前言:
这次学习Http库的主要原因是希望自己能够理解Python http库大概的工作原理,由于精力和时间有限只能学习相关的内容,下面Request和response很多内容会省略过,感兴趣的小伙伴可以自己上网科普,另外为什么采取图片的格式呢,那边makedown编辑器说实话不太好用,所以在另外的软件上面编辑的此次博客,希望大家能够理解
—————————————————————————————————————————————————————————————
参考链接:
https://blog.csdn.net/qq_41723615/article/details/87946700 讲述的是http response headers和 requests headers的
https://blog.csdn.net/weixin_42217767/article/details/92760353 关于session工作原理的,主要是为什么弥补http的无连接
https://www.cnblogs.com/magicianyin/p/8529441.html 这个关于requests和response的,也很不错
https://blog.csdn.net/fanbaodan/article/details/84846872 response 结构图复制的网址
https://blog.csdn.net/xiaoming100001/article/details/81109617 学习Http和https区别的网址
- HTTP简介:
HTTP协议是Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于本地浏览器与万维网服务器之间的一种基于TCP/IP通信协议的文件传输协议,常见传送的文件有(HTML 文件, 图片文件, 查询结果)等。
- HTTP历史:

最大的变化莫过于http1.1和http2.0吧,在连接的稳定性、持久性、效率上做出挺大改变的
多路复用的作用: 通过单一的HTTP/2连接请求发起多重的请求-响应消息,多个请求stream共享一个TCP连接,实现多留并行而不是依赖建立多个TCP连接

我们比对一下两张图,可以发现多重复用的作用就是利用单个tcp连接调用多个请求回应的过程,相比之前的流程则是省去了很多的精力和时间。 - HTTP工作原理
-
工作对象:客户端-服务端
-
工作流程:浏览器 (HTTP客户端)通过URL向HTTP服务端(WEB服务器)发送所有请求。
-
http requests的结构图:

在爬虫当中,有时候需要设置user-agent,这是因为原先请求头中自带的user-agent被网页识别出是爬虫程序,我们需要修改相应的User-agent,这个User-agent可以自行在开发者工具network里面一栏中找到,这里就不做过多的介绍了,除此之外,爬虫程序有时候还需要修改refer字段,该字段指明的是该链接从何处(网页)被点击。 -
HTTP response结构:

当然浏览器所给出的回应中主要我们爬虫收集的是Html代码中的一些字段,数据,以及图片、音频、端口号码之类的二进制数据,再采用相应的形式将它们存储起来。 -
Web服务器类型:
- Apache服务器
- IIS服务器
-
访问端口号:
-
工作流程演示图:
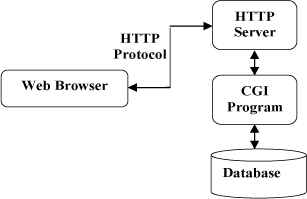
大致的流程如下:
Web Browser首先通过相应的URL找到Web Server的地址,然后向Web Server发送请求,大概是关于告诉Web Server自己所需要的东西(图片、HTML文件、音频),Web Server再通过CGI Program(网关端口)连接到管理自己文件的Web Database寻找需要的东西,最后再发给Web Browser一个相关内容,经过我们浏览器解析、渲染后就呈现出五彩缤纷的网页啦。
-
虽然说http给我们带来很多的遍历,首先它能够让我们在万维网上传输我们想要传输的文件,比如HTML文件、音频、图片、JSON等等,但是其安全性还是值得我们深思的,所以HTTP它并不是完全的好,它虽然能够高效率地传输文件的同时,它也有不少的缺点。
HTTP库优缺点:

而https正好就是http的加强版,可以理解为披着盔甲的http,但是为什么这么说呢,经由HTTP进行通信,利用SSL/TLS建立全信道,加密数据包,采取了先进混合加密方式来加密,保证了在数据传输的过程中,数据的隐蔽性,也同时断消了第三方希望在数据传输的过程中进行篡改,还通过证书来验证自己访问的对象。
4. Python Http库学习:
1. HTTP库作用:通过模拟Web Browser向Web Server发送请求,来接受浏览器返回的Response,主要用于网络爬虫。
2. HTTP库:
- [ ] Urllib
- [ ] Requests
- [ ] Httplib
