一.主题式网络爬虫设计方案
1.主题式网络爬虫名称:国家数据网不同年份的人口比率
2.主题式网络爬虫爬取的内容:人口出生率死亡率及自然增长率
3.设计方案概述:
实现思路:爬取网站内容,之后分析提取需要的数据,进行数据清洗,之后数据可视化,并计算不同比率的相关系数
技术难点:因为用的是json分析,所以需要通过查找的方式获取数据,以及后面的3D模型图需要将整数转成浮点数
二、主题页面的结构特征分析
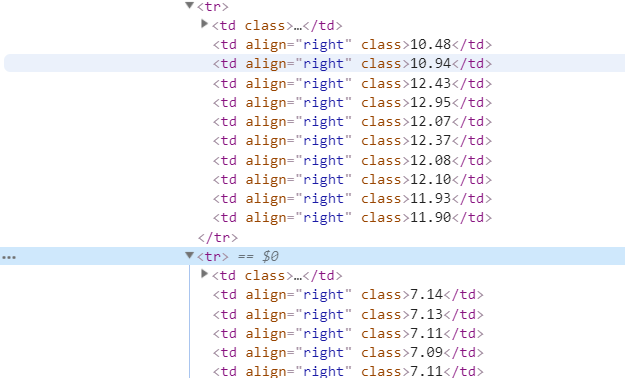
1.主题页面的结构与特征分析:打开开发者工具,通过逐个查找找到需要数据的所在位置,发现所需要的数据都在<tbody>
下的<tr>中
2.
3.
三、网络爬虫程序设计
1.数据爬取与采集
import matplotlib.pyplot as plt import numpy as np import matplotlib from mpl_toolkits.mplot3d import Axes3D import seaborn as sns import pickle
matplotlib.rcParams['font.sans-serif']=['SimHei'] # 用黑体显示中文 matplotlib.rcParams['axes.unicode_minus']=False # 正常显示负号 dfwds = '[{"wdcode": "sj", "valuecode": "LAST21"}, {"wdcode":"zb","valuecode":"A0302"}]' #网址的dfwds为上面所写的,以便更快的获取需要的数据 url='http://data.stats.gov.cn/easyquery.htm?m=QueryData&dbcode=hgnd&rowcode=sj&colcode=zb&wds=[]&dfwds={}' #获取url response = requests.get(url.format(dfwds)) #获取网页的数据 z=response.json() #获取网址的json z=z['returndata'] #通过字典的key值,获取数据
z=z['datanodes'] print(z)
获取dfwds和url

2.对数据进行清洗和处理
birth_rate={} #分别设置三个字典,用来装后面的值
death_rate={}
natural_growth_rate={}
for i in range(len(z)//3): #通过循环,获取结果
#print("年份{}:出生率{}".format(z[i]['wds'][1]['valuecode'],z[i]['data']['data']))
birth_rate[z[i]['wds'][1]['valuecode']]=z[i]['data']['data']
#print(birth_rate)
for i in range(len(z)//3,len(z)//3*2):
#print("年份{}:死亡率{}".format(z[i]['wds'][1]['valuecode'],z[i]['data']['data']))
death_rate[z[i]['wds'][1]['valuecode']]=z[i]['data']['data']
#print(death_rate)
for i in range(len(z)//3*2,len(z)):
#print("年份{}:自然增长率{}".format(z[i]['wds'][1]['valuecode'],z[i]['data']['data']))
natural_growth_rate[z[i]['wds'][1]['valuecode']]=z[i]['data']['data']
#print(natural_growth_rate)
years=list(birth_rate.keys()) #把字典里面的key和value都拿出来,分别转成列表类型
rate1=list(birth_rate.values())
rate2=list(death_rate.values())
rate3=list(natural_growth_rate.values())
d={'出生率 ':rate1, #将数值带入
'死亡率 ':rate2,
'自然增长率 ':rate3}
df=pd.DataFrame(d,index=years) #将年份和比率结合一起
print(df) #输出结果
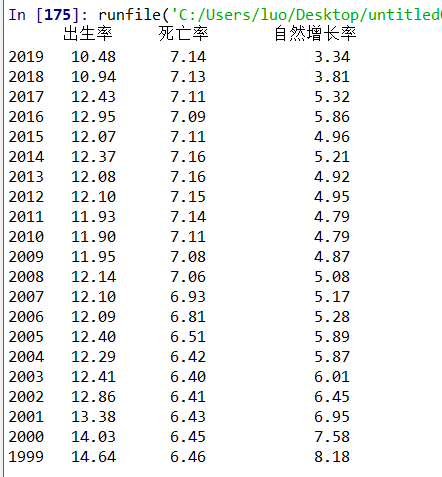
3.文本分析(可选):因为都是数字,所以这里没有用到文本分析
4.数据分析与可视化:
(1)折线图
years=years[::-1] #因为后面用到的数据都是从左到右年份逐渐增大,所以数据全部都需要倒一下 rate1=rate1[::-1] rate2=rate2[::-1] rate3=rate3[::-1] #print(years) #绘制折线图 x=years #设置x轴 plt.figure(figsize=(12,8),dpi=80) #设置绘制的图像和字体大小 plt.plot(x,rate1,color = 'r',label="birth_rate")#r是红色 plt.plot(x,rate2,color = 'y',label="death_rate")#k是黄色 plt.plot(x,rate3,color = 'b',label="natural_growth_rate")#b是蓝色 plt.xlabel("year")#横坐标名字 plt.ylabel("rate")#纵坐标名字 plt.legend(loc = "best")#图例 plt.show()

(2)柱状图
#绘制柱状图 plt.figure(figsize=(12,8),dpi=80) #设置绘制的图像和字体大小 x = np.arange(21) #总共有几组,就设置成几,我们这里有21组,所以设置为21 total_width, n = 0.8, 3 # 有多少个类型,只需更改n即可,比如这里我们对比了3个,那么就把n设成3 width = total_width / n x = x - (total_width - width) / 2 plt.bar(x, rate1, color = "r",width=width,label='birth_rate') plt.bar(x + width, rate2, color = "y",width=width,label='death_rate') plt.bar(x + 2 * width,rate3 , color = "c",width=width,label='natural_growth_rate') plt.xlabel("year") plt.ylabel("rate") plt.legend(loc = "best") plt.xticks([0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21],years) #这里之所以一个个打,因为快一点 my_y_ticks = np.arange(0, 20, 2) plt.ylim((0, 20)) plt.yticks(my_y_ticks) plt.show()
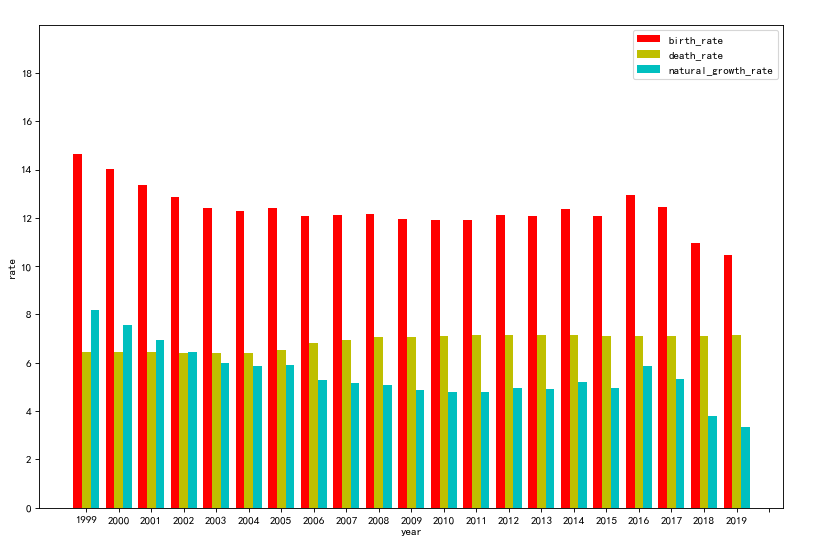
(3)直方图
#绘制直方图 plt.figure(figsize=(12,8),dpi=80) plt.hist(rate1,bins=40, normed=0, facecolor="blue", edgecolor="blue", alpha=0.7) #bins是直方图的长条形数目 plt.hist(rate2,bins=40, normed=0, facecolor="yellow", edgecolor="yellow", alpha=0.7) #normed是否将得到的直方图向量归一化 plt.hist(rate3,bins=40, normed=0, facecolor="green", edgecolor="green", alpha=0.7) plt.xlabel("比率") plt.ylabel("总数") plt.title("人口比率直方图") plt.show() #蓝色是出生率,黄色是死亡率,绿色是自然增长率

(4)堆叠条形图
#绘制堆叠条形图 plt.figure(figsize=(12,8),dpi=80) x=range(len(rate1)) rects1 = plt.bar(x,height=rate1, width=0.45, alpha=0.8, color='red', label="出生率") rects2 = plt.bar(x,height=rate2, width=0.45, color='green', label="死亡率") #x表示条数 height表示高度 plt.ylim(0, 20) plt.ylabel("比率") plt.xticks(x, years) plt.xlabel("年份") plt.title("人口出生率与死亡率对比") plt.legend() plt.show()

(5)横向柱状图
#绘制横向的柱状图 plt.figure(figsize=(12,8),dpi=80) a=0.3 #设置分开的间隔 index = np.arange(1999,2020) plt.barh(index,rate1, a, color = 'brown', label = 'birth_rate') plt.barh(index+a, rate2, a, color = 'pink', label = 'death_rate') plt.barh(index+2*a, rate3, a, color = 'orange',label = 'natural_growth_rate') plt.legend()
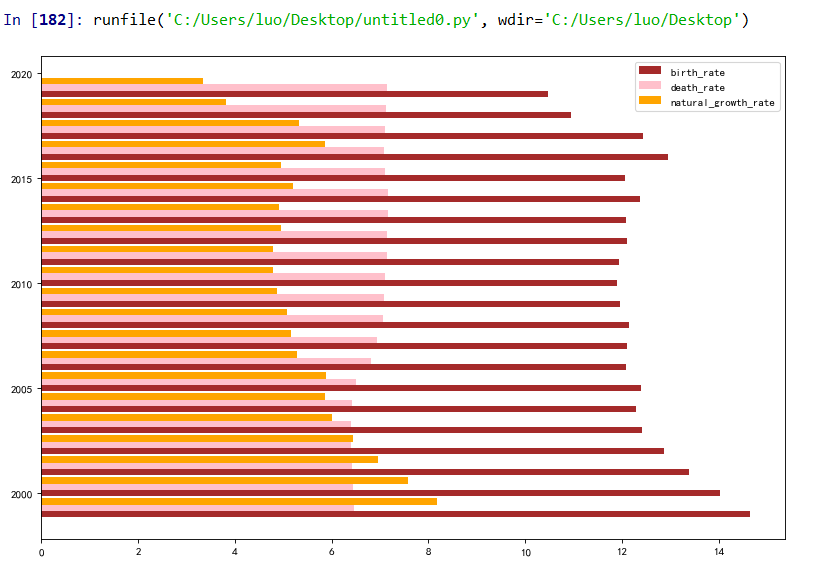
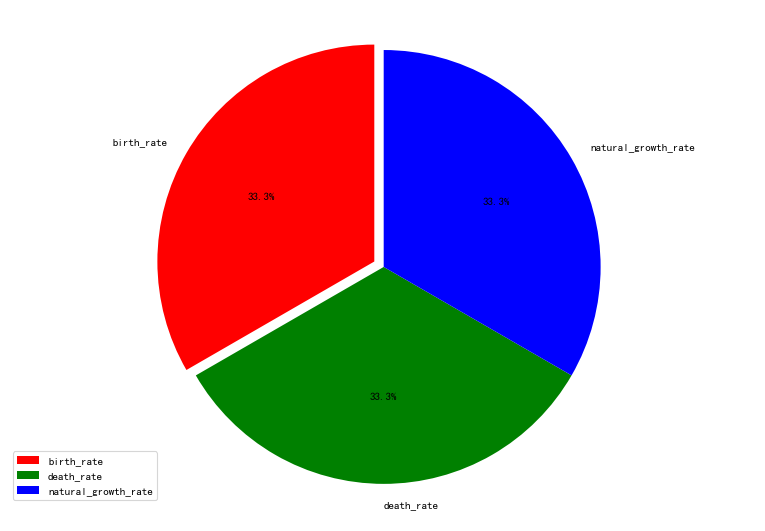
(6)饼图
#绘制饼图 plt.figure(figsize=(12,8),dpi=80) label_list = ["birth_rate", "death_rate", "natural_growth_rate"] # 各部分标签 size = [33, 33, 33] # 各部分大小 color = ["red", "green", "blue"] explode = [0.05, 0, 0] # 各部分突出值 patches, l_text, p_text = plt.pie(size, explode=explode, colors=color,\ labels=label_list, labeldistance=1.1,\ autopct="%1.1f%%", shadow=False, startangle=90, pctdistance=0.6) plt.axis("equal") # 设置横轴和纵轴大小相等,这样饼才是圆的 plt.legend() plt.show() #因为年份,出现的次数都是相等,所以这个图三部分都一样
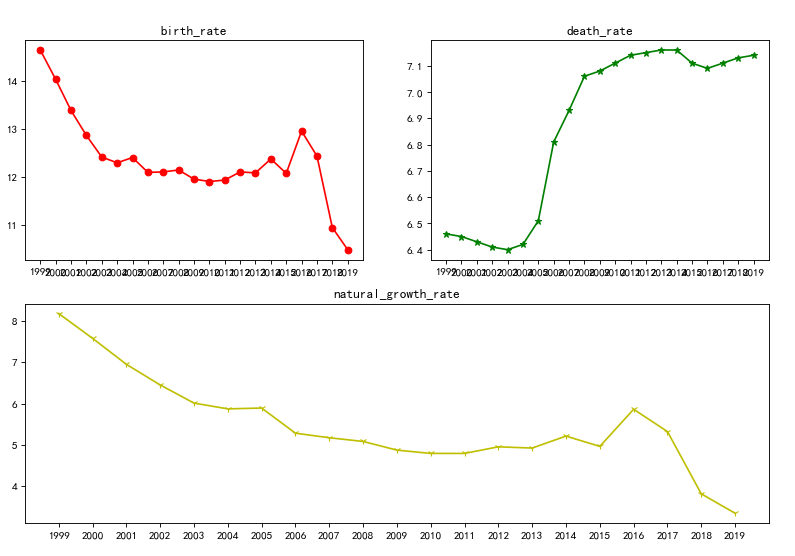
(7)子图
#绘制子图 plt.figure(figsize=(12,8),dpi=80) # 创建figure对象 # 绘制子图1 axes1 = plt.subplot(2,2,1) plt.plot(years,rate1,'r-o') plt.title('birth_rate') # 绘制子图2 axes2 = plt.subplot(2,2,2) plt.plot(years,rate2,'g-*') plt.title('death_rate') # 绘制子图3 axes3 = plt.subplot(2,1,2) plt.plot(years,rate3,'y-1') plt.title('natural_growth_rate')
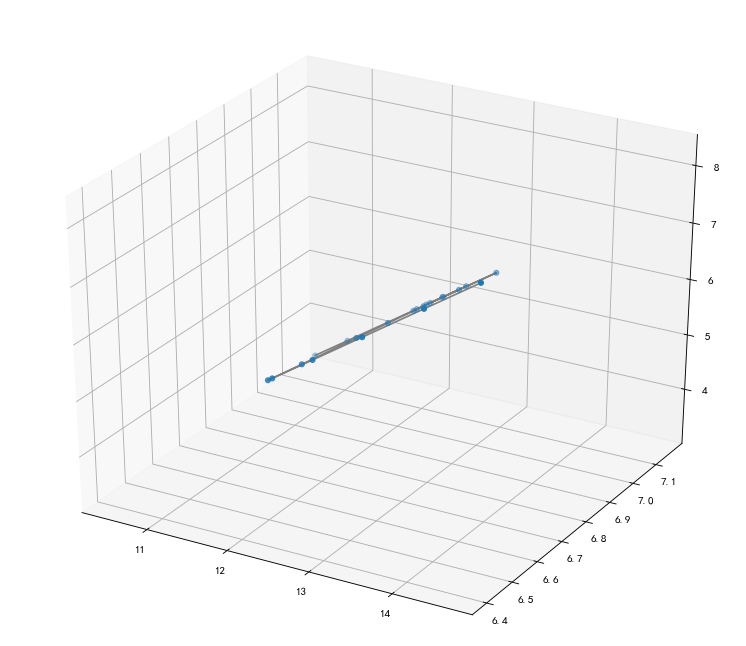
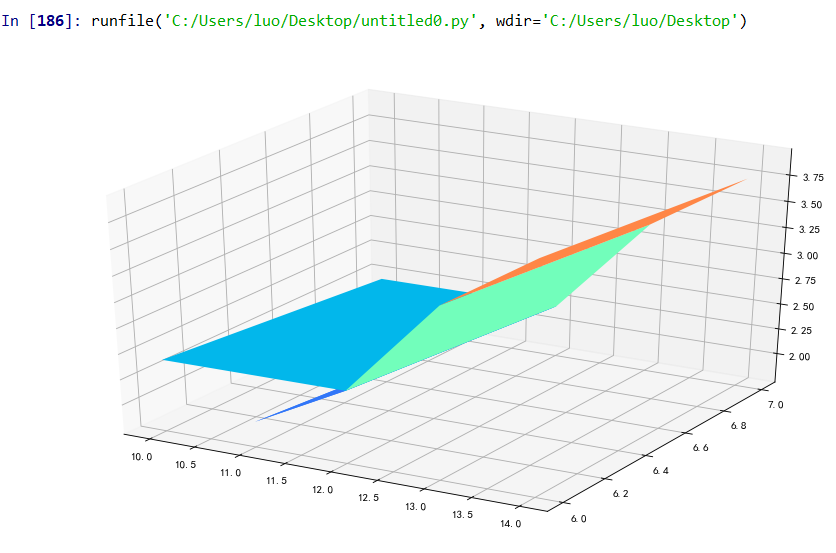
(8)三维图
#绘制3D图 fig=plt.figure(figsize=(10,8),dpi=80) ax = Axes3D(fig) ax.scatter3D(rate1,rate2,rate3, cmap='Blues') #绘制散点图 ax.plot3D(rate1,rate2,rate3,'gray') #绘制空间曲线 #因为人口的出生率死亡率和自然增长率都极为接近,所以结果看着像一条直线 plt.show()
(9)三维曲面图
#绘制三维曲面 fig = plt.figure(figsize=(14,8),dpi=80) #定义新的三维坐标轴 ax3 = plt.axes(projection='3d') ratel1=[] ratel2=[] ratel3=[] for i in rate1: #这里因为不是整数就运行不了,所以将浮点数类型变成整数类型 ratel1.append(int(i)) for i in rate2: ratel2.append(int(i)) for i in rate3: ratel3.append(int(i)) xx = ratel1 #这样能更清晰的知道X,Y,Z轴 yy = ratel2 zz = ratel3 X, Y = np.meshgrid(xx, yy) Z = np.sin(X)+np.cos(Y) +2 ax3.plot_surface(X,Y,Z,cmap='rainbow') #x代表出生率,y代表死亡率,z代表自然增长率 plt.show()
5.根据数据之间的关系,分析两个变量之间的相关系数,画出散点图,并建立变量之间的回归方程
(1)年份与出生率
#年份与出生率之间的相关系数,以及散点图 yearl=[] years=years[::-1] #因为df出生率是正的,而之前年份倒过来过,所以这里需要倒一次 for i in years: yearl.append(float(i)) year = pd.Series(yearl) #利用Series将列表转换成新的、pandas可处理的数据 birth_rate = pd.Series(rate1) corr_gust = round(year.corr(birth_rate), 4) #计算标准差,round(a, 4)是保留a的前四位小数 print('年份与出生率之间的相关系数:', corr_gust) plt.figure(figsize=(12,8),dpi=80) sns.stripplot(x =years,y = '出生率 ',data = df)

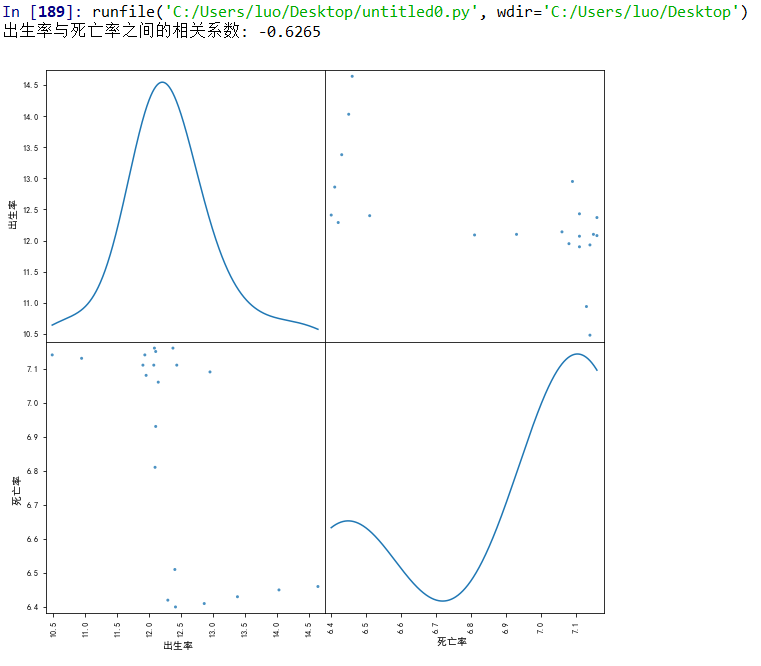
(2)出生率与死亡率
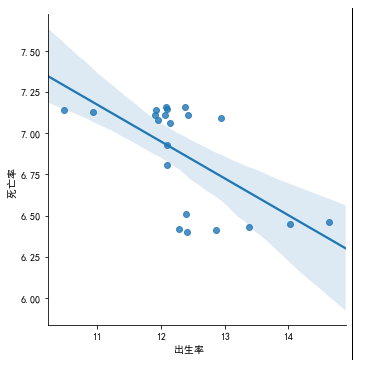
#出生率与死亡率之间的相关系数,以及散点图 birth_rate=pd.Series(rate1) death_rate=pd.Series(rate2) corr_gust = round(birth_rate.corr(death_rate), 4) print('出生率与死亡率之间的相关系数:', corr_gust) y=df[["出生率 "]] x=df[["死亡率 "]] pd.plotting.scatter_matrix( df[["出生率 ", "死亡率 "]], alpha=0.8, figsize=(10, 10), diagonal='kde' ) plt.show() #建立出生率与死亡率的一元非线性回归方程以及图示 df1=df[["出生率 ","死亡率 "]] sns.lmplot(x="出生率 ",y="死亡率 ",data=df1)
6.数据持久化
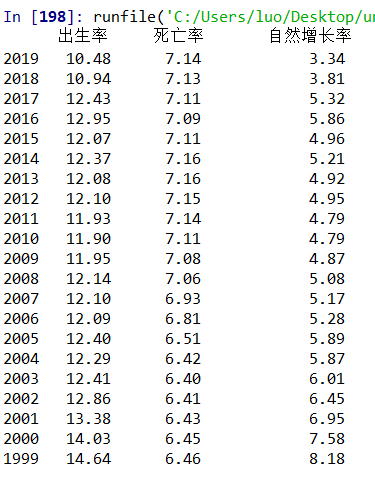
f1 = open('pickle.txt','wb') #建立一个文件,以二进制形式 pickle.dump(df,f1) # pickle.dump(obj, file, [,protocol]) file为对象保存到的类文件对象 f1.flush() #flush是用来刷新缓冲区的 f1.close() read_file = open('pickle.txt','rb') data = pickle.load(read_file) #从read_file(文件对象)中读取一个字符串,并将它重构为原来的python对象。 print(data) read_file.close()

7.将以上各部分的代码汇总,附上完整程序代码
import requests import pandas as pd import json import matplotlib.pyplot as plt import numpy as np import matplotlib from mpl_toolkits.mplot3d import Axes3D import seaborn as sns import pickle matplotlib.rcParams['font.sans-serif']=['SimHei'] # 用黑体显示中文 matplotlib.rcParams['axes.unicode_minus']=False # 正常显示负号 dfwds = '[{"wdcode": "sj", "valuecode": "LAST21"}, {"wdcode":"zb","valuecode":"A0302"}]' #网址的dfwds为上面所写的,所以更快的获取要的数据 url='http://data.stats.gov.cn/easyquery.htm?m=QueryData&dbcode=hgnd&rowcode=sj&colcode=zb&wds=[]&dfwds={}' #获取url response = requests.get(url.format(dfwds)) #获取网页的数据 z=response.json() #获取网址的json z=z['returndata'] #通过字典的key值,获取数据 z=z['datanodes'] #print(z) birth_rate={} #分别设置三个字典,用来装后面的值 death_rate={} natural_growth_rate={} for i in range(len(z)//3): #通过循环,获取结果 #print("年份{}:出生率{}".format(z[i]['wds'][1]['valuecode'],z[i]['data']['data'])) birth_rate[z[i]['wds'][1]['valuecode']]=z[i]['data']['data'] #print(birth_rate) for i in range(len(z)//3,len(z)//3*2): #print("年份{}:死亡率{}".format(z[i]['wds'][1]['valuecode'],z[i]['data']['data'])) death_rate[z[i]['wds'][1]['valuecode']]=z[i]['data']['data'] #print(death_rate) for i in range(len(z)//3*2,len(z)): #print("年份{}:自然增长率{}".format(z[i]['wds'][1]['valuecode'],z[i]['data']['data'])) natural_growth_rate[z[i]['wds'][1]['valuecode']]=z[i]['data']['data'] #print(natural_growth_rate) years=list(birth_rate.keys()) #把字典里面的key和value都拿出来,分别转成列表类型 rate1=list(birth_rate.values()) rate2=list(death_rate.values()) rate3=list(natural_growth_rate.values()) d={'出生率 ':rate1, #将数值带入 '死亡率 ':rate2, '自然增长率 ':rate3} df=pd.DataFrame(d,index=years) #将年份和比率结合一起 f1 = open('pickle.txt','wb') pickle.dump(df,f1) f1.flush() f1.close() read_file = open('pickle.txt','rb') data = pickle.load(read_file) #print(data) read_file.close() #print(df) #输出结果 years=years[::-1] #因为后面用到的数据都是从左到右年份逐渐增大,所以数据全部都需要倒一下 rate1=rate1[::-1] rate2=rate2[::-1] rate3=rate3[::-1] #print(years) #绘制折线图 x=years #设置x轴 plt.figure(figsize=(12,8),dpi=80) #设置绘制的图像和字体大小 plt.plot(x,rate1,color = 'r',label="birth_rate")#r是红色 plt.plot(x,rate2,color = 'y',label="death_rate")#k是黄色 plt.plot(x,rate3,color = 'b',label="natural_growth_rate")#b是蓝色 plt.xlabel("year")#横坐标名字 plt.ylabel("rate")#纵坐标名字 plt.legend(loc = "best")#图例 plt.show() #绘制柱状图 plt.figure(figsize=(12,8),dpi=80) #设置绘制的图像和字体大小 x = np.arange(21) #总共有几组,就设置成几,我们这里有21组,所以设置为21 total_width, n = 0.8, 3 # 有多少个类型,只需更改n即可,比如这里我们对比了3个,那么就把n设成3 width = total_width / n x = x - (total_width - width) / 2 plt.bar(x, rate1, color = "r",width=width,label='birth_rate') plt.bar(x + width, rate2, color = "y",width=width,label='death_rate') plt.bar(x + 2 * width,rate3 , color = "c",width=width,label='natural_growth_rate') plt.xlabel("year") plt.ylabel("rate") plt.legend(loc = "best") plt.xticks([0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21],years) #这里之所以一个个打,因为快一点 my_y_ticks = np.arange(0, 20, 2) plt.ylim((0, 20)) plt.yticks(my_y_ticks) plt.show() #绘制直方图 plt.figure(figsize=(12,8),dpi=80) plt.hist(rate1,bins=40, normed=0, facecolor="blue", edgecolor="blue", alpha=0.7) #bins是直方图的长条形数目 plt.hist(rate2,bins=40, normed=0, facecolor="yellow", edgecolor="yellow", alpha=0.7) #normed是否将得到的直方图向量归一化 plt.hist(rate3,bins=40, normed=0, facecolor="green", edgecolor="green", alpha=0.7) plt.xlabel("比率") plt.ylabel("总数") plt.title("人口比率直方图") plt.show() #蓝色是出生率,黄色是死亡率,绿色是自然增长率 ' #绘制堆叠条形图 plt.figure(figsize=(12,8),dpi=80) x=range(len(rate1)) rects1 = plt.bar(x,height=rate1, width=0.45, alpha=0.8, color='red', label="出生率") rects2 = plt.bar(x,height=rate2, width=0.45, color='green', label="死亡率") #x表示条数 height表示高度 plt.ylim(0, 20) plt.ylabel("比率") plt.xticks(x, years) plt.xlabel("年份") plt.title("人口出生率与死亡率对比") plt.legend() plt.show() #绘制横向的柱状图 plt.figure(figsize=(12,8),dpi=80) a=0.3 #设置分开的间隔 index = np.arange(1999,2020) plt.barh(index,rate1, a, color = 'brown', label = 'birth_rate') plt.barh(index+a, rate2, a, color = 'pink', label = 'death_rate') plt.barh(index+2*a, rate3, a, color = 'orange',label = 'natural_growth_rate') plt.legend() #绘制饼图 plt.figure(figsize=(12,8),dpi=80) label_list = ["birth_rate", "death_rate", "natural_growth_rate"] # 各部分标签 size = [33, 33, 33] # 各部分大小 color = ["red", "green", "blue"] explode = [0.05, 0, 0] # 各部分突出值 patches, l_text, p_text = plt.pie(size, explode=explode, colors=color,\ labels=label_list, labeldistance=1.1,\ autopct="%1.1f%%", shadow=False, startangle=90, pctdistance=0.6) plt.axis("equal") # 设置横轴和纵轴大小相等,这样饼才是圆的 plt.legend() plt.show() #因为年份,出现的次数都是相等,所以这个图三部分都一样 #绘制子图 plt.figure(figsize=(12,8),dpi=80) # 创建figure对象 # 绘制子图1 axes1 = plt.subplot(2,2,1) plt.plot(years,rate1,'r-o') plt.title('birth_rate') # 绘制子图2 axes2 = plt.subplot(2,2,2) plt.plot(years,rate2,'g-*') plt.title('death_rate') # 绘制子图3 axes3 = plt.subplot(2,1,2) plt.plot(years,rate3,'y-1') plt.title('natural_growth_rate') #绘制3D图 fig=plt.figure(figsize=(10,8),dpi=80) ax = Axes3D(fig) ax.scatter3D(rate1,rate2,rate3, cmap='Blues') #绘制散点图 ax.plot3D(rate1,rate2,rate3,'gray') #绘制空间曲线 #因为人口的出生率死亡率和自然增长率都极为接近,所以结果看着像一条直线 plt.show() #绘制三维曲面 fig = plt.figure(figsize=(14,8),dpi=80) #定义新的三维坐标轴 ax3 = plt.axes(projection='3d') ratel1=[] ratel2=[] ratel3=[] for i in rate1: #这里因为不是整数就运行不了,所以将浮点数类型变成整数类型 ratel1.append(int(i)) for i in rate2: ratel2.append(int(i)) for i in rate3: ratel3.append(int(i)) xx = ratel1 #这样能更清晰的知道X,Y,Z轴 yy = ratel2 zz = ratel3 X, Y = np.meshgrid(xx, yy) Z = np.sin(X)+np.cos(Y) +2 ax3.plot_surface(X,Y,Z,cmap='rainbow') #x代表出生率,y代表死亡率,z代表自然增长率 plt.show() #年份与出生率之间的相关系数,以及散点图 yearl=[] years=years[::-1] #因为df出生率是正的,而之前年份倒过来过,所以这里需要倒一次 for i in years: yearl.append(float(i)) year = pd.Series(yearl) #利用Series将列表转换成新的、pandas可处理的数据 birth_rate = pd.Series(rate1) corr_gust = round(year.corr(birth_rate), 4) #计算标准差,round(a, 4)是保留a的前四位小数 print('年份与出生率之间的相关系数:', corr_gust) plt.figure(figsize=(12,8),dpi=80) sns.stripplot(x =years,y = '出生率 ',data = df) #出生率与死亡率之间的相关系数,以及散点图 birth_rate=pd.Series(rate1) death_rate=pd.Series(rate2) corr_gust = round(birth_rate.corr(death_rate), 4) print('出生率与死亡率之间的相关系数:', corr_gust) y=df[["出生率 "]] x=df[["死亡率 "]] pd.plotting.scatter_matrix( df[["出生率 ", "死亡率 "]], alpha=0.8, figsize=(10, 10), diagonal='kde' ) plt.show() #建立出生率与死亡率的一元非线性回归方程以及图示 df1=df[["出生率 ","死亡率 "]] sns.lmplot(x="出生率 ",y="死亡率 ",data=df1)
四、结论
1.经过对主题数据的分析与可视化得到的结论:通过对数据的分析以及可视化可以看出,近几十年来我国的出生率逐渐降低,死亡率逐渐升高,自然增长率也因此逐年下降
2.对本次程序设计任务完成的情况做一个简单的小结:通过这次爬虫,然后对数据的分析可视化等,让我了解到了数据的多种用途,
以及可以通过图像的方式显示出来,和不同数据之间的相关性等,让我学到了很多