提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
前言
提示:这里可以添加本文要记录的大概内容:
例如:随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。
提示:以下是本篇文章正文内容,下面案例可供参考
一、DCGAN简介
DCGAN全称Deep Convolutional Generative Adversarial Networks,中文名曰深度卷积对抗网络。
论文地址
CNN即卷积网络,在DCGAN中,判别器实际上就是一个CNN网络,输入一张图片然后输出 yes or no 的概率。
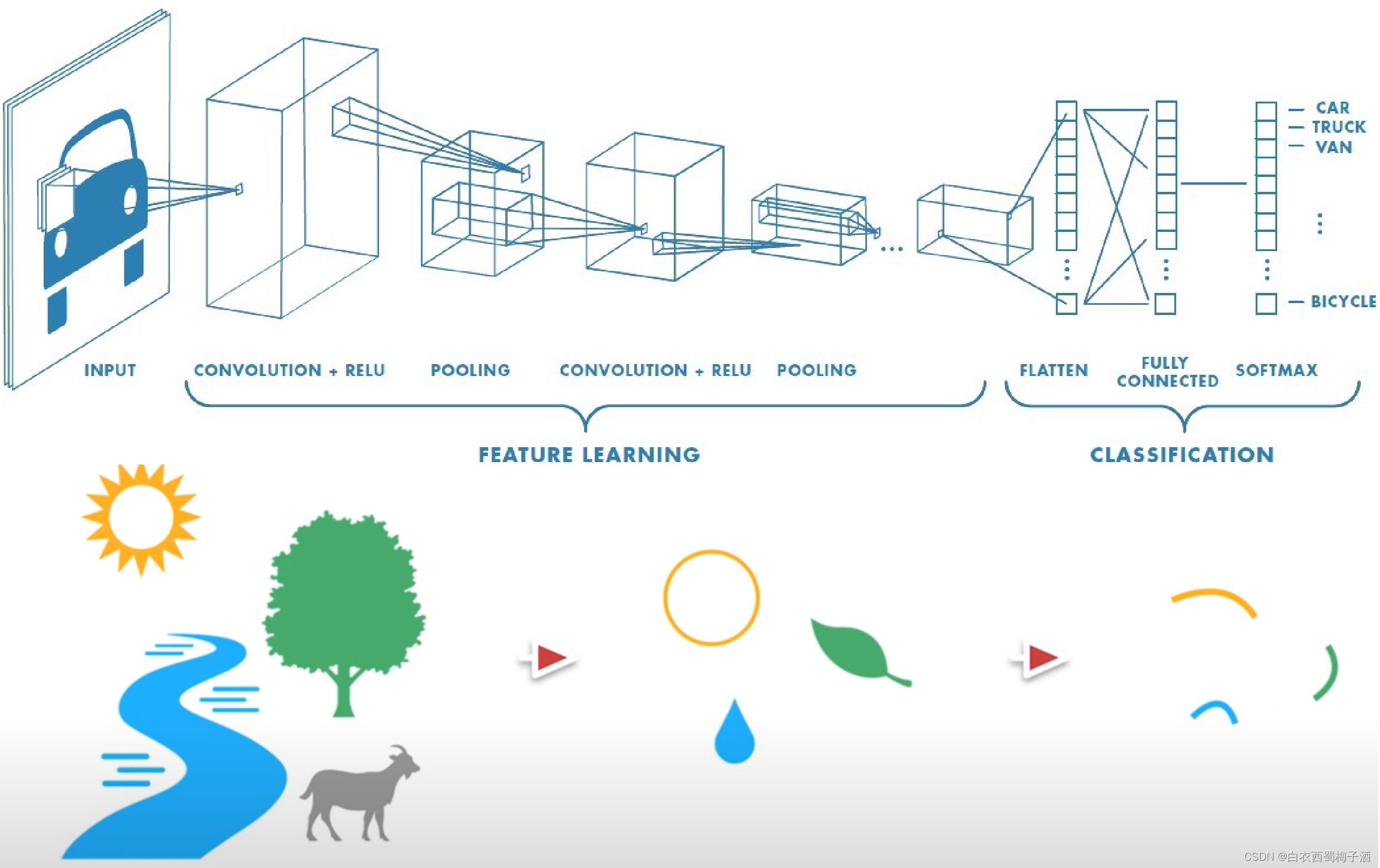
那么在DCGAN中,G网络的模型又是什么呢?
G网络刚好和CNN相反,它是由noise通过G网络生成一张图片,因为图片通过layer逐渐变大,这与卷积操作所造成的结果刚好相反,因此我们可以称之为反卷积。
1.1 DCGAN的特点
DCGAN除了G网络与CNN不同之外,它还有以下的不同:
1.取消所有pooling层。G网络中使用转置卷积(transposed convolutional layer)进行上采样,D网络中用加入stride的卷积代替pooling。
2.除了生成器模型的输出层和判别器模型的输入层,在网络其它层上都使用了Batch Normalization,使用BN可以稳定学习,有助于处理初始化不良导致的训练问题。
3.G网络中使用ReLu作为激活函数,最后一层使用tanh
4.D网络中使用LeakyRelu作为激活函数。
二、几个重要概念
2.1 下采样(SubSampled)
下采样实际上就是缩小图像,主要目的是为了使得图像符合显示区域的大小,生成对应图像的缩略图。比如说在CNN中得池化层或卷积层就是下采样。不过卷积过程导致的图像变小是为了提取特征,而池化下采样是为了降低特征的维度。
2.2 上采样(UpSampled)
有下采样也就必然有上采样,上采样实际上就是放大图像,指的是任何可以让图像变成更高分辨率的技术,这个时候我们也就能理解为什么在G网络中能够由噪声生成一张图片了。
它有反卷积(Deconvolution)、上池化(UnPooling)方法。这里我们只介绍反卷积,因为这是是我们需要用到的。
2.3反卷积(Deconvolution)
反卷积(Deconvolution)也称为分数步长的卷积和转置卷积(transposed convolution)。在下图中,左边的为卷积,右边的为反卷积。convolution过程是将4×4的图像映射为2×2的图像,而反卷积过程则是将2×2的图像映射为4×4的图像,两者的kernel size均为3。不过显而易见,反卷积只能恢复图片的尺寸大小,而不能准确的恢复图片的像素值(此时我们想一想,在CNN中,卷积层的kernel我们可以学习,那么在反卷积中的kernel我们是不是也可以学习呢?)。
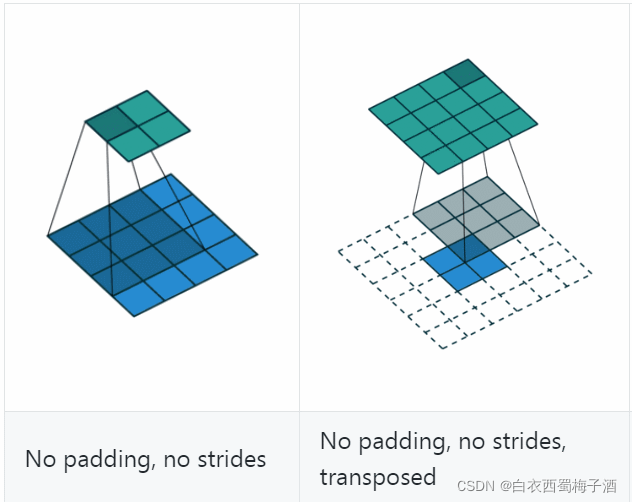
具体的转置卷积可以参看另一篇博客。

三、G模型
下图是GCGAN的大体框架图,在生成器中,使用反卷积生成图像,在判别器中使用卷积进行判别。

下图是在Deep Convolutional Generative Adversarial Networks论文中介绍的DCGAN生成器。该网络接收一个表示为z的100x1噪声矢量,通过一系列layer,最终将noise映射到64x64x3的图像中。
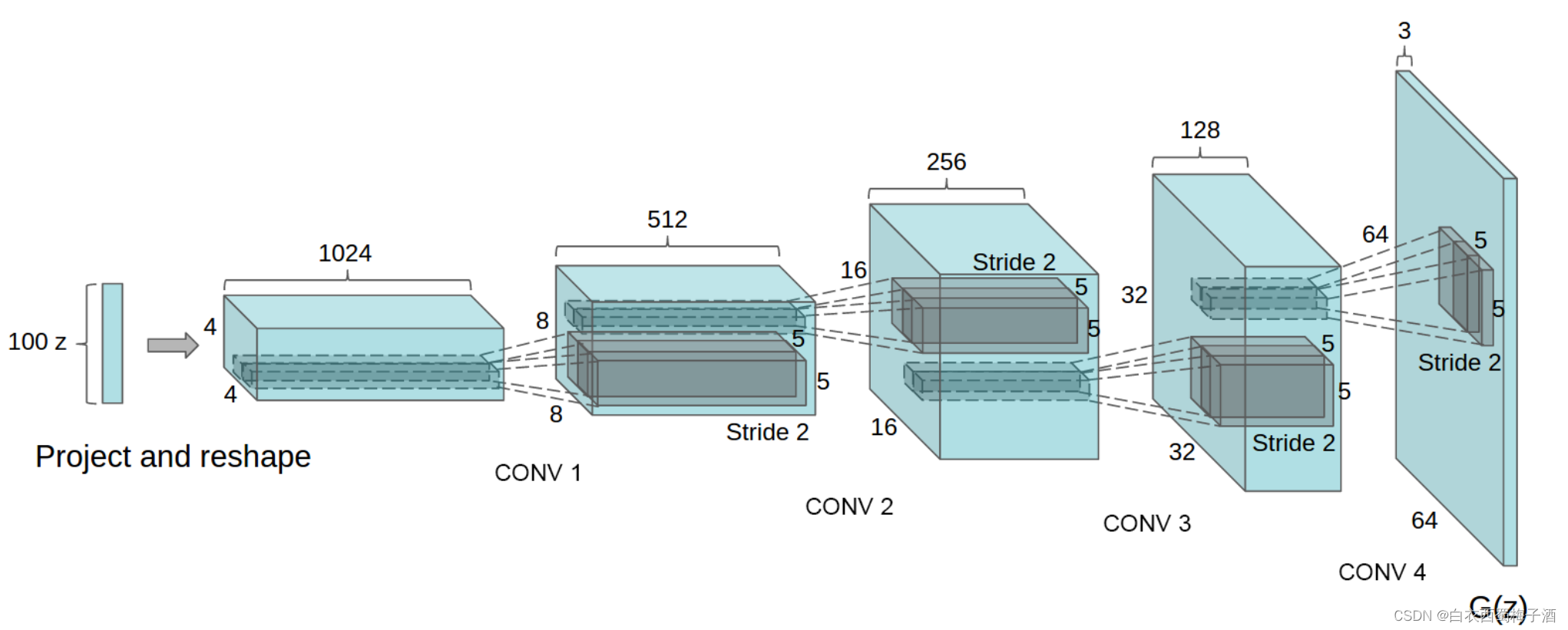
上述的过程实际上就是将一个1×100的向量变成64×64×3的图片。
1.Project and reshape:将1×100通过骚操作变成4×4×1024的向量。这里我们可以使用全连接层加卷积的方法。
2.CONV:反卷积
三、实现代码:
Generator:
import torch
import torch.nn as nn
from torch import Tensor
from typing import List
class Generator(nn.Module):
def __init__(self,in_channel:int,out_channel:int,kernel_size:List[int]=[5,5,5,5],padding:List[int]=[2,2,2,2],stride:List[int]=[2,2,2,2]):
super(Generator,self).__init__()
self.in_channel=in_channel
self.last_out_channel=out_channel
self.kernel_size=kernel_size
self.padding=padding
self.stride=stride
self.project_layer=nn.Linear(self.in_channel,1024*4*4)
self.in_channel=1024
self.main=self._make_layers(self.kernel_size,self.padding,self.stride)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.normal_(m.weight, 0.0, 0.02)
if isinstance(m,nn.BatchNorm2d):
nn.init.normal_(m.weight,1.0, 0.02)
def _make_layers(self,kernel_size:List[int],padding:List[int],stride:List[int]):
layers=[]
for i in range(len(kernel_size)-1):
self.out_channel=self.in_channel//2
layer=[nn.ConvTranspose2d(self.in_channel,self.out_channel,kernel_size[i],output_padding=1,padding=padding[i],stride=stride[i],bias=False),
nn.BatchNorm2d(self.out_channel),
nn.ReLU(inplace=True)
]
layers.extend(layer)
self.in_channel=self.out_channel
self.out_channel=self.in_channel//2
layers.extend([nn.ConvTranspose2d(self.in_channel,self.last_out_channel,kernel_size[i],output_padding=1,padding=padding[i],stride=stride[i]),
nn.Tanh()
])
return nn.Sequential(*layers)
def forward(self,inputs:Tensor):
batch_size=inputs.shape[0]
proj=self.project_layer(inputs)
reshape_proj=torch.reshape(proj,(batch_size,1024,4,4))
out=self.main(reshape_proj)
return out
if __name__=="__main__":
generator=Generator(100,3)
print(generator)
Discriminator
import torch
import torch.nn as nn
from torch import Tensor
from typing import List
class Discriminator(nn.Module):
def __init__(self,in_channel:int,last_out_channel:int,stride:List[int]=[2,2,2,2],padding:List[int]=[2,2,2,2],kernel_size:List[int]=[5,5,5,5]):
super(Discriminator,self).__init__()
self.main=self._make_layer(in_channel,last_out_channel,stride,padding,kernel_size)
self.fc1=nn.Linear(4*4*512,1)
self.sigmoid=nn.Sigmoid()
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.normal_(m.weight.data, 0.0, 0.02)
if isinstance(m, nn.BatchNorm2d):
nn.init.normal_(m.weight, 1.0, 0.02)
def _make_layer(self,in_channel,last_out_channel,stride:List[int],padding:List[int],kernel_size:List[int]):
layers=[]
for i in range(len(stride)-1):
out_channel=max(in_channel*2,64)
layer=[nn.Conv2d(in_channel,out_channel,kernel_size=kernel_size[i],padding=padding[i],stride=stride[i],bias=False),
nn.BatchNorm2d(out_channel),
nn.LeakyReLU(0.2,inplace=True),
]
in_channel=out_channel
layers.extend(layer)
layers.extend([nn.Conv2d(in_channel,last_out_channel,kernel_size=kernel_size[i],padding=padding[i],stride=stride[i]),
])
return nn.Sequential(*layers)
def forward(self,inputs:Tensor)->Tensor:
out=self.main(inputs)
out=torch.flatten(out,start_dim=1)
out=self.sigmoid(self.fc1(out))
return out
if __name__=="__main__":
fixed_noise = torch.randn(1,100)
NetD=Discriminator(3,last_out_channel=512)
print(NetD)
train脚本:
import torch
import torch.nn as nn
from data_set import MyDataset
from torch.utils.data import DataLoader
from torchvision import transforms
from tqdm import tqdm
from model.generater import Generator
from model.discriminator import Discriminator
def train(epochs:int=10,lr=2e-4):
real_label = 1
fake_label = 0
device="cuda:0" if torch.cuda.is_available() else "cpu"
my_transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
])
dataset = MyDataset(transform=my_transform)
train_loader = DataLoader(dataset, batch_size=32, shuffle=True)
NetD = Discriminator(3, last_out_channel=512).to(device)
NetG=Generator(100,3).to(device)
loss_func=nn.BCELoss()
optimizer_D=torch.optim.Adam(NetD.parameters(),lr=lr,betas=(0.5,0.999))
optimizer_G=torch.optim.Adam(NetG.parameters(),lr=lr,betas=(0.5,0.999))
for epoch in range(epochs):
train_bar=tqdm(train_loader)
for data in train_bar:
optimizer_D.zero_grad()
b_size = data.shape[0]
label = torch.full((b_size,), real_label,dtype=torch.float32).to(device)
# 分两步训练 是 ganhacks的建议
output = NetD(data.to(device)).view(-1).to(device)
loss_D_real=loss_func(output,label)
loss_D_real.backward()
noise = torch.randn(b_size,100).to(device)
fake=NetG(noise).to(device)
label.fill_(fake_label).to(device)
output = NetD(fake.detach()).view(-1)
loss_D_fake = loss_func(output, label)
loss_D_fake.backward()
loss_D_all=loss_D_real+loss_D_fake
optimizer_D.step()
NetG.zero_grad()
label.fill_(real_label)
output = NetD(fake).view(-1)
errG = loss_func(output, label)
errG.backward()
optimizer_G.step()
train_bar.desc = "train epoch[{}/{}] loss_D:{:.3f} loss_G:{:.3f}".format(epoch + 1,
epochs,
loss_D_all,errG)
if __name__=="__main__":
train()