.com')
except urllib.error.HTTPError as e:
print(e.code)
except urllib.error.URLError as e:
print(e.reason)

