前言
鄙人仅为一名普普通通大二学生,才学浅出,来此各地高人聚集处书写浅见,还望各位前辈高人多多指点海涵。我们诚邀各地有志之士加入我们的代码学习群交流:871352155(无论你会C/C++还是Java,Python还是PHP......有兴趣我们都欢迎你的加入,不过还请各位认真填写加群信息。群内目前多为大学生,打广告的先生女士就请不要步足了。我们希望有远见卓识的前辈能为即将步入社会的初犊提出建议指引方向。)
在之前啊,我写过一片关于Pyecharts的文章,是关于数据可视化,有兴趣的朋友可以去看看https://blog.csdn.net/weixin_43341045/article/details/104137445,关于这个数据的来源啊,可以很多种,我这里就介绍下爬虫。爬虫也有很多种库,写过一篇关于Selenium的爬虫https://blog.csdn.net/weixin_43341045/article/details/104014416,我觉得吧这些库各有优缺点。比如上次的Selenium这玩意老厉害了可以模拟成人为的行动,很容易就骗到那个服务器。今天我来介绍下BeautifulSoup4,很美妙的汤哈,确实简单方便通俗易懂。
安装方法
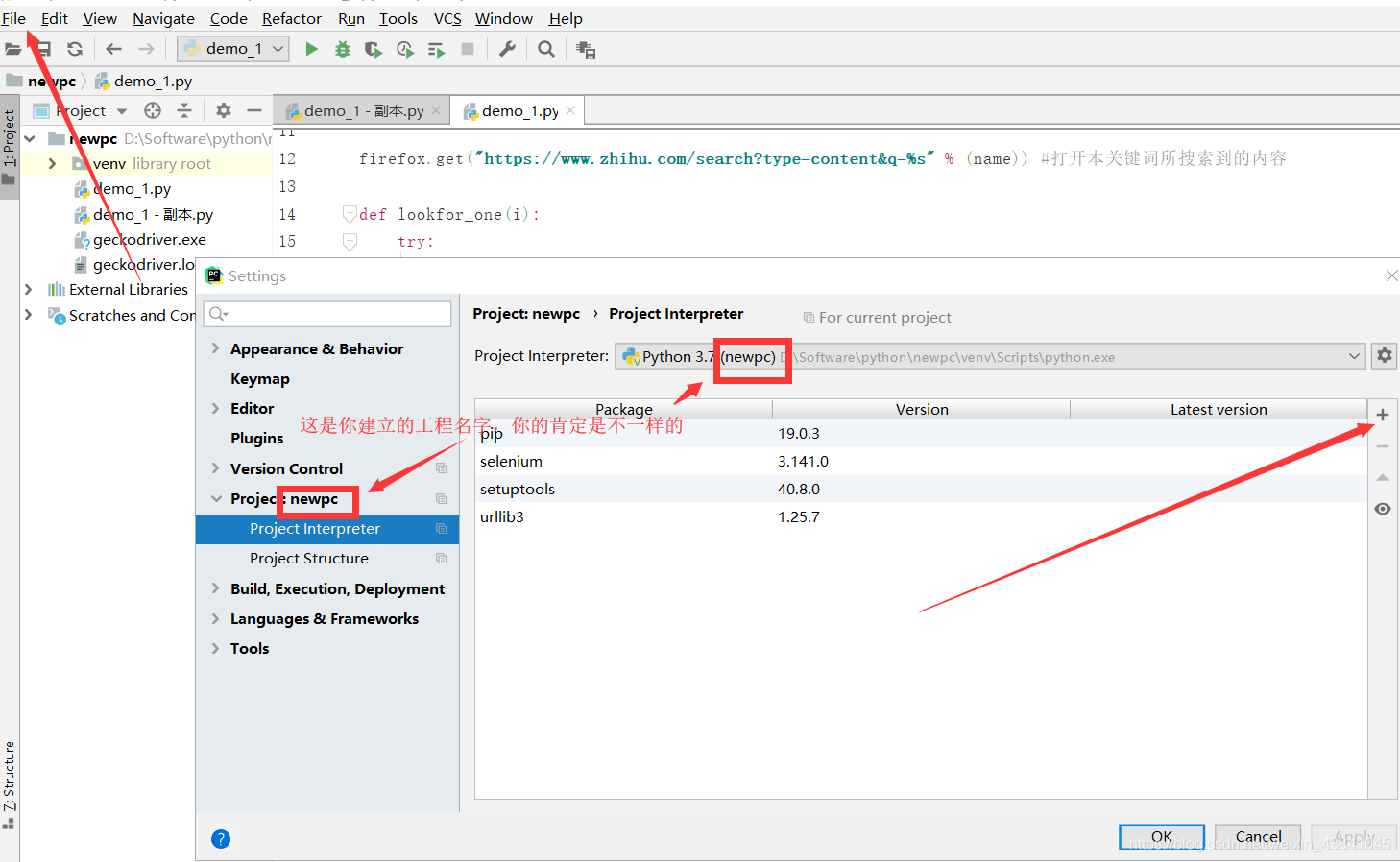
打开cmd后,输入pip install BeautifulSoup。如果你是用pycharm,左上角的File找到setting,然后在Project:XXX里面有个Project Interpreter,你会看见右边有一堆是你已经安装好的库,然后点击更靠右的+写上BeautifulSoup点击install package
基本语法
解析库
| Python标准库 | BeautifulSoup(html,’html.parser’) | Python内置标准库;执行速度快 | 容错能力较差 | |
| lxml HTML解析库 | BeautifulSoup(html,’lxml’) | 速度快;容错能力强 | 需要安装,需要C语言库 | |
| lxml XML解析库 | BeautifulSoup(html,[‘lxml’,’xml’]) | 速度快;容错能力强;支持XML格式 | 需要C语言库 | |
| htm5lib解析库 | BeautifulSoup(html,’htm5llib’) | 以浏览器方式解析,最好的容错性 | 速度慢 |
BeautifulSoup基本操作
BS4中文开发者文档地址https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/
from bs4 import BeautifulSoup
BS = BeautifulSoup(html,"html.parser")
# 获取title标签的所有内容
print(BS.title)
# 获取第一个tr标签的name,,class的值
print(BS.tr["name"])
print(BS.tr["class"])
# 缩进格式
print(BS.prettify())
# 获取所有的figure标签,并遍历打印figure标签的文本值
for item in BS.find_all("figure"):
print(item.get_text())
# 获取title标签的名称
print(BS.title.name)
# 获取第一个td标签中的所有内容
print(BS.td)
# 用.string获取标签内部的文字
print(BS.title.string)
# 取一个标签下标签的所有内容,比如body
print(BS.body)
# 取第一个img标签中的所有内容
print(BS.img)
# 取所有的a标签中的所有内容
print(BS.find_all("a"))
# 取特定标签id="u1"
print(BS.find(id="u1"))
# 获取所有的div标签,并遍历打印div标签中的src的值
for item in BS.find_all("div"):
print(item.get("src"))
实例
关于B站的专栏里面有很多精美的壁纸,一个一个下载,太麻烦了,用爬虫他不香吗???这里用极其简单的代码来实现这个功能。
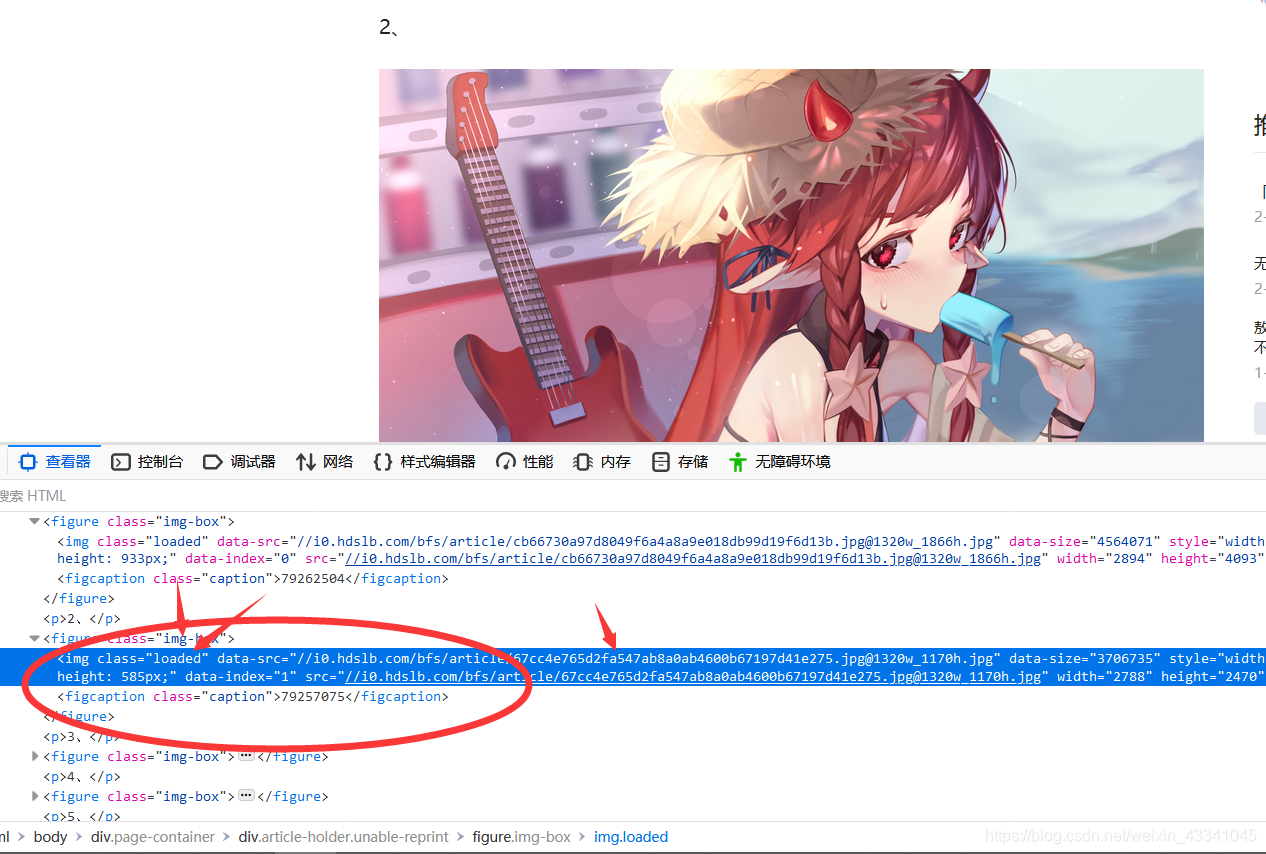
这个本来可以更精简化代码,但是B站这个很牛排!,我爬取下来后,代码是有残缺的,我估计是一种反扒措施

比如你看这个用F12查看浏览器元素你可以找到那个class和data-index等内容,而现在缺了不少导致定位什么的都有小问题(其实际就是我太菜了不会更高明的办法ToT),所以我先找到比较靠外的figure标签,然后定位下面的标签。
下面是极简化的9行代码。
import requests,urllib,re,os#该有的库都应该有哈
from bs4 import BeautifulSoup#重头戏当然要独占一排
imgurl,i=[],0#一个列表用来装爬取下来的地址,另外一个要给爬下来的图片写个名字
for picture in (BeautifulSoup((requests.get('https://www.bilibili.com/read/cv4566895?from=search')).text,'html.parser').find_all('figure',class_='img-box')):
for img in picture:#爬取下来后我们要取img标签下的data-src并保存到列表
if (img.get('data-src')!=None):imgurl.append(img.get('data-src'))
for downPic in (imgurl[1:-1]):#用列表切片取消第一个和最后一个图片。因为爬下来的图片第一个是“小电视”最后一个是“分享”不属于我们想要的
i+=1
urllib.request.urlretrieve('https:'+'%s'%downPic,filename=('%s.png'%(i)))#这里下载要注意,爬取后的图片前面没有https,我们要亲自加上 我怎么可能会轻易告诉你我的HTML系列作品上面的图片都是这样得来的呢?
同样的功能我们为了保险起见,加一个“大轮盘”user_agent_list,防止被检测到然后把我们丢出门外,同时也是为了具体介绍下功能
import requests,urllib
import random #为了后面这个伪装地址随机化
import re
import os
from bs4 import BeautifulSoup
#这个user_agent_list 网上都能查到哈,用来伪装自己的
user_agent_list = [\
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"\
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",\
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",\
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",\
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",\
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",\
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",\
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",\
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",\
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",\
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",\
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",\
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",\
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",\
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19 * .0.1061.1 Safari/536.3",\
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",\
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",\
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]
def download_html(url):#该函数就是为了防止被监测,每次爬取前都换一次地址
req = requests.get(url,headers ={'User-Agent':random.choice(user_agent_list)})
req.encoding = 'utf-8'
if req.status_code != 200:#爬取不到我们就走呗
raise Exception('error')
htmls = req.text
return htmls#返回值
imgurl,i=[],0
#find_all上面介绍过,用来找所有的figure标签,后面的意思就是找到class等于img-box的figure
for picture in (BeautifulSoup(download_html('https://www.bilibili.com/read/cv4566895?from=search'),'html.parser').find_all('figure',class_='img-box')):
for img in picture:
if (img.get('data-src')!=None):imgurl.append(img.get('data-src'))
for downPic in (imgurl[1:-1]):#一定要切片哈,不切片,你就会得到“小电视”和那个“分享”图片
i+=1#方便取名字,其实你也可以照这个代码,把图片名字也爬取下来
urllib.request.urlretrieve('https:'+'%s'%downPic,filename=('%s.png'%i))