
生成对抗网络(GAN, Generative Adversarial Networks )是一种深度学习模型,是近年来复杂分布上无监督学习最具前景的方法之一,可以图像生成,图像超清化,换脸,并且可以生成数据,模型通过框架中(至少)两个模块:
- 生成模型(Generative Model):生成一个仿真数据
- 判别模型(Discriminative Model):判别仿真数据是真实样本还是仿真样本
的互相博弈学习产生相当好的输出
一丶例子

- 绿色实线(green, solid line) 生成器
- 黑色点线 (black, dotted line) 真实数据
- 蓝色虚线(D, blue, dashed line) 判断器 :判断器低值时认为绿线是真实数据的分布,高值判断绿线不是真实数据的分布
所以我们不断优化生成器,使得判断器识别不出真假,并且我们也要不断优化判断器,使得生成器生成的数据更加拟合真实分布
二丶DCGAN模型:
1. DCGAN函数
从随机向量生成真实图像,随机会使得生成多张不同的图像,并且保证生成的都是真实的
其训练的函数为
CNN,RNN的损失函数的计算都是最小化,但是这个对抗网络的损失却需要大又需要小
- 是否是真实图像,输出1为真实图像,输出0为虚假图像
- 随机向量z经过生成器生成的图片
- 生成器G输入随机向量z,输出图像G(z)
- 判断器D输入一个图像,输出结果:是/否
当我们训练G的时候,也就是生成器,并且保持D不变,最小化V(D,G):
因为
是真实数据,我们希望判别器都判断出为真实图像,输出1,也就是判别输出的D(x)越大越好
因为
是随机向量,
为随机向量z经过生成器生成的图片,我们希望判别器都判断出为生成图像,输出0,也就是
最小,这样也就是
最大
最后我们得出要让判别器越好,也就是最大化函数
当我们训练D的时候,也就是判别器,并且保持G不变,最大化V(D,G):
这里不变了,我们希望的是生成器变得很强,也就是使得
最大,输出1,这样就是
最小
最后我们得出要让生成器越好,也就是最小化函数
2. DCGAN模型

2.1 模型细节
- 生成器使用的是strided 卷积,生成器使用fractional - strided 卷积
- 生成器和判断器都做批归一化,不应用到输入和输出,
- 不使用全连接层使用global pooling
- 生成器除了输出层使用tanh其他都用ReLu,判断器使用LeakReLu
2.2 生成器实现:

- 输入长度100的随机向量,
- 随机向量先做全连接,映射(project)到一个长的向量,然后变换(reshape)成 三维矩阵(4,4,1024)
- 做四次反卷积,每次反卷积使得长和宽变成原来的2倍,通道数变为二分之一
- 最后通道需要变为3,也就是变为RGB图
# with_bn_relu: 生成器最后一层不需要 batch_normalization 和 relu ,使用with_bn_relu去标志
def conv2d_transpose(inputs, out_channel, name, training, with_bn_relu=True):
with tfv1.variable_scope(name):
conv2d_trans = tfv1.layers.conv2d_transpose(inputs,
out_channel,
[5, 5],
strides=(2, 2),
padding='same')
if with_bn_relu:
bn = tfv1.layers.batch_normalization(conv2d_trans, training=training)
return tfv1.nn.relu(bn)
else:
return conv2d_trans
class Generator(object):
def __init__(self, channels, init_conv_size):
self._channels = channels
self._init_conv_size = init_conv_size
# Generator不止使用一次,构建时False , 之后为True 使得参数共享
self._reuse = False
# 类当初函数使用
def __call__(self, inputs, training):
# 变成tensor
inputs = tfv1.convert_to_tensor(inputs)
with tfv1.variable_scope('generator', reuse=self._reuse):
# 1. 随机向量先做全连接,映射(project)到一个长的向量,然后变换
# z -> fc -> [channels[0] * init_conv_size* init_conv_size] ->reshape [init_conv_size,init_conv_size,channels[0]]
with tfv1.variable_scope('input_conv'):
fc = tfv1.layers.dense(inputs,
self._channels[0] * self._init_conv_size * init_conv_size)
conv0 = tfv1.reshape(fc,
[-1, self._init_conv_size, self._init_conv_size, self._channels[0]])
bn0 = tfv1.layers.batch_normalization(conv0,
training=training)
relu0 = tfv1.nn.relu(bn0)
deconv_inputs = relu0
# 2. 做三次反卷积
for i in range(1, len(self._channels)):
# 是否为最后一层
with_bn_relu = (i != len(self._channels) - 1)
deconv_inputs = conv2d_transpose(deconv_inputs,
self._channels[i],
'deconv-%d' % i,
training,
with_bn_relu)
img_inputs = deconv_inputs
# 强制输入为 -1,1之间
with tfv1.variable_scope('generate_imgs'):
imgs = tfv1.tanh(img_inputs, name='imgs')
self._reuse = True
# 变量存储
self.variables = tfv1.get_collection(tfv1.GraphKeys.TRAINABLE_VARIABLES, scope='generator')
return imgs
2.3 判断器实现
def conv2d(inputs, out_channel, name, training):
def leaky_relu(x, leak=0.2, name=""):
return tfv1.maximum(x, x * leak, name=name)
with tfv1.variable_scope(name):
conv2d_output = tfv1.layers.conv2d(inputs,
out_channel,
[5, 5],
strides=(2, 2),
padding='same')
bn = tfv1.layers.batch_normalization(conv2d_output,
training=training)
return leaky_relu(bn, name='outputs')
class Discriminator(object):
def __init__(self, channels):
self._channels = channels
self._init_conv_size = init_conv_size
# Discriminator,使得参数共享
self._reuse = False
def __call__(self, inputs, training):
inputs = tfv1.convert_to_tensor(inputs, dtype=tf.float32)
conv_inputs = inputs
with tfv1.variable_scope('discriminator', reuse=self._reuse):
for i in range(len(self._channels)):
conv_inputs = conv2d_transpose(conv_inputs,
self._channels[i],
'conv-%d' % i,
training)
# 全连接
fc_inputs = conv_inputs
with tfv1.variable_scope('fc'):
flatten = tfv1.layers.flatten(fc_inputs)
logits = tfv1.layers.dense(flatten, 2, name='logits')
self._reuse = True
self.variables = tfv1.get_collection(tfv1.GraphKeys.TRAINABLE_VARIABLES, scope='discriminator')
return logits
2.4 DCGAN实现
class DCGAN(object):
def __init__(self):
self._generator = Generator(g_channel, init_conv_size)
self._discriminator = Discriminator(d_channel)
# 计算图构建
def build(self):
# 真图像
self._img_placeholder = tfv1.placeholder(tf.float32,
(batch_size, img_size, img_size, 1))
# 假图像向量
self._z_placeholder = tfv1.placeholder(tf.float32,
(batch_size, z_dim))
# 假图像
generate_imgs = self._generator(self._z_placeholder,
training=True)
# 真图像判断器判断结果
real_img_logits = self._discriminator(self._img_placeholder,
training=True)
# 假图像判断器判断结果
fake_img_logits = self._discriminator(generate_imgs,
training=True)
loss_on_fake_to_real = tfv1.reduce_mean(
tfv1.nn.sparse_softmax_cross_entropy_with_logits(
labels=tfv1.ones([batch_size], dtype=tf.int64),
logits=fake_img_logits))
loss_on_fake_to_fake = tfv1.reduce_mean(
tfv1.nn.sparse_softmax_cross_entropy_with_logits(
labels=tfv1.zeros([batch_size], dtype=tf.int64),
logits=fake_img_logits))
loss_on_real_to_real = tfv1.reduce_mean(
tfv1.nn.sparse_softmax_cross_entropy_with_logits(
labels=tfv1.ones([batch_size], dtype=tf.int64),
logits=real_img_logits))
tfv1.add_to_collection('g_loss', loss_on_fake_to_real)
tfv1.add_to_collection('d_loss', loss_on_fake_to_fake)
tfv1.add_to_collection('d_loss', loss_on_real_to_real)
loss = {
'g': tfv1.add_n(tfv1.get_collection('g_loss'), name='total_g_loss'),
'd': tfv1.add_n(tfv1.get_collection('d_loss'), name='total_d_loss')
}
return self._z_placeholder, self._img_placeholder, generate_imgs, loss
# 构建train_op
def build_train_op(self, loss, learning_rate, beta1):
g_opt = tfv1.train.AdamOptimizer(learning_rate=learning_rate, beta1=beta1)
d_opt = tfv1.train.AdamOptimizer(learning_rate=learning_rate, beta1=beta1)
print(self._generator.variables)
print(self._discriminator.variables)
g_opt_op = g_opt.minimize(
loss['g'], var_list=self._generator.variables)
d_opt_op = d_opt.minimize(
loss['d'], var_list=self._discriminator.variables)
# 交叉训练 g_opt_op和 d_opt_op
with tfv1.control_dependencies([g_opt_op, d_opt_op]):
return tfv1.no_op(name='train')
反卷积
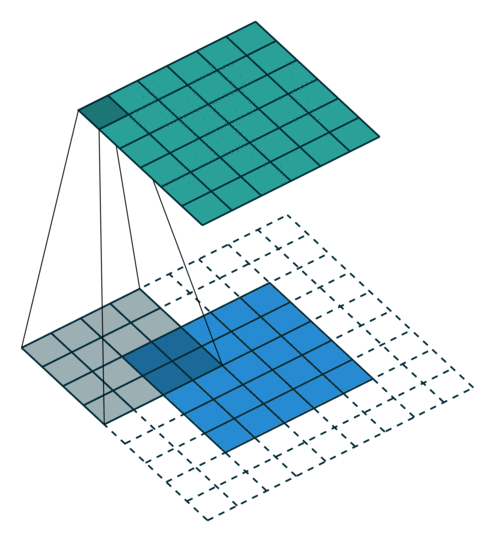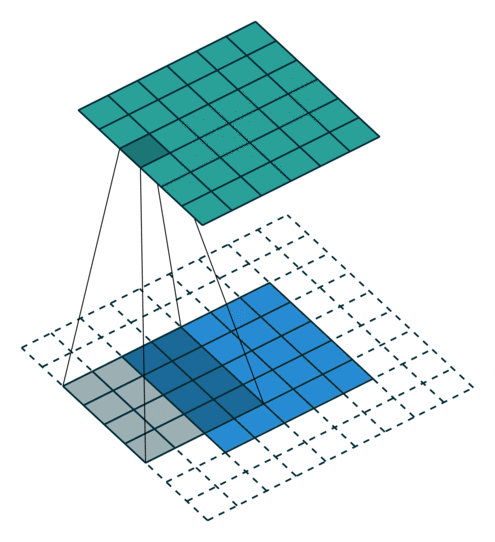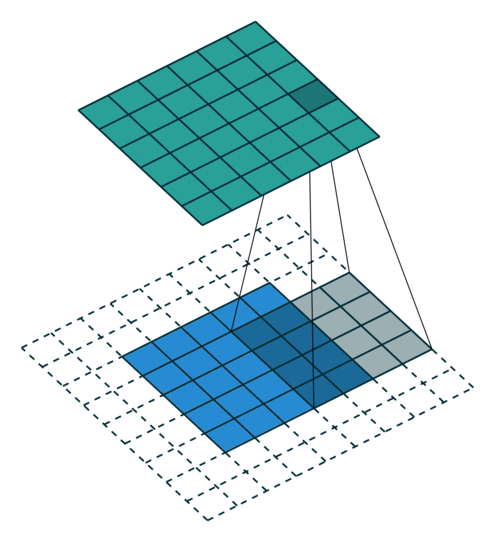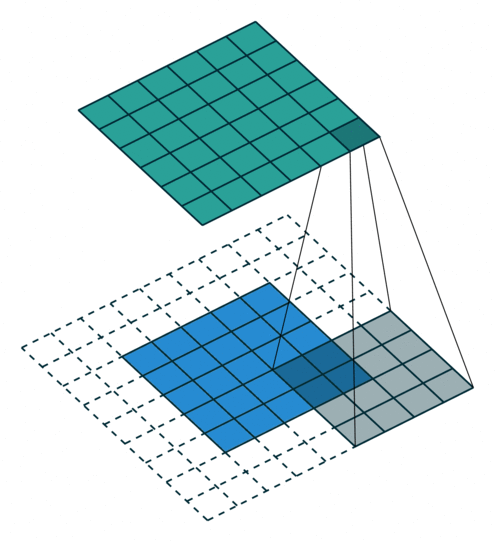
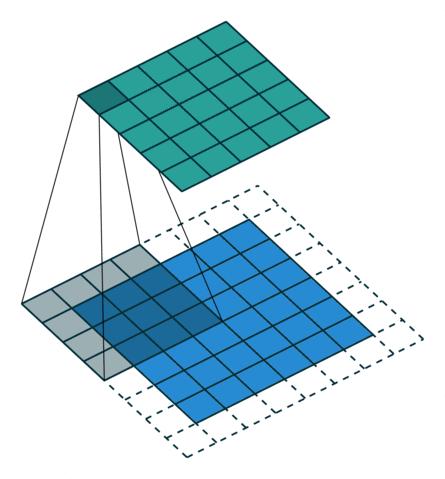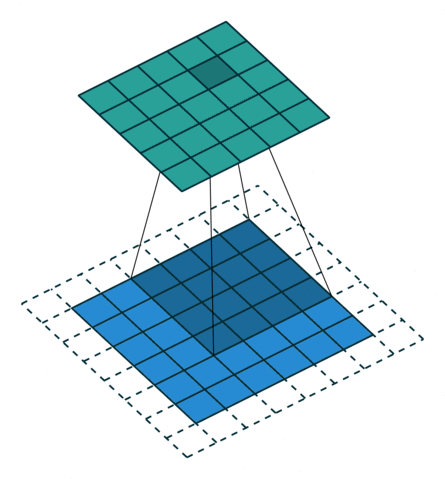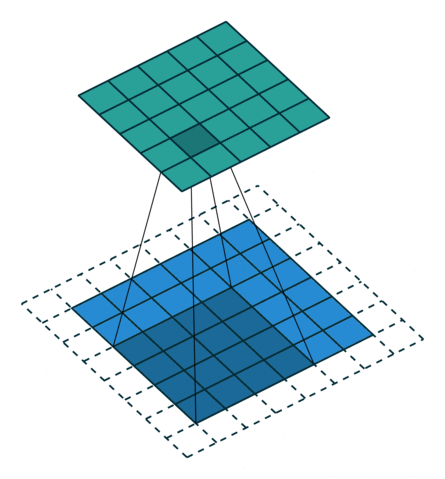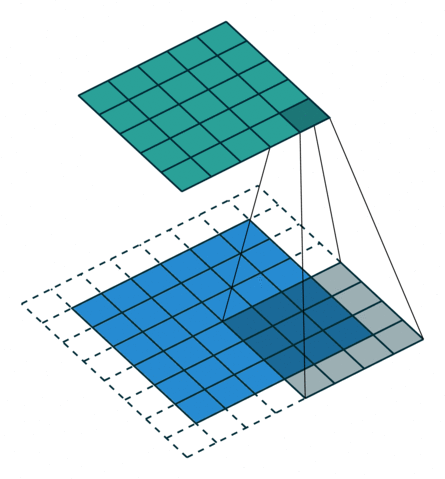

卷积的正向传播 = 反卷积的反向传播;卷积的反向传播 = 反卷积的正向传播加粗样式
从下往上就是卷积操作,从一个区域到一个点
比如
输入一维化
卷积操作:
