文章目录
pandas
- 专门用于数据挖掘的开源python库
- 以numpy为基础,借助numpy模块在计算方面性能高的优势
- 基于matplotlib,能够简便的画图
- 提供独特的数据结构—DataFrame、Panel、Series
pandas的优势
- 便捷的数据处理能力
- 读取文件方便
- 封装了Matplotlib,numpy库,便于画图和计算
DataFrame
pandas核心数据结构—DataFrame
- DataFrame是具有行索引和列索引的二维数组
创建DataFrame
直接通过二维数组创建DataFrame,会生成默认索引的DataFrame

DataFrame的结构
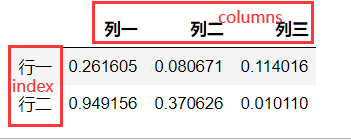
DataFrame对象不仅由行索引,又有列索引,是一个具有行列索引的二维数组
- 行索引,表示不同行的横向索引,叫做index
- 列索引,表示不同列的纵向索引,叫做columns
DataFrame的属性
DataFrame.shape
返回DataFrame的行列数(a,b),a表示行数,b表示列数

DataFrame.index
返回DataFrame的行索引

DataFrame.columns
返回DataFrame的列索引

DataFrame.values
返回DataFrame里的数据

DataFrame.T
返回DataFrame的转置

DataFrame的方法
DataFrame.head()
默认返回DataFrame的前五行,不足五行的直接返回

传入需要取的行数,如我想取7行,DataFrame.head(7)即可

DataFrame.tail()
默认返回DataFrame的最后五行,不足五行的直接返回

可以传入需要取的行数,如需要取倒数7行,则DataFrame.tail(7)

DataFrame索引设置
DataFrame索引只能整体修改,即只支持行索引或列索引整体修改,不支持行索引或列索引某个元素单独修改
修改DataFrame的行索引
- 创建DataFrame时,传入列表赋值给index

- 用一个新列表对DataFrame.index重新赋值即可完成修改,

修改DataFrame的列索引
- 创建DataFrame时,传入一个列表对DataFrame.columns进行赋值

- 用一个新列表对DataFrame.columns重新赋值即可完成修改

重设索引
DataFrame.reset_index(drop=False)
- 设置新的索引
- 默认drop值为false,即不删除原来索引,True则删除原来的索引
- 常用于某行或某几行数据被删掉
直接使用会将原索引存进DataFrame中

传入参数drop=True,则会删除之前的index

将某列值设置为索引
DataFrame.set_index(keys,drop=False)
- keys:列索引名称或列索引名称的列表
- drop:默认值为True,删除原索引,如设置为False则会保留原索引
将列一设置为新索引

将列一,列二设置为新索引

DataFrame索引操作
DataFrame不能像numpy那样直接通过索引获取数据
直接使用列行索引(先列后行)
直接使用列行索引来访问某一个元素

按名字索引
使用DataFrame.loc来获取某一个元素
使用方式DataFrame.loc[‘name1’][‘name2’] 或 DataFrame.loc[‘name1’,‘name2’]

按数字索引
使用DataFrame.iloc来获取某一个元素
使用方式DataFrame.iloc[行标][列标]

组合索引
使用DataFrame.ix可以直接使用数字和名字的混合索引

使用DataFrame.loc混合index使用组合索引

使用DataFrame.iloc和DataFrame.columns.get_indexer(‘列名’)

DataFrame赋值操作
- 对列赋值
- 直接对某列赋值会修改该列的值,

- 若被赋值的列不存在则DataFrame会新增一列

- 对元素赋值
对存在元素赋值会修改元素的值,对不存在元素赋值会报错

DataFrame排序
对内容排序
使用DataFrame.sort_values(by=‘列名’,ascending=True)对内容进行排序
- 单个键或多个键进行排序
- 默认(ascending=True)升序,ascending=False则表示降序
对单个键pop升序排列

对单个键pop降序排列

对两个键pop和year进行降序排列,优先比较pop如果pop值相等就比较year值

对索引排序
DataFrame.sort_index()对索引进行排序

DataFrame运算
算术运算
- DataFrame.add(number)或DataFrame+number
- 将DataFrame的某列或整个DataFrame加上某个数字

- DataFrame.sub(number)或DataFrame-number
- 将DataFrame的某列或整个DataFrame减去某个数字

逻辑运算
逻辑运算符< > | &
用>运算符筛选某列大于某个值的数据,<用法与>类似
| 是或 &是且,常与><结合起来运用
筛选出pop值大于2的数据

筛选出的数据可以直接用DataFrame查看

筛选出pop大于2且year小于2002

查看筛选出来的结果
 逻辑运算函数
逻辑运算函数
-
query(str) 查询字符串
DataFrame.query(’需要查询的语句‘)筛选出pop大于2且year小于2002

-
isin(values) 判断一组数是否为values里的值
判断pop列中值是否是2.4或3.2

查看筛选出来的结果

统计运算
- DataFrame.describe()
获取DataFrame常用的统计指标 - DataFrame.sum()
对DataFrame每列进行求和 - DataFrame.max()
获取DataFrame每列的最大值 - DataFrame.min()
获取DataFrame每列的最小值 - DataFrame.mean()
获取DataFrame每列的平均数 - DataFrame.median()
获取DataFrame每列的中位数 - DataFrame.var()
获取DataFrame每列的方差 - DataFrame.std()
获取DataFrame每列的标准差 - DataFrame.idxmax()
获取DataFrame每列的最大值的索引 - DataFrame.idxmin()
获取DataFrame每列的最小值的索引 - 累计统计函数
| 函数名 | 作用 |
|---|---|
| cumsum | 计算前1/2/3/…/n个数的和 |
| cummax | 计算前1/2/3/…/n个数的最大值 |
| cummin | 计算前1/2/3/…/n个数的最小值 |
| cumprod | 计算前1/2/3/…/n个数的积 |
了解更多关于DataFrame DataFrame常用操作大全
自定义运算
apply(func,axis=0)
- func:自定义函数
- axis:=0,默认是列,=1表示行
自定义一个对列最大值最小值求和的函数

MultiIndex
用多列值作为索引时的索引,称为 多级索引对象或分层索引对象

属性
names
返回levels的名称

levels
以元组形式返回evel的值
Serires
一个带索引的一位数组,可以是DataFrame的一行或一列
取DataFrame的一行

取DataFrame的一列

Series的属性
series.index
返回series的index值

series.values
返回series的value值

创建Series
- 只指定内容,会使用默认索引

- 指定索引,生成的series索引就为指定的索引

- 通过字典创建,字典的键作为series的索引,字典的值作为series的值

Series排序
对内容进行排序
series.sort_values(ascending=False)
默认对series值进行升序排列,设为ascending=True即为降序排列

对索引进行排序
series.sort_values()对series的索引进行排列

了解更多关于Series Series对象常用操作大全
pandas 画图
pandas.DataFrame.plot(x=None,y=None,kind=‘line’)
- x label or position, default None,指定x轴
- y label or position, default None,指定y轴
- kind str
- ‘line’ : line plot (default)#折线图
- ‘bar’ : vertical bar plot#条形图
- ‘barh’ : horizontal bar plot#横向条形图
- ‘hist’ : histogram#柱状图
- ‘box’ : boxplot#箱线图
- ‘pie’ : pie plot#饼图
- ‘scatter’ : scatter plot#散点图 需要传入columns方向的索引
画year和pop的折线图

画year和pop的散点图

pandas文件读取与存储
csv文件的读取
pandas.read_csv(path=,usecols=[],names=[])
- path:需读取文件的所在路径
- usecols:指定读取需要的列
- names:没有字段的csv文件需要指定字段
直接读取整个csv文件

指定读取文件的板块编码 板块 公司家数 平均价格 涨跌额 涨跌幅 总成交量 总成交金额

csv文件的存储
DataFrame.to_csv(path=,columns=,index=,mode=,header=)
- path:存储文件到的路径
- columns:需要存储的DataFrame列
- index:是否存储索引值,=False表示不存储索引值,=True表示存储索引值
- mode:文件写入模式,=‘a’表示追加,=‘w’表示写入,不懂可以查看python 文件
- header:是否需要写入字段,=False表示不写入,=True表示写入
hdf5文件的介绍
hdf5文件读取和存储都需要指定一个键,值为要存储的DataFrame,所以hdf5是一个存储三位数据的文件
hdf5文件的读取
pandas.read_hdf5(path=,key=,**kwargs)
- path:需读取文件所在的路径
- key:读取的键
- mode:打开文件的模式
hdf5文件的存储
DataFrame.to_hdf5(path=,key=,**kwargs)
- path:文件存储的路径
- key:存储的键
hdf5的优点
- hdf5存储时支持压缩,使用的方式blosc,是速度最快的,同时pandas也默认支持
- 使用压缩可以提高磁盘利用率,节省空间
- hdf5是跨平台的,可以轻松迁移到hadoop上
json文件的读取
pandas.read_json(path=,orient=,lines=False)
- path:需读取文件所在的路径
- orient:读取进来的文件以什么样的形式展示,一般为‘records’
- lines:是否按行读取json文件,默认=False表示不按行读取,=True表示按行读取
json文件的存储
DataFrame.to_json(path)
- path:需存储文件到的路径
- orient:以什么样的形式存储文件,一般为‘records’
- lines:是否按行存储json文件,默认=False表示不按行存储,=True表示按行存储
