- Ian H. Witten - Department of Computer Science University of Waikato New Zealand
https://www.youtube.com/user/WekaMOOC/playlist

- https://www.cs.waikato.ac.nz/ml/weka/
- https://waikato.github.io/weka-wiki/datasets/
- Getting Started with Weka - Machine Learning Recipes
文章目录
- Data Mining with Weka
- 1.1 Introduction
- 1.2 Exploring the Explorer
- 1.3 Exploring datasets
- 1.4 Building a classifier
- 1.5 Using a filter
- 1.6 Visualizing your data
- 2.1 Be a classifier
- 2.2 Training and testing
- 2.3 Repeated training and testing
- 2.4 Baseline accuracy
- 2.5 Cross-validation
- 2.6 Cross-validation results
- 3.1 Simplicity first
- 3.2 Overfitting
- 3.3 Using probabilities
- 3.4 Decision trees
- 3.5 Pruning decision trees
- 3.6 Nearest neighbor
- 4.1 Classification boundaries
- 4.2-4.6 Linear Regression......
- 5.1 The data mining process
- 5.2-5.4 Summary......
Data Mining with Weka
1.1 Introduction
Data Mining with Weka MOOC - Material
Weka是新西兰特有的 物种,它是一种不会飞的小鸟
Waikato Environment for Knowledge Analysis (Weka)是数据挖掘的工具包
Weka是基于Java写出来的
要学习只听讲是不够的,还得动手去做
1.2 Exploring the Explorer
- Preprocess 预处理面板
- Classify 分类面板(用于对数据的分类)
- Cluster 聚类面板(用于对数据的聚类)
- Associate 关联规则
- Select attributes 特征选择
- Visualize 可视化面板


1.3 Exploring datasets
在weka中,默认的类是最后一个属性
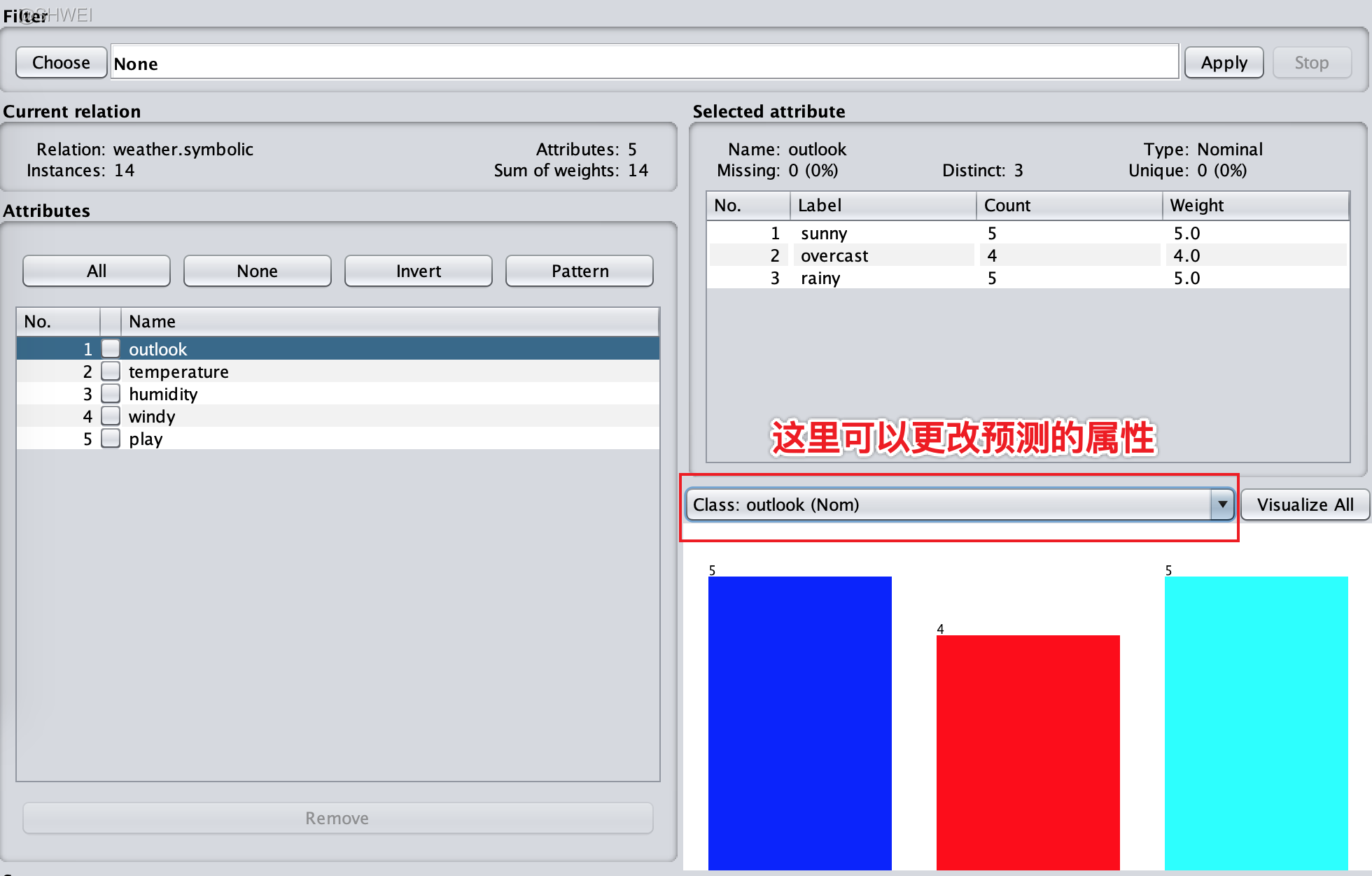


nominal: 名词性
numeric: 数字性
1.4 Building a classifier
Weka提供了多种分类器,例如贝叶斯分类器、函数分类器、懒惰分类器、元分类器、决策树分类器等



决策树的可视化


1.5 Using a filter
过滤器:
Filters can be very powerful 合适的过滤可以提高分类的准确度并且使分类结果更加清晰
Undo撤销
Save保存过滤的数据集
(1) 选择 unsupervised learning 中的Remove,选择下标3删除原来的Humidity属性

(2) 删除所有Humidity属性为high的实例
选择unsupervised learning/instance/RemoveWithValues

(3) 删除某些属性可能提高分类算法的分类准确率
例如glass数据集,我删除特征Fe和Si,再用分类算法J48,得到的分类准确率比原来要高

1.6 Visualizing your data
Visualize显示的是你当前文件给的数据的属性可视化图形,这是已知的数据,不同的颜色是根据已知不同数据所属的class来标记的(所以这个可视化图在你使用分类算法前已经有了)
对监督学习的理解:
我们已知的数据是取自无限总体的独立样本,那如果我根据这些有限的数据去预测未知数据,那必然会有一定误差,比如下图,你假设一个菱形区域(这其实就是分类算法得到的区域)把红色的实例全包起来,然后你说对于一个未知的数据只要是在这个菱形区域内的那我就认为它是红色的,这就是机器学习
而现实中可能所有红色的实例包起来是一个圆形或不规则区域,那我们在预测中势必有一定的误差


有时候,多个点叠加在同一个位置(因为有些实例的当前两个属性可能完全相同),通过抖动可以给 轴和 轴增加点的随机性
抖动(jitter)滑块可以帮助你区分实际位置特别近的点
运行分类算法后,右键选择Visualize classifier errors可以查看误差


2.1 Be a classifier
用户分类器UserClassifier
根据可视化结果,尝试实例空间的不同区域,找纯度最高的区域来建立纯度最高的分支,这种是自底向上的做法
而J48分类器则不是基于这样一个策略的,它是每次将数据集一分为二,自顶向下,将每次剩下的一般数据建成最优化的树形,它所创建的树比我们刚刚用用户分类器所建的要好
2.2 Training and testing
使用不同的测试数据和训练数据是十分重要的,因为只有这样,你才能得到可信的评估结果
拿到一个数据集我们一般会把它分成两部分,训练集(Training)和测试集(Testing),训练集和测试集都是分别取自无限总体的独立样本,并且他们是不同的数据

使用segment-test.arff测试集,并用J48分类器对这些数据进行预测,可以发现这个分类器的准确度为97.4074%
| A | 实例数 | C |
|---|---|---|
| Correctly Classified Instances | 789 | 97.4074 % |
| Incorrectly Classified Instances | 21 | 2.5926 % |
Test Options-Percentage Split 按比例划分当前打开的数据集,为训练集和测试集,这里是9比1
显示的结果是测试集的预测结果,测试集中有一个实例预测错误
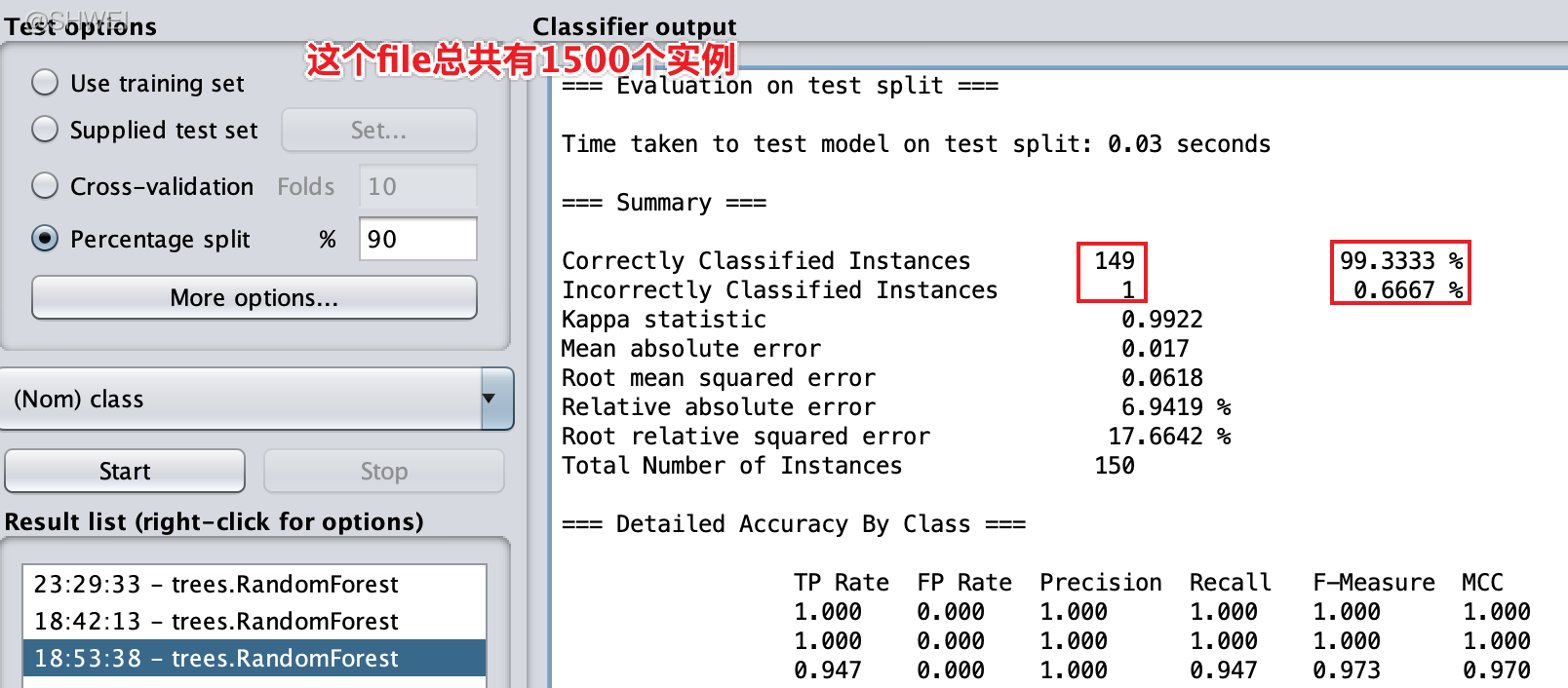
相同的分隔比例会得到同样的结果,那是因为Weka初始化了随机生成器,这主要是为了保证你明天做这个实验时得到的还是相同的结果
注:一般不建议用training set去做测试,因为这会带来比较大的误差
2.3 Repeated training and testing
通过设置不同的seed,使同一个划分比例,能来生成多个结果,然后我们再取平均值,方差和标准差,使得实验结果更加可靠
平均值 Mean
方差 Variance
标准差 Standard deviation

2.4 Baseline accuracy
基线准确度
尝试不同的分类器
- trees.J48 75.3%
- rules.PART 75.3%
- bayes.NaiveBayes 77.9%
- lazy.IBk 79.2%

- rules.ZeroR(使用training set即可) 总是猜测是这个分类,正确率为500/768 65.1%

这里基准精确度就是65%
Sometimes baseline is best. For example, the dataset supermarket.arff
这是因为这个数据集的属性并不是分类的依据,所以不要盲目地用Weka分析任意的数据

所以在尝试复杂分类器之前先尝试一下最简单的分类器
2.5 Cross-validation
Cross-validation交叉验证可以降低评估误差
Repeated holdout 重复预留法(2.3)
选择9:1的训练集和测试集的比例,然后更改种子,重复10次
交叉验证原理:
在交叉验证中,我们只分割一次,但是我们分成10份,然后用其中的9份作为训练集,剩余的一份作为测试集,接着还是用之前分隔好的数据,我们再选择另外的一组9份作为训练数据,剩余的一份作为测试集,我们这样重复10次,每次都是用分割出的不同的数据作为测试集。最后取这十次结果的平均,这就是10层交叉验证
Test option > Cross-validation Folds 10


最实用的原则:
- 如果你有足够多的数据,你可以用百分比分割数据集并只评估一次
- 如果你没有那么多的数据,你需要使用分层交叉验证
2.6 Cross-validation results
交叉验证是一种比重复预留法更好的评估机器学习算法的方法

- Cross‐validation really is better than repeated holdout
- It reduces the variance of the estimate
3.1 Simplicity first
There are many kinds of simple structure eg:
- One attribute does all the work
- Attribute contribute equally and independently
- A decision tree that tests a few attributes
- Calculate distance from training instances
rules.OneR:一个属性决定一切
OneR的基本原理:
- 我们选择某个属性(如Outlook)开始,然后为它的每个值建立一个分支
- 将这个分支(如Sunny)所含的最多的类(如No)作为它的分类
- 错误率是在这个分支中不属于最多分类的实例的比例
- 我们选择错误率(Total errors)最小的属性
我们建立一棵只在根结点根据某个属性分叉的树
例如天气数据集,我们将展望、温度、湿度、风速建立一组规则
Outlook有三个分类值 Sunny, Rainy, Overcast


3.2 Overfitting
过度拟合Overfitting
任何机器学习算法都有可能过度拟合训练数据
当创建的分类器过度拟合训练数据时,就很难推广到独立的测试数据
Our model doesn’t generalize well from our training data to unseen data.
This is known as overfitting, and it’s a common problem in machine learning and data science.
过拟合(overfitting)与欠拟合(underfitting)是统计学中的一组现象。过拟合是在统计模型中,由于使用的参数过多而导致模型对观测数据(训练数据)过度拟合,以至于用该模型来预测其他测试样本输出的时候与实际输出或者期望值相差很大的现象。欠拟合则刚好相反,是由于统计模型使用的参数过少,以至于得到的模型难以拟合观测数据(训练数据)的现象。
我们总是希望在机器学习训练时,机器学习模型能在新样本上很好的表现。过拟合时,通常是因为模型过于复杂,学习器把训练样本学得“太好了”,很可能把一些训练样本自身的特性当成了所有潜在样本的共性了,这样一来模型的泛化性能就下降了。欠拟合时,模型又过于简单,学习器没有很好地学到训练样本的一般性质,所以不论在训练数据还是测试数据中表现都很差。我们形象的打个比方吧,你考试复习,复习题都搞懂了,但是一到考试就不会了,那是过拟合;如果你连复习题都还没搞懂,更不用说考试了,那就是欠拟合。所以,在机器学习中,这两种现象都是需要极力避免的。

它对于训练数据非常准确,但是却很难适用于独立的测试数据。因为它规则过度(参数过多)拟合训练数据,它就很难推广到独立的测试数据——这就是一个过拟合的例子
3.3 Using probabilities
Naive Bayes: Use all the attributes
假设在决策过程中,所有属性是有平等的、独立的贡献。
独立指的是根据已知属性的值不能推测出其他属性的值。
Independence assumption is never correct!
But … often works well in practice
H: class
E: instance
Pr[E]: unknown

通过归一化让两个概率的和为1

可以看到Weka对每个实例都加了个1,这是为了防止有些实例的概率是0,从而使最终结果为0
对于零次数问题 zero-frequency-problem, Weka的最常用的解决方案是在对每个数加1
3.4 Decision trees
J48是自上而下的归纳决策树(基于信息论去选择属性)
决策树算法原理:
Top‐down: recursive divide‐and‐conquer
- Select attribute for root node
Create branch for each possible attribute value - Split instances into subsets
One for each branch extending from the node - Repeat recursively for each branch
using only instances that reach the branch - Stop
if all instances have the same class

每次选择信息增益做多的属性(你可以用很多标准来选择属性,这里使用的是信息增益)


Weka中执行J48算法

3.5 Pruning decision trees
通过剪枝,我们可能得到一个在训练数据上表现差的决策树,但是也许在独立的测试数据上会表现的好,而这正是我们想要的。

(修剪树枝图)
需要修剪的情况是:原始的未修剪的决策树过度拟合训练数据集
如何剪枝How to prune?
- Don’t continue splitting if the nodes get very small (J48 minNumObj parameter, default value 2)
- Build full tree and then work back from the leaves, applying a statistical test at each stage
(confidenceFactor parameter, default value 0.25) - Sometimes it’s good to prune an interior node, raising the subtree beneath it up one level
(subtreeRaising, default true) - Messy … complicated … not particularly illuminating
修剪后决策树的结点变少,而且预测实例的准确率会更高,所以Weka默认是修剪的
修剪方法经常会大大简化决策树,就像乳腺癌 breast-cancer 例子
修剪pruning实际上是防止过拟合的一个通用技术
一般来说,J48是一个常见的有效的数据挖掘算法
3.6 Nearest neighbor
最近邻机器学习方法(基于实例的学习方法)
这个算法只记忆训练实例,然后为了给新的实例分类,寻找训练数据集汇总与新实例最相似的实例
To classify a new instance, search training set for one that’s “most like” it
- the instances themselves represent the “knowledge”
- lazy learning: do nothing until you have to make predictions
- “Instance‐based” learning = “nearest‐neighbor” learning

(最近邻算法)
如果是名词类属性,我们需要定义不同的属性之间的差异,通常人们认为属性值不同的距离是1,属性值相同的距离是0
怎么处理有噪音的数据集?
如果遇到了分类错误的训练实例作为测试实例最邻近的实例怎么办
Nearest-neighbor —> k-nearest-neighbors
k-nearest-neighbors
– choose majority class among several neighbors (k of them)
In Weka
Lazy.IBk (instance-based learning)
在Weka中k近邻算法叫做IBk,这是一种懒惰学习方法
Investigate effect of changing k
- Glass dataset
- lazy.LBk k = 1, 5, 20
- 10-fold cross-validation
| k=1 | k=3 | k=5 | k=10 |
|---|---|---|---|
| 70.6% | 72.0% | 67.8% | 66.4% |
这应该不是一个有很多噪音的数据集,若果我们有一个充满噪音的数据,你会发现随着k的增大,准确率会提高,然后最后准确率总是会开始降低的
如果我们把k设为一个极值,接近整个数据集的大小
算出测试实例到所有训练实例的距离,并且求平均值,可以我们就可以得到这个数据集的基线准确率(可以用ZeroR验证)
4.1 Classification boundaries
显示分类算法的边界

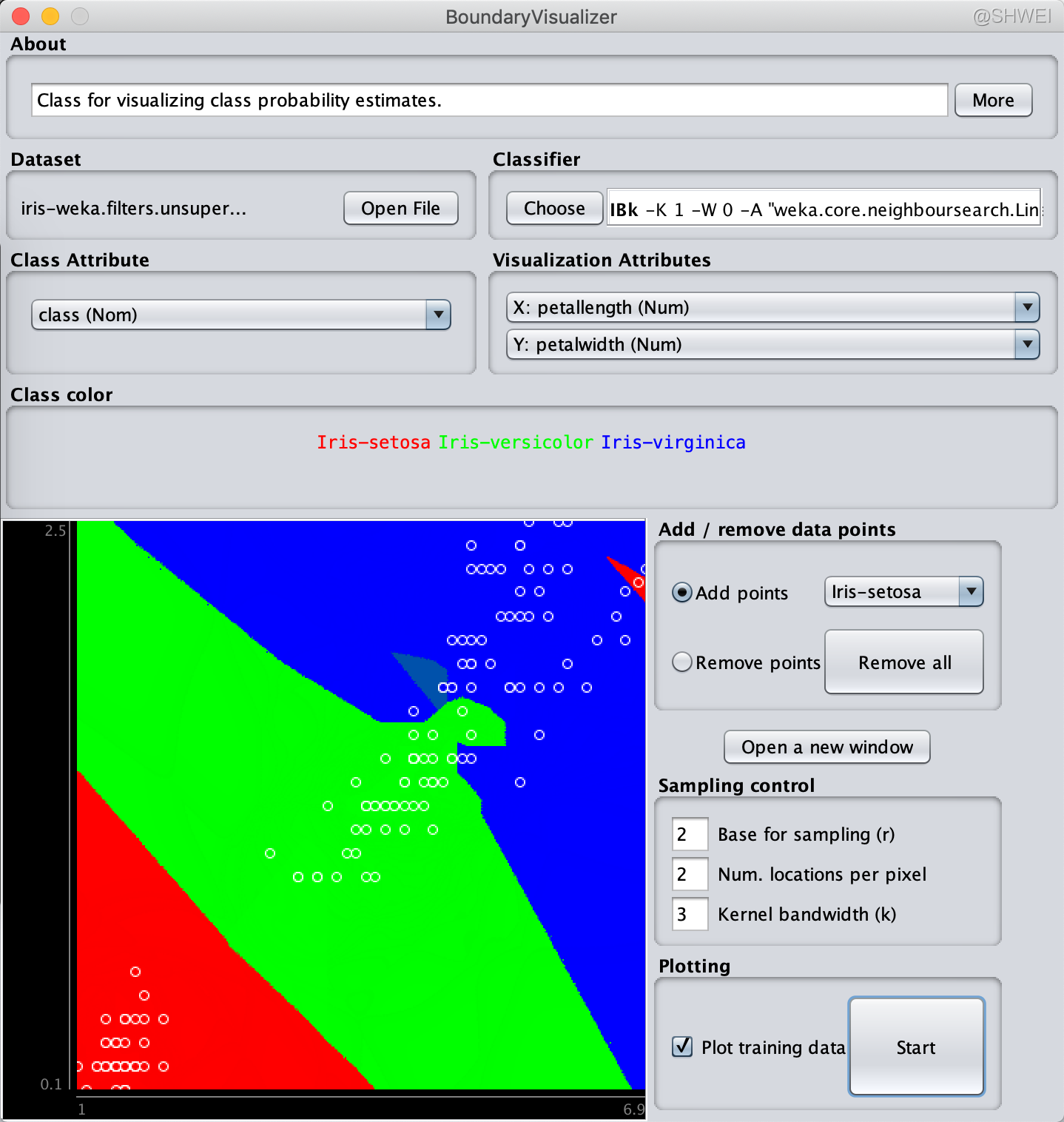
(k=1时的图例)
K-近邻算法的边界:一小段一小段组成的逐段线性分界线

(k=5时的图例)
因此我们会得到一个模糊的边界,这就是分解的概率化的描述
可视化帮助我们像机器学习法一样思考
下图是Naive Bayes的边界可视化图

(Naive Bayes边界可视化)

(J48边界可视化)
注意:这种可视化仅限数值属性和二维视图
Visualization restricted to numeric attributes, and 2D plots
4.2-4.6 Linear Regression…
之前讨论的都是预测一个名词值(分类问题),现在开始讨论预测一个数字值(回归问题)
…
5.1 The data mining process
数据挖掘的过程

整个过程是一个循环,Weka是很重要的,它是圆圈的中心,尽管它重要,但它只是你要做的事情的一小部分

最大的问题是提出合适的问题,你需要做的是回答这个问题,而不是盲目地处理数据
然后你需要收集些你能收集到的,能用数据挖掘技术帮助你回答这个问题的数据
收集数据是很难的,你可能有一个初始数据集,但是你可能需要增加一些人口数据、气候数据等,你可以上网搜索一些信息来补充你的数据集,然后你把所有这些组合起来:创建一个数据集,它包括了你认为有必要(Weka需要的)的数据
接着你需要清理数据:坏消息是现实生活中的数据总是非常杂乱,研究数据、理解数据、找出异常、确定是否提出些数据是一个漫长而痛苦的过程,这会花费一些时间
然后你需要定义一些新的特征:这是特征工程的过程,是数据挖掘能够成功的关键步骤
最后使用Weka,你可能需要重复这个循环几次,才能得到好的分类算法,然后你需要在现实世界中使用算法
Ask a question
- what do you want to know?
- “tell me something cool about the data” is not enough!
Gather data
- there’s soooo much around …
- … but … we need (expert?) classifications
- more data beats a clever algorithm
Clean the data
- real data is very mucky
Define new features
- feature engineering—the key to data mining
Deploy the result
- technical implementation
- convince your boss!
特征工程的一些过滤器:可以自定义特征或属性
(Selected) filters for feature engineering
AddExpression (MathExpression)
- Apply a math expression to existing attributes to create new one (or modify existing one)
Center (Normalize) (Standardize)
- Transform numeric attributes to have zero mean (or into a given numeric range) (or to have zero mean and unit variance)
Discretize (also supervised discretization)
- Discretize numeric attributes to have nominal values
PrincipalComponents
- Perform a principal components analysis/transformation of the data
RemoveUseless
- Remove attributes that do not vary at all, or vary too much
TimeSeriesDelta, TimeSeriesTranslate
- Replace attribute values with successive differences between this instance and the next
示例:

(自定义属性)
Weka is only a small part (unfortunately)
“may all your problems be technical ones” – old programmer’s blessing
