以下两篇博文来自:
1.https://blog.csdn.net/Dorothy_Xue/article/details/84641417
2.https://www.cnblogs.com/YiXiaoZhou/p/5999357.html
one-hot
one-hot是比较常用的文本特征特征提取的方法。
one-hot编码,又称“独热编码”。其实就是用N位状态寄存器编码N个状态,每个状态都有独立的寄存器位,且这些寄存器位中只有一位有效,说白了就是只能有一个状态。
下面举例说明:
有四个样本,每个样本有三种特征:
| feature1 | feature2 | feature3 | |
|---|---|---|---|
| sample1 | 1 | 4 | 3 |
| sample2 | 2 | 3 | 2 |
| sample3 | 1 | 2 | 2 |
| sample4 | 2 | 1 | 1 |
上图用十进制数对每种特征进行了编码,feature1有2种可能的取值,feature2有4种可能的取值,feature3有3种可能的取值。比如说feature3有3种取值,或者说有3种状态,那么就用3个状态位来表示,以保证每个样本中的每个特征只有1位处于状态1,其他都是0。
- 1->001
- 2->010
- 3->100
其他的特征也都这么表示:
| feature1 | feature2 | feature3 | |
|---|---|---|---|
| sample1 | 01 | 1000 | 100 |
| sample2 | 10 | 0100 | 010 |
| sample3 | 01 | 0010 | 010 |
| sample4 | 10 | 0001 | 001 |
这样,4个样本的特征向量就可以这么表示:
- sample1 -> [0,1,1,0,0,0,1,0,0]
- sample2 -> [1,0,0,1,0,0,0,1,0]
- sample3 -> [0,1,0,0,1,0,0,1,0]
- sample4 -> [1,0,0,0,0,1,0,0,1]
接下来看看怎么应用one-hot:
one-hot在特征提取上属于词袋模型(bag of words),假设语料库中有三句话:
- 我爱中国
- 爸爸妈妈爱我
- 爸爸妈妈爱中国
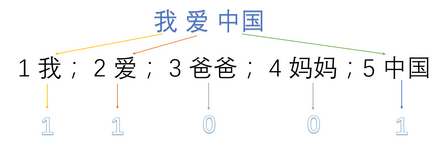
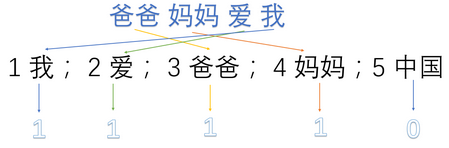
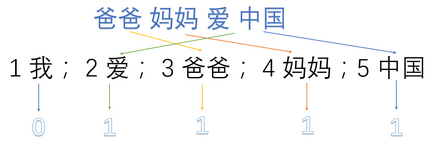
首先,将语料库中的每句话分成单词,并编号:
- 1:我 2:爱 3:爸爸 4:妈妈 5:中国
然后,用one-hot对每句话提取特征向量:(图来源于网络)
所以最终得到的每句话的特征向量就是:
- 我爱中国 -> 1,1,0,0,1
- 爸爸妈妈爱我 -> 1,1,1,1,0
- 爸爸妈妈爱中国 -> 0,1,1,1,1
那么这样做的优点和缺点都有什么?
优点:
- 解决了分类器处理离散数据困难的问题
- 一定程度上起到了扩展特征的作用(上例中从3扩展到了9)
缺点:
- one-hot是一个词袋模型,不考虑词与词之间的顺序问题,而在文本中,词的顺序是一个很重要的问题
- one-hot是基于词与词之间相互独立的情况下的,然而在多数情况中,词与词之间应该是相互影响的
- one-hot得到的特征是离散的,稀疏的
Bag-of-words 模型
之前教研室有个小伙伴在做文本方面的东西,经常提及词袋模型,只知道是文本表示的一种,可是最近看的关于CV的论文中也出现BoW模型,就很好奇BoW到底是个什么东西。
BoW起始可以理解为一种直方图统计,开始是用于自然语言处理和信息检索中的一种简单的文档表示方法。 和histogram 类似,BoW也只是统计频率信息,并没有序列信息。而和histogram不同的是,histogram一般统计的某个区间的频数,BoW是选择words字典,然后统计字典中每个单词出现的次数。
比如下面两个文档
- John likes to watch movies. Mary likes too.
- John also likes to watch football games.
首先可以找出两篇文档中单词的并集,作为dictionary
{“John”:1, ‘likes’:2, “to”:3, ‘watch’:4, ‘movies’:5, ‘also’:6, ‘football’:7, ‘games’:8, ‘Mary’:9, ‘too’:10}
那么两篇文档统计出来的BoW 向量就是
[1,2,1,1,1,0,0,0,1,1]
[1,1,1,1,0,1,1,1,0,0]
BoW model in CV
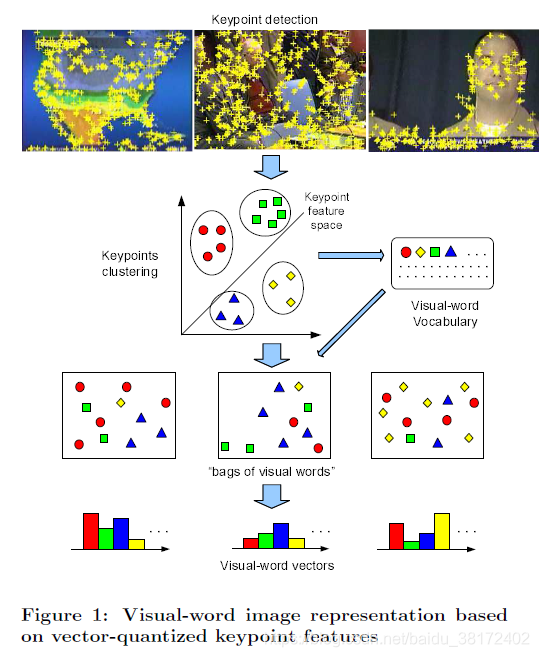
2003年以来,BoW出现在CV中,如图像分类、图像检索等。
其大概过程首先提取图像集特征的集合,然后通过聚类的方法聚出若干类,将这些类作为dictionary,即相当于words,最后每个图像统计字典中words出现的频数作为输出向量,就可以用于后续的分类、检索等操作。
以sift特征为例,假设图像集中包含人脸、自行车、吉他等,我们首先对每幅图像提取sift特征,然后使用如kmeans等聚类方法,进行聚类得到码本(dictionary)

之后在每一幅图像中统计sift特征点在码本上的频数分布,得到的向量就是该图像的BoW向量。
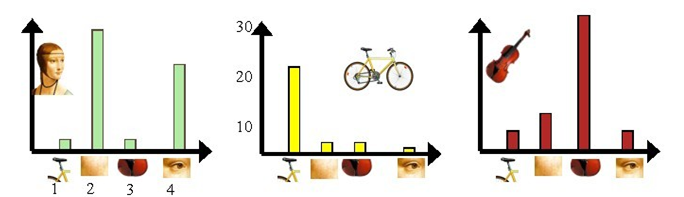
最后就可以使用这些向量进行模式识别的其他操作了。
下图中给出了一个整体的过程