文章目录
pandas
缺失值(nan)处理
处理思路
1.思路一
针对数据量比较大的样本,我们可以直接删除掉有缺失值的几行数据即可
2. 思路二
用改行的平均值、中位数等其他指标来对缺失值进行替换
判断是否存在nan
- pandas.isnull(DataFrame)
非nan返回False,nan返回True - pandas.notnull(DataFrame)
非nan返回True,nan返回False
删除含nan的样本
DataFrame.dropna(inplace=False)
- inplace:是否直接在原DataFrame上进行修改,=False表示在原DataFrame上进行修改,=True表示返回新的DataFrame,默认是False
替换/插补
DataFrame.fillna(value,inplace=False)
- value:用于替换nan的值
- inplace:是否直接在原DataFrame上进行修改,=False表示在原DataFrame上进行修改,=True表示返回新的DataFrame,默认是False
实例
-
检测是否存在nan
方法一
pandas.isnull(DataFrame)会判断DataFrame里每个元素值,为nan返回true,不是nan返回False
numpy.any(values)判断values里面的所有值,只要有一个true,就返回true;全为false就返回false
也就是说,np.any(pd.isnull(data))的结果为true就说明data里面含有nan
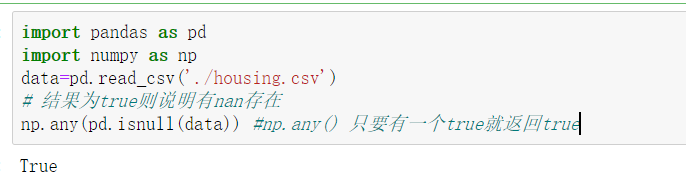
方法二
pandas.any(values)分别在每个字段里判断values,只要有一个true,就返回true;全为false就返回false,最终返回每个字段的bool值
pd.isnull(data).any()表示,为true的字段含有nan

pandas.innull()和pandas.notnull()用法一样,均可用于检测nan,返回值相反 -
处理nan值
-
删除含nan的样本
原文件是20640行,删除含nan的行后是20433行

-
替换nan值
用该列的平均值或其他指标替换nan扫描二维码关注公众号,回复: 10272187 查看本文章
之前求得,nan值是在total_bedrooms列上,现在用该列平均值替换nan即可

data[‘total_bedrooms’].fillna(value=data[‘total_bedrooms’].mean(),inplace=True),用total_bedrooms列的平均值替换该列的nan值,最后检测发现没有nan

一般来说,删除nan和替换nan只用其一
-
非nan的缺失值处理
常见的非nan的缺失值,如?、#等
处理思路
- 将其替换成nan
DataFrame.replace(to_replace=,value=)- to_replace:想替换的符号,如’?‘
- value:用于替换的值
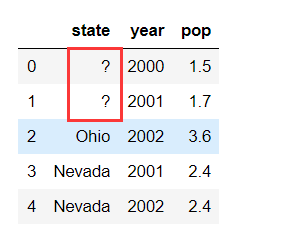
用numpy.nan替换?

- 处理nan
见上面 缺失值(nan)处理
数据离散化
什么是数据离散化
连续属性的离散化就是在连续属性的值域上,将值域划分为若干个离散的区间,最后用不同的符号或整数值代表落在每个子区间中的属性值。
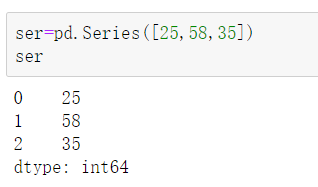
例
原始数据:年龄25、58、35…
将年龄分为几个阶段[18-30),[30-45),[45-60)
这样就可以将数据分到三个区间,最终变成一个矩阵
[18-30) [30-45) [45-60)
成年 中年 老年
25 1 0 0
58 0 0 1
35 0 1 0
这种数据表示方法就是数据离散化,这种方法叫做one-hot编码/哑变量
为什么要离散化
连续属性的离散化是为了简化数据结构,离散化技术可以用来减少给定连续属性值的个数,离散化方法经常作为数据挖掘的工具
数据离散化思路
-
分组
自动分组:pandas.qcut(data,bins)- data:需要分组的数据
- bins:需要分的组数
自定义分组:pandas.cut(data,list)
- data:需要分组的数据
- list:自定义好的分组区间用列表形式传入
分组完成之后,会返回一个Series
-
将分组好的数据转化为one-hot编码
pandas.get_dummies(series,prefix)- series:之前分组好的序列
- prefix:显示结果分组的前缀
实例
- 需要处理的数据
- 分组
对原数据进行自动分组

对原数据进行自定义分组

- 将序列转化为one-hot编码

pandas.concat()
pandas.concat([df1,df2],axis=1)
- 按行或列进行合并,axis=0为列,axis=1为行
示例
将下列两个df合并
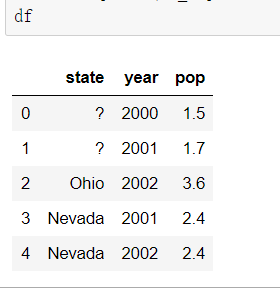

在df1列上对df2进行合并

在df1行上对df2进行合并

如果两个df字段不一致的情况下进行列合并,则df2中没有df1的字段会填充nan,df1中没有df2的字段也会填充nan

pandas.merge()
pandas.merge(left,right,how=‘inner’,on)
- left:左侧表
- right:右侧表
- how:连接方式,默认是inner内连接,left左连接,right右连接
- on:连接的字段,用于连接的字段会自动去重
交叉表
交叉表用于计算一列数据对于另外一列数据的分组个数(寻找两个列之间的关系)
pandas.crosstab(values1,values2)
用ocean_proximity,median_house_value两列画交叉表,前者代表与海的距离,后者代表房价

生成的交叉表如图,

交叉表的索引是ocean_proximity列上的所有取值

透视表
DataFrame.pivot_table([],index)
- []:需要分组的字段
- index:分组之后的索引
直接生成ocean_proximity与对应的平均房价表

分组与聚合
什么是分组与聚合
分组与聚合是分析数据的一种方式,通常与一些统计函数一起使用,查看数据的分组情况
- 分组:将含有某个或某些共同属性的数据分到同一个组,如某位学生的各科成绩,
- 聚合:将每组的数据求出最大值或最小值就是一个聚合的过程
如何实现分组与聚合
- 分组 DataFrame/Series.groupby(key,as_index=False)
- key:分组的列数据,可以多个
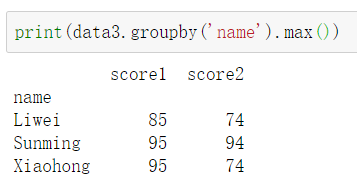
原始数据data3, DataFrame.groupby()

对data3按name进行分,分组的结果并不能直接看到,需要聚合之后才能看到

- 聚合 :求某个统计值就是聚合
对data3聚合,求出每列的最大值
对data3聚合,求出每列的平均值

